La Grosse Conf 2025 - Retour d'expérience de 2 ans de constructiond'une cloud data plateforme efficiente
Lors de la deuxième édition de la Grosse Conf, Théophile Molcard a partagé un retour d'expérience sur la mise en place d'une Data Platform efficace et économique. Le discours s'est basé sur un cas fictif inspiré de Transport for London, l'organisme public responsable des transports en commun à Londres.
Contexte et enjeux
L'objectif principal était de démontrer qu'il est possible de construire une plateforme de données capable de traiter d’importants volumes de données à des coûts très raisonnables.
Transport for London gère une volumétrie importante de données liées aux transports : horaires, indicateurs de qualité de service, fréquentation des lignes de bus et de métro, etc. Or, récupérer des informations précises, et a fortiori construire un flux, peut s'avérer très laborieux en raison de la dispersion des sources.
Par exemple, répondre à une question aussi simple que "Combien de métros étaient attendus sur la ligne Circle il y a quatre ans ?" peut prendre plusieurs jours si la donnée n'est pas centralisée. De plus, des démarches administratives et des délais de traitement rendent l'accès à l'information encore plus complexe.
Ainsi, la mise en place d’une Data Platform devient une nécessité pour permettre de :
- Faire des requêtes ponctuelles
- Répondre à des cas d’usage
- Construire des rapports
Mais une data platform s’inscrit également dans un contexte métier, au sein de Transport for London, l’objectif de cette plateforme est de :
- Centraliser les données et les rendre accessibles à un large public.
- Stocker et archiver les informations pour des analyses rétrospectives et des audits.
- Transformer et structurer les données pour faciliter leur exploitation.
Contraintes techniques et choix d’architecture
La plateforme doit être capable de gérer 3 To de données par mois, dans des formats variés (CSV, JSON, XML, géolocalisation…) et de mettre à jour les données sous 15 minutes. En tant qu'organisme public, Transport for London est composée d’ équipes de taille réduite et avec des budgets limités. Ces contraintes techniques et opérationnelles ne sont pas nécessairement bloquantes pour la mise en place d’une telle plateforme.
Principes directeurs
Pour répondre aux besoins de cette plateforme malgré ces contraintes nous avons choisi de mettre en place deux grands principes.
- Pragmatisme : Adopter des solutions éprouvées et peu coûteuses.
- Généricité : Privilégier des technologies standards et largement adoptées.
Architecture technique
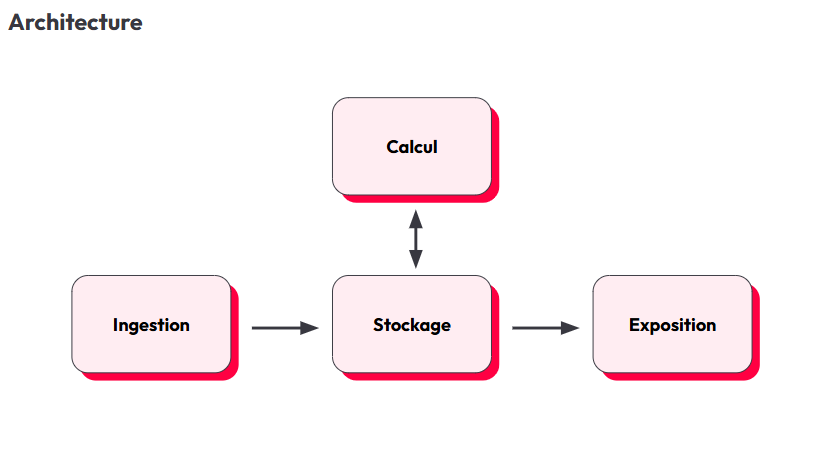
Ingestion des données : Les modes de collecte de la donnée dépendent des fournisseurs et de leur maturité technologiques. Plusieurs modes de collecte sont prévus, notamment via dépôt manuel de fichiers, API et automatisations. La logique métier est volontairement limitée à ce stade afin de réduire la complexité de l'ingestion.
