Les LLM pour faciliter le dialogue avec les patrimoines de données d'un Data Mesh
De décembre à mars, nos experts OCTO vous proposent un cycle de contenus autour de la data et de l’IA. Le sujet vous intéresse ? Pour découvrir le programme et ne rien rater, inscrivez-vous sur notre page Intelligence Artificielle & Data Science.
L'Intelligence Artificielle générative, perçue par de nombreux experts comme une disruption technologique majeure équivalente à l'avènement d'Internet, remodèle profondément nos organisations et promet des gains d'efficacité sans précédent dans nos activités quotidiennes.
Les conséquences sont vertigineuses pour beaucoup de métiers du savoir et nous pouvons nous poser la question de son impact sur les solutions technologiques mises en place dans les SI.
Nous allons assister à une convergence entre le développement des LLMs (Large Language Models) et les investissements massifs qui ont eu lieu ces dernières années sur les patrimoines data des entreprises.
En permettant un accès facilité et une exploitation automatisée des données de l‘entreprise, les LLMs vont permettre d’accélérer la génération de valeur et la prise de décision via la data.
Les efforts et investissements en standardisation, gouvernance et consolidation technique vont prendre tout leur sens. En s’inscrivant dans cet effort de formalisation, le data mesh est un exemple de stratégie qui permet aux entreprises de préparer leurs produits data à être exploité automatiquement par ces nouveaux outils.
Un ROI data limité
Fig 1: Des puits de données analytiques divers et éclatés dans les diverses entités géographiques des organisations avec une consolidation limitée
Depuis de nombreuses années, les organisations ont mené des projets pour tenter de mieux utiliser les données qu’elles génèrent dans leurs divers systèmes opérationnels. Se sont ainsi succédés les infocentres du siècle dernier, simples copies des bases de données des systèmes opérationnels répondant à des besoins de requêtage sans impacter les opérations, les data warehouses avec leur modélisation des données structurées de back office propres à l’analyse multidimensionnelle, les data lakes pour répondre à un besoin de mémoriser la masse de données structurées et non structurées. Avec un enjeu initial d’aider au pilotage grâce aux données, ces projets data contribuent maintenant aux nouveaux process digitaux des organisations.
La tendance est marquée depuis une dizaine d’années où les organisations ont massivement investi sur les architectures big data pour stocker toujours plus de données avec la promesse de réussir à détecter des poches de valeurs par la réalisation des croisements de données inexploitées.
D’abord on-premise, ces infrastructures coûteuses ont ensuite peu à peu pris le virage du Cloud pour faire face à leur volume croissant et stocker les données brutes dans l’espoir d’une valeur à venir. Une course s’est alors engagée pour stocker toujours plus de données d’un côté, et cataloguer et digérer cette donnée de l’autre pour répondre à la demande croissante et légitime des métiers d’accéder à cette manne d’informations.
Malheureusement, les cas d’usage impactants se heurtent à des difficultés pour passer à l’échelle industrielle et à une adoption insuffisante par les utilisateurs finaux. Et jusqu’en 2020 nous voyons de nombreux datalab et autres usines à POCs s’arrêter faute de capacité à industrialiser ou par manque d’adoption par les métiers (1) (2).
Finalement, le big data devient “has been”, les use cases se recentrent sur la valeur métier et sur l’utilisateur final à qui il est vain de demander d’analyser des téraoctets de données. Le big data devient “not so big data”, le SQL revient en force pour redevenir la norme d’accès aux données et la compétence minimale à maîtriser.
On a alors assisté au foisonnement d’initiatives locales portées par les métiers et souvent indépendamment des équipes IT. Graduellement, des silos de données se sont créés rendant inefficients le partage et l’utilisation d’un langage commun entre métiers. Le fossé s’est également creusé avec l’IT et les investissements au niveau Groupe se sont concentrés sur de la consolidation et du pilotage majoritairement financiers.
La définition de politiques de gouvernance de données globale, matérialisée par la mise en œuvre de data catalogues a souvent été décevante et a rarement permis de reprendre le contrôle de ses données du fait d’une maintenance trop manuelle.
Force est de constater que ces glossaires ou registres de données déployés, sont complexes à alimenter, et peuvent manquer d’adoption. Hormis pour quelques data scientists ou analystes dont le métier est d’exploiter les données et qui eux-mêmes travaillent à un instant t sur un set limité de ces données, le ticket d’entrée à la démocratisation de l’exploitation métier des données reste trop élevé.
