Llama.cpp, SGLang, vLLM : quel framework d'inférence LLM choisir pour votre assistant de code ?
Introduction
Depuis début 2025, les assistants de code sont de plus en plus présents et utilisés dans le quotidien des développeurs. Tous les acteurs du secteur ont lancé leurs propres outils : en premier lieu Microsoft avec Github Copilot, que chacun peut intégrer à son IDE. Ensuite OpenAI et Anthropic ont sorti les assistants des IDEs avec une CLI directement dans le terminal (respectivement Codex et Claude Code).
Nous avons observé depuis décembre 2025, une accélération [6] de l’adoption des assistants de code, avec la publication d’Opus 4.5 fin novembre 2025 [1] qui s’est démarqué par rapport aux autres modèles sur les benchmarks spécialisés.
Cependant, que cela soit Claude Code ou Codex, ces outils reposent sur des APIs propriétaires. Chaque requête envoyée transporte du code source, des noms de fichiers, des architectures internes, parfois des secrets d’infrastructure. Les mêmes questions que nous posions dans notre précédent article [2] se posent ici avec encore plus d’acuité : où transitent ces données ? Qui y accède ? Sont-elles utilisées pour l’entraînement de futurs modèles ? Pour les organisations soumises à des exigences de conformité (RGPD, SecNumCloud, HDS, PCI-DSS), ou simplement soucieuses de leur propriété intellectuelle, l’utilisation d’APIs externes pour de l’assistance de code pose un risque qu’il est difficile d’ignorer.
Auto-héberger ses propres modèles d’assistance de code est une réponse à ces problématiques. Et ce qui était inaccessible il y a encore deux ans devient réaliste :
- des modèles open weight performants spécialisés dans le code émergent (Devstral, Qwen-Coder-Next, Kimi-K2.6).
- des moteurs d’inférence open source ont considérablement mûri.
- des GPUs à moindre coût accessibles via des fournisseurs cloud.
Dans la suite de l’article, nous vous présentons une architecture et son étude empirique pour évaluer sa performance. Celle-ci a été déployée sur trois machines virtuelles (VMs) équipées de GPUs NVIDIA distincts : un L40S-1-48G hébergeant llama.cpp, et deux H100-1-80G faisant tourner respectivement vLLM et SGLang.
Les GPUs L40S/H100 se positionnent dans un segment haut de gamme de ce que l’on peut trouver dans les datacenters. Ils sont optimisés pour l’inférence et l'entraînement de modèle. Le choix de ce type de GPU est motivé par notre souhait de mener nos expérimentations avec une capacité à pouvoir faire des montées en charge simulant une utilisation réelle par un nombre d'utilisateurs conséquent.
Les trois VMs servent un même modèle de Mistral : Devstral-Small-2-24B. L’objectif de cet article est de faire la comparaison des trois moteurs d’inférence, ce qui explique que nous avons fixé la variable “modèle” en en choisissant qu’un. À la seule différence que Llama.cpp a besoin des poids du modèle au format GGUF[3] pour fonctionner, Unsloth s'occupe de cette partie pour Mistral.
Nous avons fait le choix de pousser cette architecture au-delà du seul cadre expérimental, afin qu’elle soit opérationnelle pour des utilisateurs externes et qu’elle puisse être interrogée à travers des clients d’assistance de code comme Cline, OpenCode, et d’autres. Dans cette optique nous avons exposé une VM à travers une gateway qui concentre plusieurs services :
- un serveur LiteLLM permettant d’orchestrer le choix des modèles, de centraliser l’authentification et de gérer le cycle de vie des clés API.
- un service de monitoring avec Grafana et Prometheus pour collecter les métriques d’utilisation et de performance de chaque moteur d’inférence.
- un reverse proxy Nginx permettant d’exposer notre gateway sous un nom de domaine.
Les VMs faisant tourner les moteurs d'inférence ne sont accessibles que via la gateway; un VPC a été ajouté au-dessus pour limiter les requêtes.