Stockage : Le choix s'est porté sur le stockage objet, une solution scalable et moins coûteuse que les bases de données relationnelles classiques. Exemples : Azure Data Lake Storage, Google Cloud Storage, Amazon S3.
Calcul et traitement: Pour assurer une scalabilité optimale, les traitements sont exécutés via des fonctions serverless (Azure Functions, Google Cloud Run, AWS Lambda), qui permettent de déclencher dynamiquement des ressources selon les besoins.
Exposition des données : C’est une couche très dépendances des consommateurs
Deux modes d'accès sont proposés : des tableaux de bord et rapports BI (Power BI, Tableau) et des API ouvertes pour faciliter l'intégration dans d'autres systèmes.
Gouvernance et organisation des données
L’absence de structure inhérente avec du stockage objet impose une stratégie d’organisation de données à mettre en place. Pour cela une architecture en médaillon est utilisée, permettant d’améliorer progressivement la valeur et la qualité de la donnée. Les 4 niveaux d’organisation de la donnée sont:
- Bronze : données brutes stockées, sans aucune transformation. La donnée est difficilement consommable à ce stade.
- Sliver : Première transformations techniques (aplanissement de la données, mise en parquet, standardisation) pour rendre la donnée plus exploitable. Les données à ce stade sont facilement consommables mais difficilement interprétables d’un point de vue métier.
- Gold : Ensemble de transformations métier pour rendre les données directement exploitables.
- Platinium : données agrégées et modélisation pour des cas d’usage spécifiques,qui seront facilement ingéré dans un outil de visualisation.
Gestion de la charge et scalabilité
Comment gérer efficacement la charge de calcul ?
Avec une volumétrie de plusieurs téraoctets de données, l’enjeu principal était d’assurer un traitement rapide et scalable tout en minimisant les coûts opérationnels. La solution retenue repose sur un principe fondamental : diviser pour mieux régner.
Parallélisation des calculs
L’approche adoptée repose sur une parallélisation horizontale via des fonctions serverless. Ce modèle permet de déclencher autant de fonctions que nécessaire pour traiter les données en parallèle, garantissant ainsi une exécution rapide et efficace.
Maintenance & Évolutivité
La gestion de flux est simple, en soit, quand nous avons un entrecroisement de plusieurs flux cela peut complexifier le processus.
Afin de préserver la performance et l'évolutivité de la plateforme, trois principes fondamentaux sont appliqués :
- Idempotence : Un calcul exécuté plusieurs fois produit toujours le même résultat. On obtient le même comportement si on exécute une fonction une ou 20 fois. Un exemple concret : si vous souhaitez prendre l’ascenseur pour monter quand vous appuyer sur le bouton il arrivera une vingtaine de secondes plus tard, et si vous êtes pressé vous appuierez 20 fois sur le boutons mais l'ascenseur n’arrivera toujours qu'une vingtaine de secondes plus tard.
- Stateless: Le comportement de la fonction dépend uniquement des données d’entrée. L’état du processus est garanti par la donnée elle-même. La fonction serverless ne conserve pas d’état entre chaque exécution
- Indépendance des domaines métiers : Les différentes unités métiers ont leurs propres flux et ne partagent pas de logique, évitant ainsi les effets de bord.
Bénéfices et enseignements
- Maintenance facilitée : Pas de point unique de défaillance, relance facile des traitements en cas d'erreur.
- Réduction des opérations manuelles : Automatisation poussée des traitements.
- Amélioration de l'expérience développeur : Un code centralisé et un système robuste permettant un développement rapide de nouveaux cas d'usage.
En résumé, ce retour d'expérience prouve qu'il est tout à fait possible de concevoir une Data Platform performante, économique et scalable. En restant pragmatique dans les choix technologiques et en appliquant les principes d'architecture sans état et idempotents, il devient possible d'optimiser la gestion des données tout en répondant efficacement aux besoins des utilisateurs. Un bel exemple de stratégie orientée vers l'efficacité et la rationalisation des coûts !