Maîtriser le RAG - Retrieval Augmented Generation
Le 16 janvier, je vous ai parlé de RAG où comment construire rapidement un agent conversationnel à jour, comprenant ma donnée, mon vocabulaire d’entreprise, et qui peut interagir avec des données sensibles et stratégiques en entreprise. Une vidéo que vous pouvez retrouver sur le youtube d’Octo Je vous résume ce qu’il fallait retenir de ce comptoir 😉
Une Tendance
Ce RAG qui apparaît partout, dans les GPTs d’OpenAI, dans les différentes fonctionnalités de Google Bard (par exemple la discussion avec les vidéos youtube) est une tendance clair de la vague IA génératives qui déferle dans les entreprises : Même le gartner l’a mis dans sa fameuse “hype cycle” de l’IA générative de 2023.
Techniquement
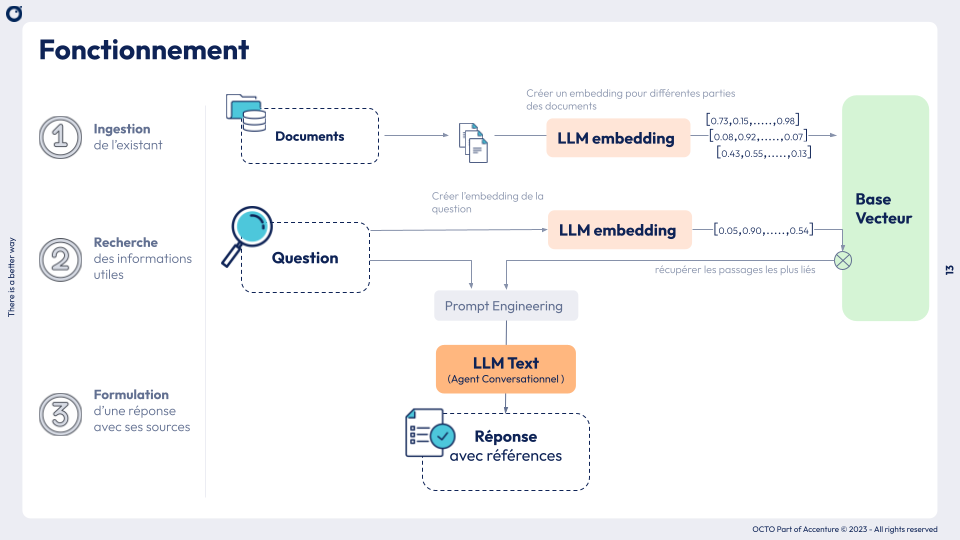
L’idée principale du RAG (Retrieval Augmented Generation) est de connecter des données, des documents avec des grands modèles de langages ( appelé LLM Text ici). La phase de Recherche (ou RETRIEVER) est souvent construite en utilisant la puissance de la représentation vectorielle : Les passages des documents sont sauvegardés dans une base vecteur (une ligne = un passage). La partie formulation (ou GENERATION) va utiliser la puissance de ce LLM text (par exemple chatGPT, mistral, etc..) avec une petite touche de “prompt engineering” :
””” Rôle (exemple : tu es un assistant qui répond …à partir des références suivantes.)___ Les Références utiles ( exemple : le contenu du document X )___ La Question ( exemple: à la question suivante…)”””
L’évaluation d’un RAG reste la priorité !
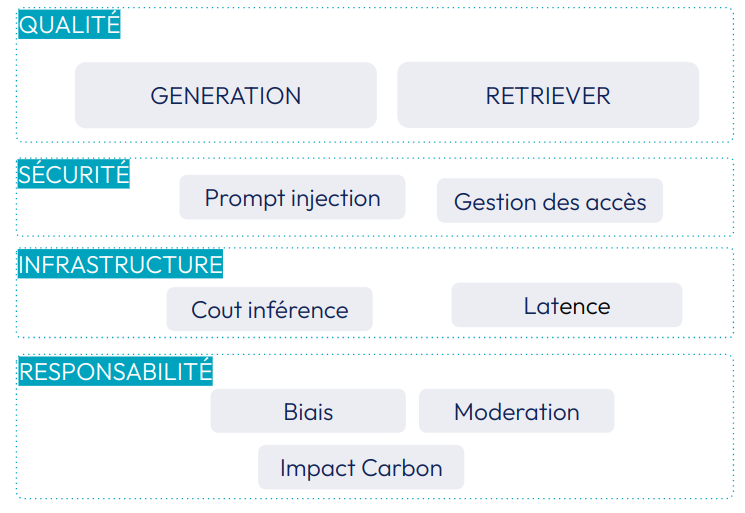
La qualité d’un RAG n’est pas simple à évaluer et doit prendre en compte les deux composants que sont le RETRIEVER et la GENERATION. Certains frameworks émergent pour aider à évaluer ces différentes particularités : RAGAS , trulens.