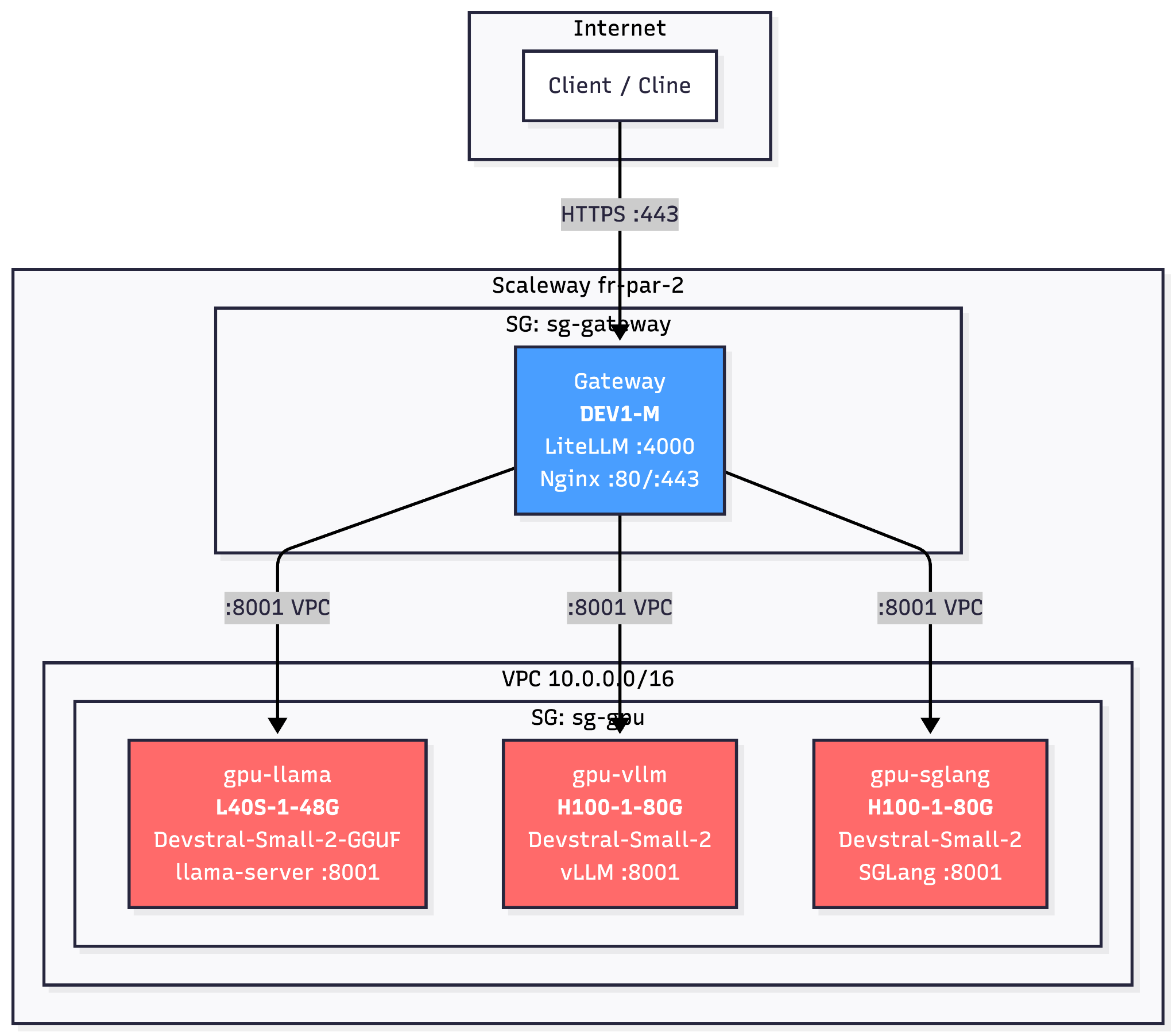
Figure 1.1. Architecture avec un service de gateway et trois GPUs hébergeant chacun un Devstral-Small-2-24B. La gateway tourne sur un DEV1-M, deux des GPUs sont des H100s et le dernier un L40S.
Un rappel nécessaire : le KV cache, facteur limitant de l’inférence
Avant de présenter ces moteurs, il nous paraît utile de rappeler un concept central qui conditionne toute la suite de cet article : le KV cache. C’est lui qui constitue le facteur limitant de l’inférence, et c’est précisément lui qui différencie les trois moteurs d’inférence que nous allons comparer.
Un LLM génère du texte token par token. À chaque étape, le mécanisme d’attention du transformer transforme chaque token en trois vecteurs : une requête (Query, Q), une clé (Key, K) et une valeur (Value, V). Pour produire le token suivant, le modèle n’a pas besoin que du vecteur Q du dernier token, mais des vecteurs K et V de tous les tokens précédents. Le problème : pour générer le token 51, les vecteurs K et V des tokens 1 à 49 sont recalculés alors qu’ils n’ont pas changé ; c’est du travail redondant.
La solution tient dans le KV cache : au lieu de recalculer tous les vecteurs K et V à chaque étape, on les stocke en mémoire. Pour chaque nouveau token, le moteur ne calcule que les vecteurs Q, K et V de ce token, ajoute les nouveaux K et V au cache, puis exécute l’attention en utilisant le Q du nouveau token contre l’ensemble des K et V en cache. Les projections coûteuses ne sont faites qu’une seule fois par token, pas à chaque pas de génération.
Cela explique aussi pourquoi le premier token est toujours plus lent. À la réception du prompt, le modèle traite l’intégralité de l’entrée pour remplir le KV cache : c’est le prefill, qui détermine le Time to First Token (TTFT). Ensuite, chaque token suivant ne nécessite qu’un passage avec un seul token : c’est le decode, qui détermine le Time per Output Token (TPOT).
Trois moteurs, trois philosophies
Trois moteurs d’inférence open source se distinguent aujourd’hui pour servir ces modèles : llama.cpp, vLLM et SGLang. Ils ne répondent pas aux mêmes contraintes et ne ciblent pas les mêmes usages.
llama.cpp est un projet C/C++ pour l’inférence sur ressources limitées. Il utilise le format de quantization GGUF [3] qui compresse les poids du modèle de 16 bits à 4-5 bits : Devstral Small 2, un modèle de 24B passe de ~26 Go à ~15 Go. En revanche, il ne dispose pas de mécanismes avancés de gestion du KV cache pour la concurrence.
vLLM [4] a introduit PagedAttention en 2023. Sans cette optimisation, le moteur alloue un bloc contigu de mémoire pour le KV cache de chaque requête, dimensionné pour la longueur maximale du contexte, ce qui entraîne un gaspillage de la mémoire inutilisée. PagedAttention s’inspire de la pagination mémoire des systèmes d’exploitation : le KV cache est découpé en pages de 16 tokens, allouées à la demande et dispersées en mémoire. Couplé au continuous batching - qui insère de nouvelles requêtes dans un batch en cours sans attendre - vLLM excelle pour les accès concurrents.
