DAT4 : une machine à voyager dans le temps pour l'ingénieur data
DAT4 : une machine à voyager dans le temps pour l'ingénieur data
Note au lecteur : Le framework de Data Factory (DAT4) abordé dans cet article est un outil interne développé chez l'un de nos clients (la Direction Générale de l’Aviation Civile - DGAC) et n'est pas accessible publiquement. Si le code reste privé, les concepts architecturaux qui le gouvernent sont, eux, universels et méritent d'être partagés. En outre, cette collaboration illustre parfaitement la vision et les convictions qu'OCTO défend au quotidien en matière d'ingénierie de la donnée.
Une question pour les ingénieurs qui ont des pipelines de données en production : vous est-il déjà arrivé d’arriver au bureau, le lundi matin, avec cette légère boule au ventre ? Cette anxiété qui vous fait demander si vos traitements "batch" du week-end sont bien passés...
Normalement, tout devrait être fluide. Mais la réalité est souvent moins clémente : un serveur capricieux a envoyé un fichier avec une heure de retard, et tout le château de cartes s'est effondré. Un job n'a pas pu se lancer, bloquant le suivant, puis le suivant. Pire : certains se sont lancés "à vide", d’autres ont produit des données partielles, invisibles au premier coup d'œil.
Résultat ? Vous passez votre journée à démêler un plat de spaghettis. Il faut identifier ce qui manque, supprimer manuellement les partitions corrompues et relancer les traitements dans le bon ordre. Parfois, c’est tellement complexe de faire le tri que l’on finit par choisir la "solution ultime" : on supprime l'intégralité de la table pour tout relancer depuis le début (encore faut-il que les fichiers sources n'aient pas été purgés !). Pendant ce temps, les plaintes des utilisateurs s'accumulent. Tout ça à cause d'un décalage d'une heure.
La solution : le voyage dans le temps
Pour prévenir ce scénario catastrophe, il nous faudrait un super-pouvoir : la capacité de remonter dans le temps. Si vous aviez pu être là au bon moment, vous auriez arrêté les traitements pour attendre l’arrivée du fameux fichier. Le résultat aurait été parfait, et votre lundi aurait pu être consacré à créer de nouvelles features plutôt qu'à de la maintenance d'urgence.
Puisque remonter le temps est impossible, il faut tricher : il faut briser le lien entre l'heure de la montre (Processing Time) et l'heure de la donnée (Event Time). L'idée est de contrôler parfaitement les conditions de traitement pour aboutir à un système déterministe. Que je lance le job aujourd’hui, demain ou dix fois de suite, le résultat doit être identique, comme si le retard n’avait jamais existé.
Le socle théorique : l’idempotence
Cette propriété s’appelle l’idempotence. D'un point de vue mathématique, une fonction est idempotente si l'appliquer plusieurs fois donne le même résultat qu'une seule fois. En langage mathématique :
f(f(x)) = f(x)
En mathématiques pures, l'idempotence est presque anecdotique. Mais l’informatique fait face à un problème que les mathématiciens n’ont pas : l'imprévisibilité du monde réel. Nos fonctions s'exécutent sur des réseaux qui coupent et des serveurs qui crashent. Une exécution peut réussir, échouer à moitié, ou rester bloquée.
C'est là que l'idempotence vient à la rescousse. Puisqu'on a des effets de bord obligatoires (lire ou écrire dans une base), l'idempotence évite qu'ils ne fassent des dégâts si on les répète (comme créer des doublons). L’idempotence m'autorise à relancer ma fonction autant de fois que je veux, jusqu’à ce qu’elle fonctionne. C’est particulièrement vital en Data Engineering où les frameworks distribués (comme Spark ou Dataflow) "tuent" et relancent volontairement des processus par design.