Une évaluation qui ne se limite pas seulement à la qualité des prédictions. Il faut également prendre en compte d’autres axes qui selon le cas d’usage peut être tout aussi important.
Passer d’un RAG simple à un RAG avancé, voire modulaire
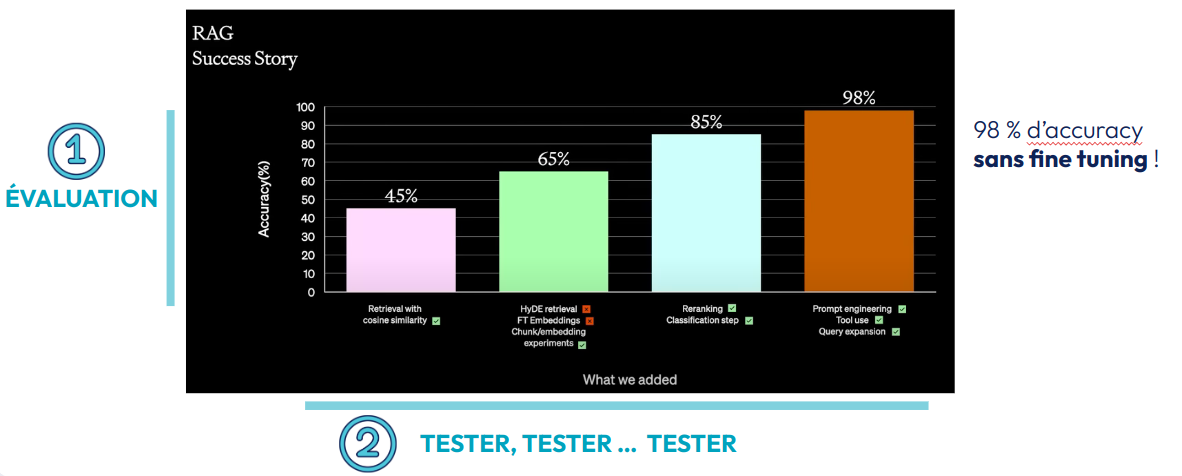
De nombreuses méthodes existent pour améliorer son RAG. La “Success Story” (fig) d’OpenAI montre clairement que vous devez travailler itérativement et tenter d’augmenter vos résultats ( fonction de votre démarche d’évaluation). Vous pouvez retrouver quelques astuces possibles pour améliorer votre RAG sur le blog de langchain ou sur ce RAG-survey
Garder en tête le coût !
Le coût d’un projet RAG à l’usage résident principalement dans l’usage du LLM text : Il représente très rapidement 99% du coût du RUN. Ce coût peut être financier, pour rappel, celui-ci dépend du nombre de tokens en entrée et en sortie. Vous pouvez retrouver les prix à jour des différents fournisseurs de modèles d’IA génératives sur cette feuille, et si vous voulez tester une tokenization vous retrouvez celle de GPT3.5 et GPT4 sur ce site.
Le coût environnemental d’un projet RAG est fortement corrélé au coût financier. Pour l’usage d’un LLM text externe c’est la seule approximation possible (quelques études essaient d’estimer le coût chatGPT à l’usage…). Pour ceux que vous hébergez nous vous conseillons d’utiliser un outils comme CodeCarbon pour mesurer la consommation de votre solution sur vos machines que vous multipliez par l’empreinte carbone du kWh où sont localisées les machines (par exemple 50 g.CO2eq/kWh en France source RTE).
Demain, un RAG présent mais différent !
Le RAG de demain verra sa méthodologie modifiée par plusieurs facteurs. Les “LLM text” s’améliorent : le Retriever peut être moins bon par exemple. La taille du contexte de ces LLM Text continue d’augmenter ( ~128k GPT4 , 32k Mixtral = 10-30 fois plus en un an). Les coûts financiers (ainsi que ceux environnementaux) se réduisent fortement ! L’architecture sera également modifiée, car l’émergence des SLM pousse à des modèles qui tourneront demain en Local!
Derrière ces modifications à venir, l’idée principale devrait rester : Exposer ses données et des services à un agent IA devient le futur de nos systèmes d’information !