SGLang [5] va plus loin avec RadixAttention. Dans un contexte d’assistance de code, de nombreuses requêtes partagent un même préfixe (system prompt, historique de conversation). Avec vLLM, le KV cache de ce préfixe est recalculé à chaque requête. SGLang le stocke dans un arbre radix et le réutilise automatiquement. Si 10 développeurs utilisent le même system prompt, SGLang calcule ce prefill une seule fois au lieu de dix.
Un outil d'évaluation dédié : llm-grill
Après avoir monté cette architecture nous avons travaillés sur la partie évaluation des différents moteurs. Pour cela, nous avons développé notre propre outil que l'on a appelé llm-grill. Le principe est assez simple, un fichier YAML (figure 1.2) permet de définir différents scénarios d’évaluation en spécifiant :
- des backends ciblant nos différentes VMs sur lesquels notre évaluation va être lancée.
- des modèles disponibles dans un ou plusieurs backend.
- des conversations simulant une discussion entre un utilisateur et un assistant de code.
- des cibles liant backends et conversations pour définir les scénarios d’évaluation.
Différents paramètres communs permettent par ailleurs d’affiner les besoins des scénarios : simulation d'une montée en charge progressive, nombre d'itérations par scénario pour garantir la stabilité statistique des résultats, etc.
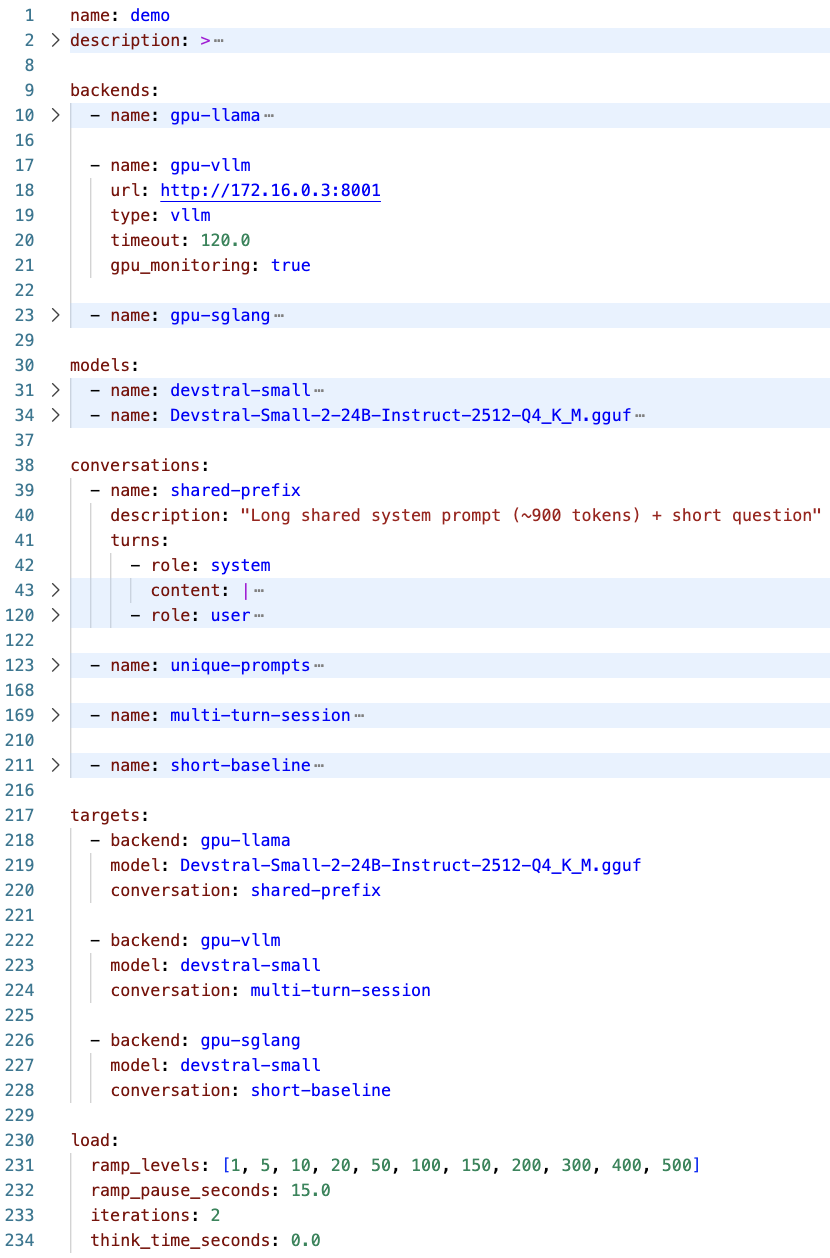
Figure 1.2 - exemple de fichier .yaml utilisé dans llm-grill décrivant des scénarios de tests et une montée en charge sur différents backends.
Objectifs et hypothèses de l’étude
Dans notre précédent article [2], nous avions évalué une architecture vLLM sur des GPUs T4 d’entrée de gamme et noté qu’une comparaison poussée entre vLLM et SGLang restait à faire. C’est l’objet de cet article. En montant en gamme sur du matériel H100 et L40S, et en confrontant trois moteurs sur le même modèle, notre objectif est de valider les hypothèses suivantes :
- llama.cpp est adapté à une équipe réduite (2 à 10 utilisateurs) avec un budget limité.
- vLLM est capable de gérer une équipe moyenne en accès concurrents (20 à 100 utilisateurs).