| ⚠️ Attention : Fonction idempotente ≠ Pipeline idempotent Attention au piège : l'idempotence est une propriété relative au périmètre que l'on observe. Une fonction parfaitement idempotente ne garantit pas un pipeline idempotent. Imaginons un pipeline qui applique une fonction de nettoyage f(x) sur une table source. Si la base de données est modifiée par un processus tiers entre deux exécutions du pipeline, les données d'entrée (x) ont changé. Votre fonction s'exécutera correctement, mais à l'échelle du pipeline, le résultat final sera différent lors du second passage. L'idempotence globale est brisée par la mutation de l'état externe. Le risque principal de cette perte d'idempotence est son caractère furtif : elle surgit souvent là où on s'y attend le moins. Lors d'une précédente mission, notre pipeline a silencieusement perdu son idempotence pour une simple raison architecturale : les fichiers de la Landing Zone étaient déplacés vers un dossier d'archive après la validation des premières étapes. La fonction était intacte, mais le contexte initial d'exécution, lui, avait disparu. |
|---|
La Métamorphose : Du Chronomètre au Bibliothécaire
Pour garantir cette idempotence globale et offrir ce confort aux développeurs, l'orchestrateur doit opérer une véritable métamorphose. Il ne peut plus se contenter d'être un simple exécutant obéissant à une horloge ; il doit devenir un gestionnaire d'état intelligent dont la première action est de découper le temps.
C'est exactement la philosophie de DAT4, le framework interne développé par la DGAC. Avec cet outil, le concept fondamental est la partition stricte de l'heure de la donnée (Event Time). Le flux continu de la réalité est découpé en fenêtres temporelles immuables (Windows), allant de la minute à l'année.
Tout passe ensuite par un fichier de configuration qui agit comme un véritable "contrat". Même si le framework est toujours réveillé à intervalles réguliers par un ordonnanceur classique (scheduler), sa logique s'émancipe de l'horloge. Le contrat n'est plus la consigne aveugle : « Calcule les données d'hier parce qu'il est minuit », mais plutôt : « À chaque réveil, balaye l'ensemble des fenêtres temporelles, et pour chacune d'elles, vérifie si les ingrédients sont réunis pour préparer le plat fini ».
Pour orchestrer ce contrat, le framework s'appuie sur deux piliers :
- Le Catalogue de Données : qui recense l’ensemble des sources de manière agnostique grâce à des descripteurs.
- La Table de Monitoring : un registre qui trace méticuleusement chaque fragment de donnée (occurrence) en stock et lui associe un timestamp dans le flot des événements. Par exemple, une occurrence enregistrant les vols quotidiens pourra être enregistrée comme un couple (flights_over_france, 2026-05-11).
Comme chaque input d’un traitement est l’output d’un traitement précédent (en dehors du premier traitement d’une pipeline qui est un traitement particulier), la table de monitoring enregistre simplement la date de la window comme timestamp de ses outputs.
Ainsi, si j’ai un traitement hebdomadaire dont l’objectif est de créer un output chaque semaine, ma table de monitoring associera à cet output la date du traitement.
Remarque : afin de gérer les problèmes de synchronisation entre window et inputs de période différentes, les descriptors des inputs utilisés portent aussi l’information de périodicité ce qui permet pour un traitement journalier utilisant (parmi d’autres) des données hebdomadaires de gérer cela d’une manière intelligente (il duplique les sources dont la fréquence est inférieure à celle de la window et regroupe celles dont la fréquence est supérieure).
Mais si on met de côté ces détails, l’important est de comprendre qu’avec ce système de monitoring et de data catalog, le système ne regarde plus l'heure qu'il est. Il scrute chaque partition isolément et interroge son registre : "Pour la fenêtre spécifique du 11 mai, les conditions sont-elles réunies ?".
Le Cerveau en Action : calcul des “fenêtres”
C'est ici qu'intervient le moteur décisionnel du framework. Une fonction centrale (get_job_windows) va croiser en temps réel le contrat du traitement défini par le développeur avec l'état physique décrit dans la table de monitoring.
Les inputs d'un contrat peuvent être de différentes natures :
- Un Delta : la différence entre un état précédent et courant (les nouveautés).
- Un Référentiel : un état complet (snapshot) qui possède une période de validité et survit d'une fenêtre à l'autre jusqu'à être écrasé.
- Obligatoire ou non : indépendamment d’être un Delta ou un Référentiel, on peut se demander si la donnée bloque l'exécution si elle est absente ?