- SGLang surpasse vLLM sur les workloads conversationnels grâce à la réutilisation du KV cache (RadixAttention).
Expérimentations
Scénarios d'évaluation
Chaque scénario est conçu pour solliciter un mécanisme d'optimisation précis de l'un des moteurs, et correspond à un cas d'usage réel d'un assistant de code. L'ensemble couvre les trois hypothèses posées en introduction.
| Scénario | Prompt | Cas d'usage réel | Mécanisme testé |
|---|---|---|---|
| shared-prefix | System prompt de ~1000 tokens + question courte | Code review avec guidelines projet ou skills partagés dans une équipe | RadixAttention (SGLang) vs Automatic Prefix Caching (vLLM) |
| multi-turn-session | System prompt de ~450 tokens + 3 tours utilisateur | Debug itératif, session stateful avec un agent | Réutilisation du KV cache entre tours successifs |
| unique-prompts | User prompt de ~470 tokens, préfixe unique par requête | Investigation one-shot, question ponctuelle sans contexte partagé | Neutre (pas de cache exploitable) |
| short-baseline | User prompt de ~20 tokens, single-turn | Auto-complétion courte, ping, snippet simple | Neutre ; référence pour normaliser |
Table 1.1. Les quatre scénarios d'évaluation et leur lien avec les hypothèses.
Métriques
Dans cet article nous avons décidé de mettre en avant quatre métriques qui permettent de distinguer l'étape de prefill de celle de decode. Tout de fois, llm-grill collecte une quinzaine de métriques différentes (latences, débit, utilisation GPU, VRAM, puissance consommée) qui sont toutes disponibles dans les fichiers de résultats et peuvent être analysées pour des insights complémentaires.
| Métrique | Définition | Étape mesurée |
|---|---|---|
| TTFT (Time to First Token) | Délai entre l'envoi de la requête et la réception du premier token | prefill |
| TPOT (Time per Output Token) | Temps moyen entre deux tokens successifs | decode |
| Tokens/s | Débit de génération | decode |
| E2E (End-to-End Latency) | Latence totale perçue par l'utilisateur | prefill + decode |
Table 1.2. Métriques mesurées grâce à llm-grill et interprétation en regard des étapes d'inférence.
Ces quatres métriques sont complémentaires pour évaluer la fluidité d'interaction avec un LLM. Le TTFT est crucial pour les scénarios interactifs où la réactivité du premier token conditionne l'expérience utilisateur. Le TPOT et le débit de tokens sont plus pertinents pour les réponses longues, où la vitesse de génération successive impacte la fluidité. Enfin, la latence end-to-end (E2E) est la métrique globale qui intègre tous les aspects de performance perçue. Généralement il est reconnu que le seuil de tolérance d'un utilisateur se situe au-dessus de quelques secondes.
Protocole de mesure
- Montée en charge : paliers de 1, 5, 10, 20, 50, 100, 150 puis 200 utilisateurs concurrents, avec une pause de 30 secondes entre paliers pour laisser le système se stabiliser.
- Itérations : 5 itérations par palier pour garantir la stabilité des mesures et lisser les fluctuations du scheduler.
- Think time : 0.5 s entre requêtes d'un même utilisateur simulé pour décorréler les bursts.
- Agrégation : médiane (p50) sur l'ensemble des requêtes réussies d'un palier. La médiane est préférée à la moyenne pour sa robustesse aux valeurs aberrantes inhérentes à un scheduler partagé.
- Échantillon par palier : à N utilisateurs × k itérations, nous obtenons au moins N × k mesures par couple (scénario, moteur, palier), soit jusqu'à 1 000 mesures par point à N=200 avec 5 itérations.
Deux runs complémentaires sur vLLM
Le flag --enable-prefix-caching active dans vLLM un mécanisme d’Automatic Prefix Caching (APC) qui rapproche son comportement de RadixAttention, ce flag est activé par défaut. Pour évaluer son impact sur les performances de vLLM nous avons mené deux runs distincts :
- Run A : vLLM avec --enable-prefix-caching activé (run principal, comparé à SGLang et llama.cpp).
- Run B : vLLM avec --no-enable-prefix-caching, utilisé uniquement pour isoler l'effet de l'APC sur chacun des quatre scénarios.
Ce second run n'était pas prévu dans le protocole initial ; il a été ajouté après avoir constaté que les premiers résultats contredisent naïvement l'hypothèse selon laquelle SGLang devait surpasser vLLM sur les workloads conversationnels.
Limites méthodologiques
- Quantification non iso : llama.cpp tourne sur un modèle quantifié en Q4_K_M, tandis que vLLM et SGLang tournent en BF16. Cette asymétrie est délibérée : elle reflète les conditions réelles de déploiement de chacun des moteurs, pas une comparaison iso-précision.
- Configuration matérielle unique : les résultats sont spécifiques à cette combinaison H100 / L40S / Devstral-Small-2-24B. Ils sont indicatifs d'une tendance, pas universellement transposables.
Résultats
Nous décrivons dans la suite les résultats obtenus en analysant les métriques issues de nos scénarios d’évaluation. Nous ne rapportons ici qu’un ensemble de métriques, décrites dans la table 1.2*,* elles ont étaient choisies pour éclairer nos propos et la synthèse finale de l’article. L’analyse est structurée en trois temps, correspondant aux trois hypothèses formulées en amont, positionner llama.cpp comme référence bas de spectre, évaluer l’apport réel de SGLang face à vLLM sur des charges conversationnelles, et enfin traduire ces constats en recommandations opérationnelles.
llama.cpp reste un choix pragmatique pour les petites équipes
La première hypothèse porte l’adéquation de llama.cpp avec des petites équipes (2 à 10 utilisateurs). Les résultats présentés dans la figure 1.3 la confirment, tout en en précisant les limites de manière assez nette. Sur un utilisateur unique, llama.cpp reste compétitif : le Time to First Token se maintient autour de la seconde, et la latence End-to-End (E2E) p50 avoisine les 10 secondes, dans le même ordre de grandeur que vLLM et SGLang. C’est lorsque la charge augmente que le décrochage se manifeste. Dès 5 utilisateurs concurrents, le TTFT p50 de llama.cpp bascule dans un régime différents : il grimpe à environ 15 secondes à 10 utilisateurs, puis à plus de 30 secondes à 20 utilisateurs concurrents, là où vLLM et SGLang restent sur des valeurs quasiments plates, inférieurs à 2 secondes. La latence E2E suit la même trajectoire, passant d’une dizaine à plus de 45 secondes entre 1 et 20 utilisateurs, quand les deux autres moteurs se maintiennent sous les 10 secondes (figure 1.3).
Le TPOT p50, lui, reste globalement stable pour les trois moteurs (autour de 25 à 27 ms pour llama.cpp, 15 à 17 ms pour vLLM et SGLang), ce qui indique que le décrochage ne provient pas du decode lui-même, mais bien du traitement du prefill et de la gestion de la file d’attente sous concurrence. Ce résultat est cohérent avec le positionnement technique de l’outil : llama.cpp ne dispose pas de continous batching ni de mécanismes avancés de gestion du KV cache, et chaque nouvelle requête concurrente entre effectivement en compétition frontale avec les précédentes.
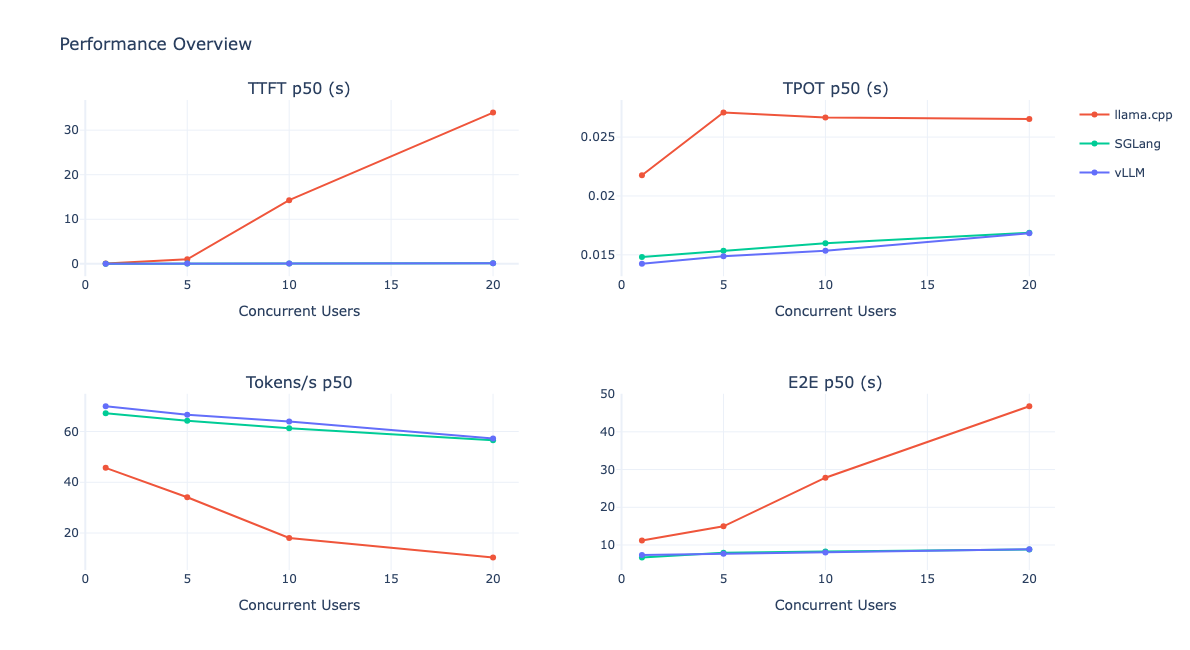
Figure 1.3 - sur cette figure le TFTT, le TPOT, le token par seconde et la latence E2E p50 permettent de montrer que llama.cpp ne peut pas être comparé avec SGlang et vLLM. Entre 5 et 10 utilisateurs tous scénarios confondus, llama.cpp ne rivalise plus avec les deux autres outils et n’est plus utilisable. À noter que llama.cpp a d’autres avantages comme celui de l’exécution optimisé sur CPU ou le support natif des formats GGUF qui est le standard pour l’inférence sur ressources limitées; llama.cpp supporte les quantizations Q4, Q5 et Q8.