Comprendre le calcul avec un cas concret
Imaginons un job quotidien ayant besoin de trois entrées (Un Delta Obligatoire, un Delta Optionnel, un Référentiel Obligatoire ayant une période de validité [01/01/2026 → 31/01/2026]) pour produire une Sortie. Le tableau ci-dessous illustre comment get_job_windows prend sa décision pour différentes fenêtres temporelles pour un traitement dont les windows ont été configurés à la maille journalière :
| Fenêtre (Window) | Input 1 : Delta (Obligatoire) | Input 2 : Delta (Optionnel) | Input 3 : Référentiel (Obligatoire) | Output déjà existant ? | Décision du Framework |
|---|---|---|---|---|---|
| Window 1**:** 01/01/2026 | ✅ Présent | ❌ Absent | ❌ Absent | ❌ Non | 🛑 Ignoré (Référentiel manquant) |
| Window 2: 02/01/2026 | ✅ Présent | ✅ Présent | ✅ Présent | ✅ Oui | ⏭️ Passé (Déjà calculé) |
| Window 3: 03/01/2026 | ❌ Absent | ✅ Présent | ✅ Présent | ❌ Non | 🛑 Ignoré (Delta obligatoire manquant) |
| Window 4: 04/01/2026 | ✅ Présent | ❌ Absent | ✅ Présent | ❌ Non | 🚀 EXÉCUTION |
| ... | |||||
| Window 8 08/02/2026 | ✅ Présent | ✅ Présent | ⚠️ Validité expirée | ❌ Non | 🛑 Ignoré (Validité du réf dépassée) |
On voit par exemple que la Window 4 s'exécute car les inputs obligatoires sont là, même si le delta optionnel manque. À l'inverse, la Window 3 est bloquée pour protéger le système.
Illustrons la puissance de l'approche par trois cas concrets
1. Le casse-tête des données en retard (Late Data)
Imaginons que les données du "11 mai" (Event Time) n'arrivent sur les serveurs qu'en fin de journée suite à un incident. Avec une approche classique, le traitement de midi (Processing Time) qui utilise ces données plante. Avec l'approche DAT4, le framework constate à midi que la fenêtre du "11 mai" est incomplète et… ne fait simplement rien (il peut tout au plus fournir un log de warning). Le lendemain, il "voit" que la donnée est là. Il exécute alors proprement la fenêtre du 11 mai, puis celle du 12 mai dans la foulée. L'ordre logique de la donnée a vaincu le chaos de l'horloge.
2. La reprise d’historique (Backfill) sans sueur
Tout ingénieur data redoute la fameuse demande : "On a changé une règle de gestion, il faut recalculer les trois derniers mois". Dans un système classique, cela implique souvent des scripts de nettoyage manuels risqués.
Ici, tant qu'il n'y a pas de dépendances strictes entre les sorties (outputs), le backfill devient trivial. Il suffit de forcer le framework à ignorer (ou de supprimer) les métadonnées de statut des fenêtres concernées. Dès lors, le système redevient "amnésique" sur cette période et va naturellement recalculer toutes les fenêtres passées, exactement avec les mêmes données d'entrée valides à ce moment-là. Une opération de maintenance majeure se transforme en une simple commande d'effacement de journal.
3. La baisse de la charge cognitive (Window vs. File Tracking)
L'un des plus grands bénéfices de cette architecture est son ergonomie pour les développeurs. La plupart des outils d'ingénierie modernes (comme l'Auto Loader de Databricks) gèrent l'état des flux en traçant techniquement les fichiers ingérés (via des bases internes de type RocksDB). Si le système est performant, il est illisible pour un humain : en cas de problème, aller fouiller dans un état interne listant des milliers de chemins de fichiers UUID est un cauchemar.
À l'inverse, raisonner en Windows est sémantique et naturel. Un humain comprend immédiatement le concept de "fenêtre du 11 mai de 14h à 15h", alors qu'il a du mal à conceptualiser "les 412 fichiers générés entre 14h15 et 14h53". En alignant la logique d'exécution sur le temps métier, l'investigation et la réflexion sur les dépendances deviennent infiniment plus intuitives.
Quand le Batch rencontre le Streaming
Dans le cadre de la reprise de DAT4, nous avons vécu une expérience typique du Domain-Driven Design (DDD). Au départ, les concepteurs faisaient du fenêtrage sans le nommer, comme Monsieur Jourdain faisait de la prose. C’est évidemment un premier pas important mais en DDD on a l’habitude de dire que ce que l'on nomme pas (non visible) n'appartient pas à nos modèles mentaux.
En qualifiant cette architecture de "Window-aware batch system", nous avons fait un pont inattendu avec l'ouvrage de référence Streaming Systems. Soudain, des concepts nés pour le temps réel devenaient des solutions évidentes pour nos problèmes batch. C'est tout l'intérêt du "langage ubiquitaire" : en rendant l’implicite explicite, on prend mieux conscience des choses, et finalement on implémente ou fait évoluer le système plus facilement.