Nous retenons donc que llama.cpp reste un choix pragmatique pour les petites équipes (2 à 10 utilisateurs). Son atout ne réside pas dans les performances à charge, mais dans ce qu’il permet là où vLLM et SGLang ne peuvent pas aller : l’inférence locale sur CPU, sans GPU dédié, avec une empreinte mémoire réduite grâce au format GGUF Q4. Au-delà de 10 utilisateurs concurrents, la comparaison avec vLLM et SGLang n’a plus vraiment de sens : les deux derniers jouent dans une autre catégorie. Dans la suite de l’analyse, nous concentrons donc la comparaison sur vLLM et SGLang.
vLLM vs SGLang : l’effet du prefix cache sur les workloads conversationnels
Notre troisième hypothèse était la plus discriminante : SGLang, grâce au RadixAttention, surpasserait vLLM sur les workloads conversationnels caractérisés par des préfixes partagés (system prompts, historiques). Pour la tester, nous avons construit quatre scénarios distincts, que nous avons exécutés sur vLLM (avec et sans le paramètre –enable-prefix-caching ) et sur SGLang (qui active ce comportement par défaut sans paramètre particulier) :
- multi-turn-session : conversation à plusieurs tours, où chaque nouvelle requête intègre tout l’historique précédent.
- shared-prefix : requêtes indépendantes partageant un même préfixe volumineux (typiquement un system prompt de grande taille ou un bloc de documentation injecté en contexte).short-baseline : prompts très courts sans préfixe commun, servant de référence.
- unique-prompts : prompts longs mais strictement disjoints, sans aucune réutilisation possible du cache.
 | |
|---|---|
| (a) Time per Output Token (TPOT) en fonction du nombre d’utilisateurs concurrents sur quatre scénarios distincts. | |
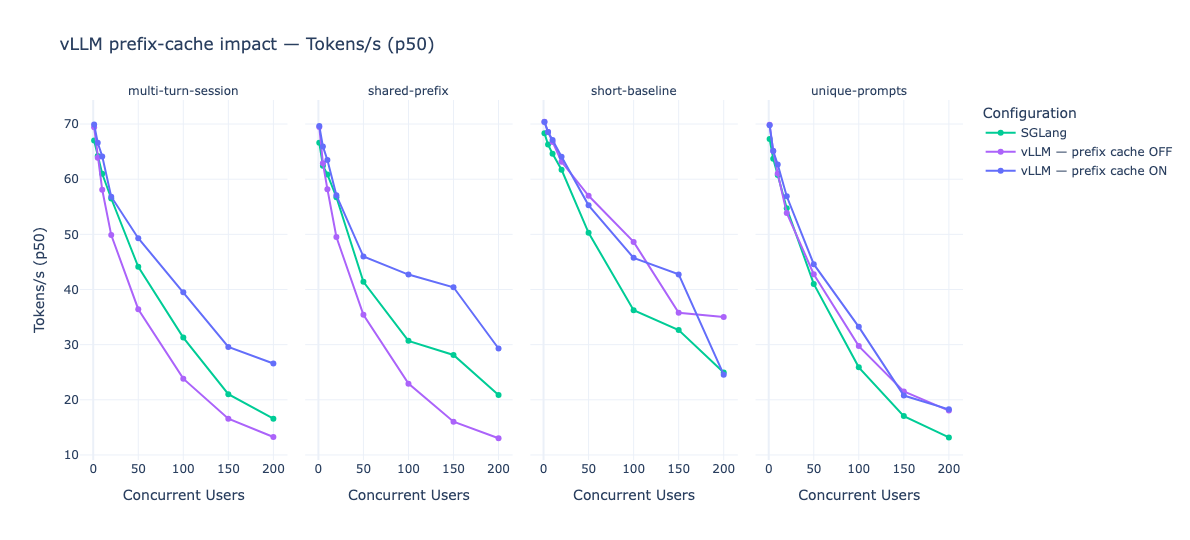 | |
| (b) token/s en fonction du nombre d’utilisateurs concurrents sur quatre scénarios distincts. | |
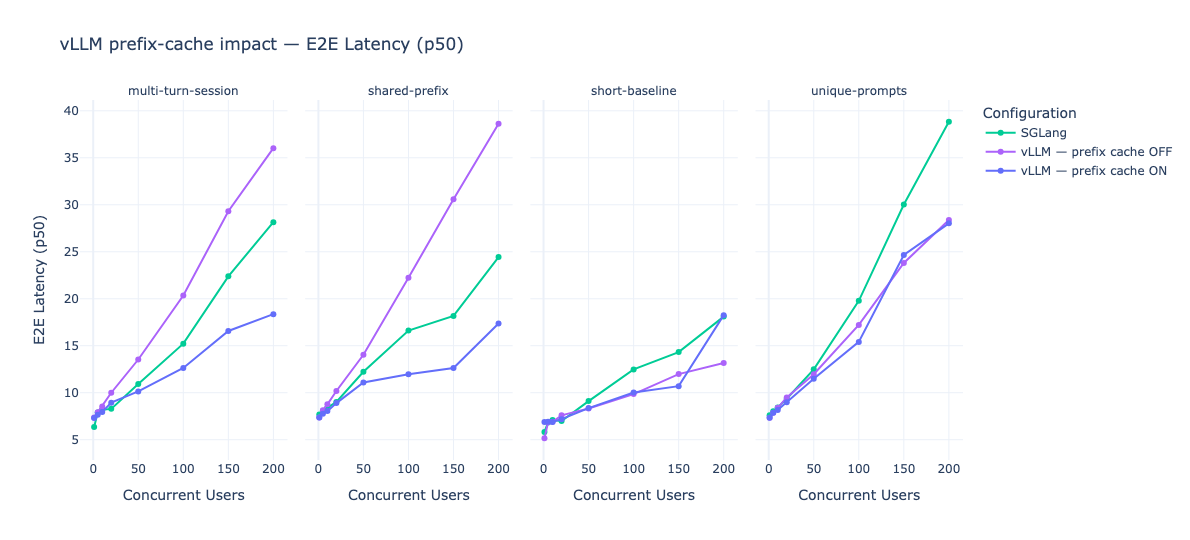 | |
| (c) Latence p50 E2E en fonction du nombre d’utilisateurs concurrents sur quatre scénarios distincts. | |
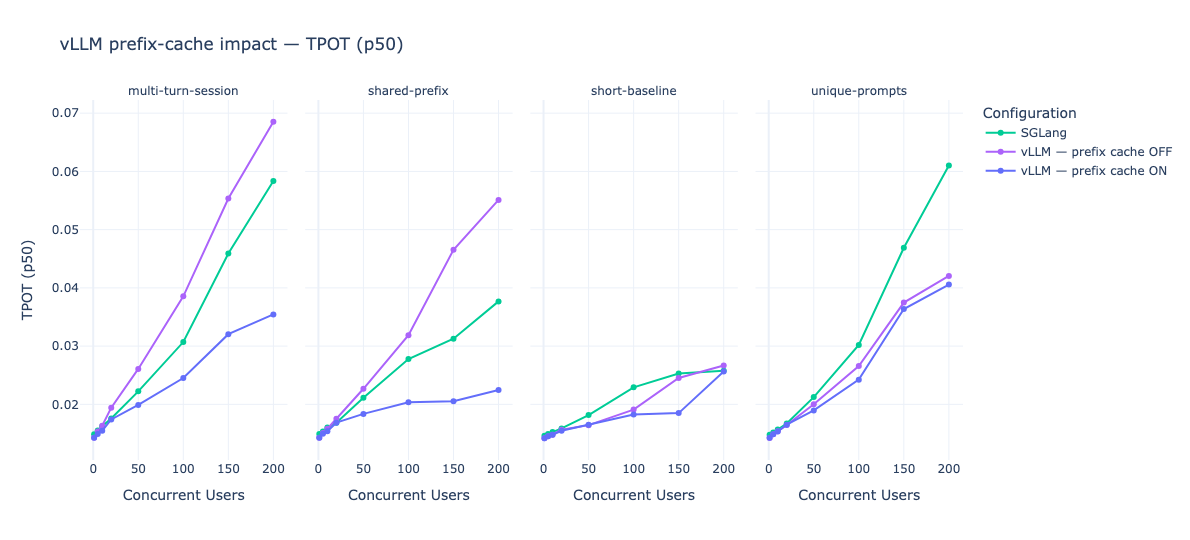
| Figure 1.4 - trois métriques, le TPOT p50, le débit en tokens/s p50 et la latence E2E p50, mise en lumière à travers quatre scénarios comparés sur SGlang et vLLM avec et sans prefix caching*. Sur les deux scénarios de gauche (multi turn session et shared prefix) le prefix cache a une énorme importance sur les capacités de* vLLM*. Sur les deux derniers, son intérêt est plus limité.* |
Des expérimentations décrites dans la figure 1.4, trois enseignements se dégagent. D’abord, sans le prefix cache, vLLM décroche clairement dès que la concurrence dépasse la centaine d'utilisateurs. Ensuite, une fois le prefix cache activé, vLLM prend l'avantage sur SGLang. Enfin, sur les prompts courts ou non redondants, le prefix cache devient contre productif. Nous détaillons par la suite ces trois enseignements.
Premièrement, sur les scénarios multi-turn-session et le shared-prefix, vLLM sans prefix cache décroche clairement dès que la concurrence dépasse la centaine d’utilisateurs : la latence E2E p50 grimpe jusqu’à 35-38 secondes à 200 utilisateurs, contre 18 secondes pour vLLM avec prefix cache activé. L’option –enable-prefix-caching qui est activé par défaut permet donc à vLLM de rester compétitif là où, sans elle, vLLM s’écroule. Ce résultat rappelle utilement qu’une partie du gain attribué à SGLang tient en réalité à une fonctionnalité que vLLM a proposé rapidement depuis son implémentation en 2023 et stabilisé en 2024.
Deuxièmement, une fois que le prefix cache est activé des deux côtés, vLLM prend l’avantage sur SGLang dans nos conditions expérimentales. Sur le multi-turn-session comme sur shared-prefix, vLLM affiche systématiquement un TPOT p50 plus bas, un débit en tokens/s plus élevé et une latence E2E plus faible que SGLang, et ce sur toute la plage de concurrence testée. À 200 utilisateurs concurrents sur shared-prefix, par exemple, vLLM maintient une latence E2E p50 d'environ 17 secondes, contre environ 27 secondes pour SGLang. Ce résultat invalide partiellement notre troisième hypothèse : sur Devstral-Small-2-24B et sur les H100-1-80G que nous avons utilisés, la promesse théorique de RadixAttention ne se traduit pas par un avantage observable.
Troisièmement, sur les prompts courts ou non redondants, le prefix cache devient contre-productif. Sur le scénario short-baseline, les trois configurations convergent (latence E2E p50 autour de 12-18 secondes à 200 utilisateurs), mais on observe que l'activation du prefix cache sur vLLM n’apporte plus aucun gain, voir pénalise légèrement le TPOT aux basses et moyennes concurrences, sous l’effet de l’overhead de gestion du cache sur des prefixes qui ne sont jamais réutilisés. Sur unique-prompts, le constat est encore plus marqué : vLLM avec le prefix cache perd son avantage face à un vLLM sans le prefix cache et à SGLang, tous trois convergent autour de 27-38 secondes à 200 utilisateurs. Autrement dit, –enable-prefix-caching n’est pas un réglage “toujours gagnant” : activer cette option sur un workload sans préfixes partagés, comme de l’auto-complétion inline de type Copilot, revient à payer un coût de gestion sans bénéfice de retour.