L’ouvrage Streaming Systems (2018) dédié aux systèmes “temps réel” pourrait-il aussi aider à gérer le batch ?
L'exemple des Sliding Windows
La théorie est belle, mais la pratique tranche. Si l’ouvrage Streaming Systems propose notamment les Sliding Windows (fenêtres glissantes se chevauchant), y a-t-il un intérêt pour du batch ? La réponse est oui et il est venu assez naturellement pour gérer un problème auquel nous étions déjà confrontés : la gestion des fuseaux horaires. Nos sources sont en UTC, mais le métier exige le fuseau horaire de Paris (Europe/Paris, UTC+1/+2). Constituer une "journée" parisienne nécessite de récupérer les données de la fin de journée UTC de la veille. Faire cela avec des fenêtres fixes génère un plat de spaghettis logique. En définissant une fenêtre glissante sur deux jours, chaque exécution accède nativement aux données de la veille et du jour J. Le code devient trivial, lisible, et l'ingénieur peut se concentrer sur la valeur métier.
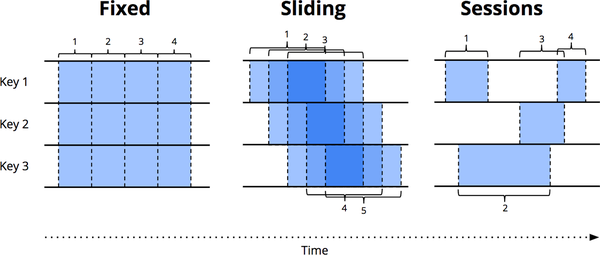
Le principe des fixed versus sliding présenté tel que présenté par Streaming Systems.
Ce que DAT4 nous apprend : Les 3 grands piliers de la Data
Au-delà de ses spécificités, ce framework rejoint la quête universelle pour garantir les fondations de l'ingénierie data, qui reposent sur trois propriétés quasi-mathématiques :
| Propriété | Définition | Risque en cas d'absence |
|---|---|---|
| 1. Idempotence | f(x) donne toujours y, peu importe le nombre d'essais. | Le Double Comptage : Ventes doublées après un crash réseau. |
| 2. Immuabilité | On ne "mute" jamais la donnée (Pas de UPDATE), on supprime ou on ajoute. | Perte de l'Histoire : Impossible de reproduire un bug de la veille (Time-Travel impossible). |
| 3. Complétude | Capacité du système à affirmer que toutes les données sont arrivées (ex: via Watermarks). | La Donnée Fantôme : Le fichier arrivé 5 min trop tard n'est jamais traité. |
| (Note sur DAT4 : S'il excelle sur l'idempotence et la séparation Event/Processing Time, il lui manque encore une politique de rétention versionnée pour atteindre la véritable immuabilité du Time-Travel, et l'implémentation de Watermarks complexes pour affiner sa complétude. L'architecture parfaite est un chemin, pas une destination !) |
Conclusion : Une vision de l'ingénierie selon OCTO
Ce travail sur DAT4 illustre parfaitement notre conviction chez OCTO : l'intelligence collective a une profondeur qu'on ne soupçonne pas. Les applications de nos clients, qu'ils hésitent parfois à “mettre à la poubelle”, recèlent souvent des trésors d'ingéniosité.
Plutôt que de briller par des buzzwords ou des solutions one-fits-all, nous préférons mettre notre culture de "crafteux" et d’excellence au service de l'existant :
- Valoriser l'existant : Comprendre l'intention derrière le code, même si le temps a manqué pour le rendre "propre".
- Refactorer plutôt que réécrire : Apporter des principes de software design qui ont fait leur preuve (Langage ubiquitaire, SOLID, Supple Design…) pour transformer une application legacy en un outil évolutif.
- Transversalité : Infuser des méthodes du Web ou du Produit dans le monde de la Data.
Remettre en état un logiciel en suivant des principes sains apporte souvent bien plus de valeur que de repartir de zéro. C'est là que réside le véritable savoir-faire : transformer la "prose" de nos clients en une architecture élégante et pérenne (voir à ce propos la série d’articles de Bruno Boucard “Moderniser un legacy conséquent sans y perdre ses plumes”).