Synthèse et recommandations
Les résultats que nous venons de décrire permettent de proposer une grille de décision par cas d’usage. C’est l’objet de la table 1.3.
| Cas d'usage | Taille équipe | Moteur recommandé | Justification |
|---|---|---|---|
| Assistance code stateful (Cline, OpenCode) | 10-100 | vLLM | Gain E2E significatif en multi-turn grâce à l'APC |
| RAG code avec guidelines ou chunks partagés | 10-100 | vLLM | Gain E2E majeur sur shared-prefix à haute concurrence |
| Auto-complétion courte (type Copilot inline) | 10-100 | vLLM sans --enable-prefix-caching | Évite l'overhead observé sur les prompts très courts |
| Usage mono-utilisateur ou équipe réduite, priorité à la simplicité ops | 2-10 | llama.cpp (GGUF Q4) | Compétitif à bas N, une seule commande, empreinte mémoire réduite |
Table 1.3. Synthèse des recommandations par cas d'usage, d'après nos résultats.
D'abord, le choix du moteur n'est pas uniquement un choix d'outil, mais aussi un choix de configuration. Cartographier ses propres usages (longueur moyenne des prompts, taux de réutilisation des systèmes prompts, présence ou non de multi-tour) est un prérequis avant tout choix d'infrastructure.
Ensuite, la comparaison SGLang versus vLLM ne donne pas, dans notre contexte, le vainqueur que l'on pouvait attendre sur la lecture des papiers fondateurs. Cela ne disqualifie pas SGLang sur ses autres atouts (primitives de structured generation, intégration avec des chaînes d'appels complexes) mais ceux-ci sortent du cadre de notre benchmark. Nos observations remettent en perspective l'argument du cache partagé comme différenciateur principal. Pour un cas d'usage d'assistance de code sur une équipe de 10 à 100 développeurs, vLLM correctement configuré apparaît comme le choix le plus robuste et le plus prévisible au moment où nous écrivons ces lignes.
Conclusion et perspectives
L’inférence de LLMs est un des sujets importants de notre nouveau métier : savoir différencier les outils à notre disposition est important, pouvoir être souverain l’est tout autant. Cet article a permis de clarifier plusieurs points.
Mettre en place une infrastructure souveraine n’est pas si compliqué et va devenir cruciale pour certaines organisations. Nos évaluations ont porté sur des H100 et un L40S, des GPUs qui ont aujourd’hui 3 à 4 ans d’ancienneté ; ce qui illustre à quel point le matériel disponible est désormais suffisant pour des déploiements sérieux.
vLLM ressort comme le moteur le plus robuste au moment où nous écrivons ces lignes, à condition d’en comprendre la configuration, notamment l’effet du prefix cache selon le type de workload. SGLang, s’il ne prend pas l’avantage sur les scénarios que nous avons testés, présente un intérêt différent : lors de notre expérimentation avec Devstral, une vingtaine de gigaoctets de VRAM restaient disponibles sur le H100 après chargement du modèle. Cela ouvre la porte à des configurations bi-modèles sur une même carte, par exemple un modèle dédié à la planification et un autre à la génération, une piste à explorer pour des agents spécialisés.
Quant à llama.cpp, il se positionne là où ses contraintes sont réellement des atouts : l’inférence locale sur CPU et avec une empreinte mémoire réduite. Le cas d’usage le plus direct reste le poste personnel ou le serveur maison équipé d’un ou plusieurs GPUs grand public. À plus court terme, une évolution probable est la généralisation de modèles très compacts capables de tourner sur CPU, y compris sur des machines contraintes comme un Raspberry Pi. Cela ne reposera pas uniquement sur des quantizations plus agressives, mais aussi sur des évolutions d’architecture - sparsité, distillation, modèles conçus dès le départ pour être spécialisés sur une tâche précise - permettant d’optimiser ces systèmes pour des cas d’usage ciblés.
Nos perspectives sont donc orientées vers le déploiement opérationnel de ces infrastructures pour outiller concrètement les équipes de développement, et vers l’évaluation continue de la pertinence des modèles open weight face aux modèles commerciaux (dixit la sortie quelques jours avant la publication de cet article de Kimi 2.6).
Bibliographie
[1] Release note des modèles d’Anthropic. Disponible sur : https://platform.claude.com/docs/en/release-notes/overview
[2] OCTO Technology, “Vers un auto-hébergement des modèles VLM/LLM : étude empirique sur une infrastructure entrée de gamme, défis et recommandations.” Disponible sur : https://blog.octo.com/vers-un-auto-hebergement-des-modeles-vlmllm-etude-empirique-sur-une-infrastructure-entree-de-gamme-defis-et-recommandations.
[3] Format GGUF. Disponible sur : https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
[4] W. Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention," in Proceedings of the 29th Symposium on Operating Systems Principles (SOSP '23), 2023. Disponible sur : https://arxiv.org/abs/2309.06180
[5] L. Zheng et al., "SGLang: Efficient Execution of Structured Language Model Programs," 2024. Disponible sur : https://arxiv.org/abs/2312.07104
[6] The Future of Coding Agents. Disponible sur : https://steve-yegge.medium.com/the-future-of-coding-agents-e9451a84207c