Casser le monolithe pour augmenter le ROI des données
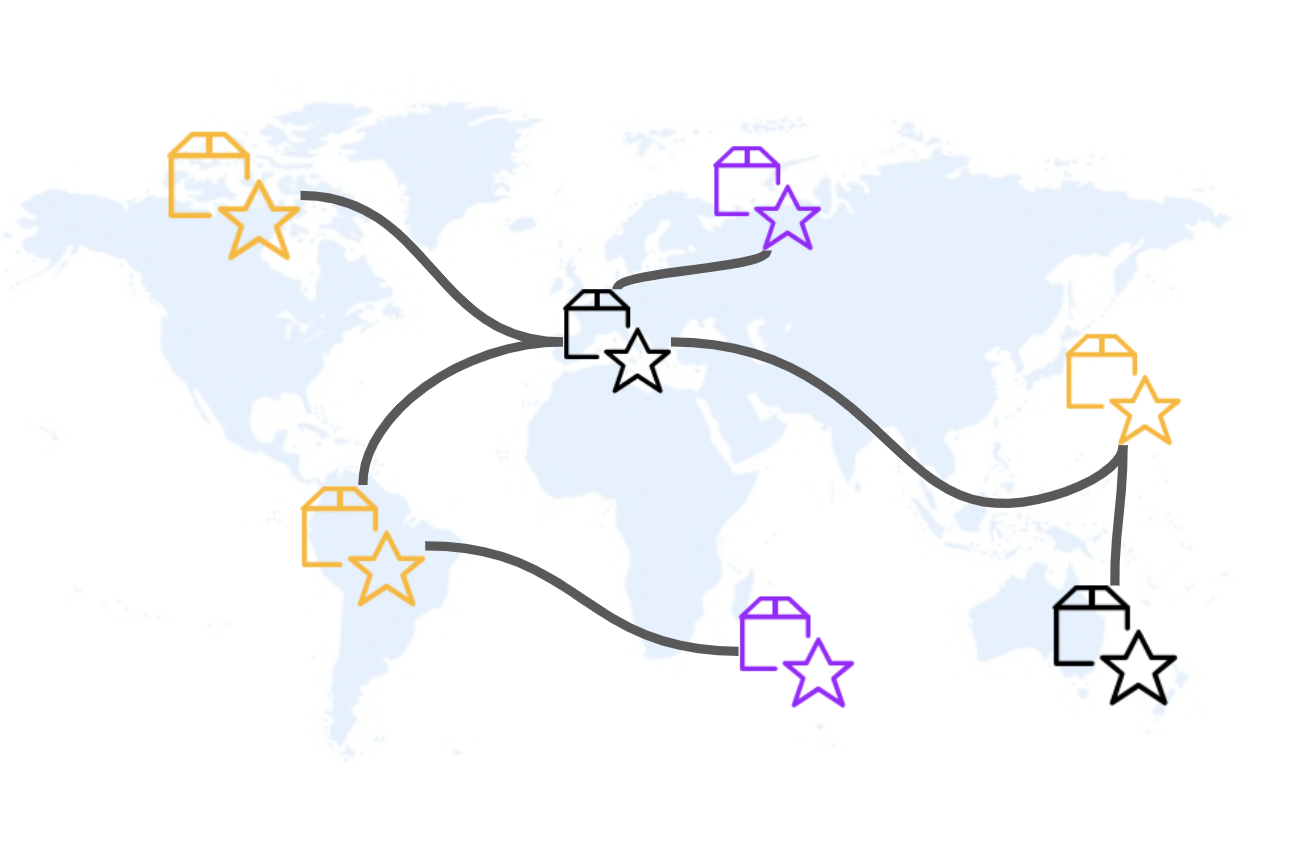
Fig 2: Des data products normalisés gérés localement dans les entités organisationnelles et interconnectés.
Face à ces difficultés et pour répondre aux enjeux de valorisation à l’échelle des données, la tendance Data Mesh s’inscrit dans un besoin d’évolution avec une vision tirée de l’UX et du Domain Driven Design. Les quatre principes du Data Mesh fondent un écosystème de données où les silos peuvent disparaître, mais sans inhiber la recherche d’agilité des métiers nécessaire pour s’adapter à tous les changements auxquels nous sommes confrontés.
Dans un premier temps, la donnée devient elle-même un produit géré par le métier, avec une vraie offre de service (SLI, SLO, SLA). On parle de “data as a product”.
Le deuxième principe est celui d’une responsabilité décentralisée des données. En alternative aux entrepôts de données centralisés où la gouvernance et l’ouverture des données est complexe, chaque domaine crée et gère son périmètre de données, leur usage, leur accès, leur qualité. La décentralisation des gestes techniques est rendue possible par une plateforme data en libre-service abstrayant l’infrastructure et offrant des expériences aux développeurs comme aux consommateurs des données.
Cela passe par la standardisation des accès (par exemple, en s’appuyant sur le SQL) et par des standards de représentation des données et des métadonnées pour assurer leur interopérabilité, documentation et découverte (on parle de “data contract”).
Le dernier principe est celui d’une gouvernance fédérée de la donnée pour répondre à des exigences globales minimales et locales de conformité.
Cette approche socio-technique(3) révolutionne l’architecture des données et autonomise les métiers dans leur gestion. Mais, comme tout nouveau pattern qui impose un changement technique et organisationnel, les implémentations pratiques sont encore naissantes. Et même si la philosophie du data mesh est séduisante, il manque souvent la volonté stratégique nécessaire au financement de cette transformation et la maturité de premiers domaines métiers au sein des organisations prêts à porter ce sujet d’innovation.
Opportunités en 2024 : Démultiplier le ROI via les LLMs ?
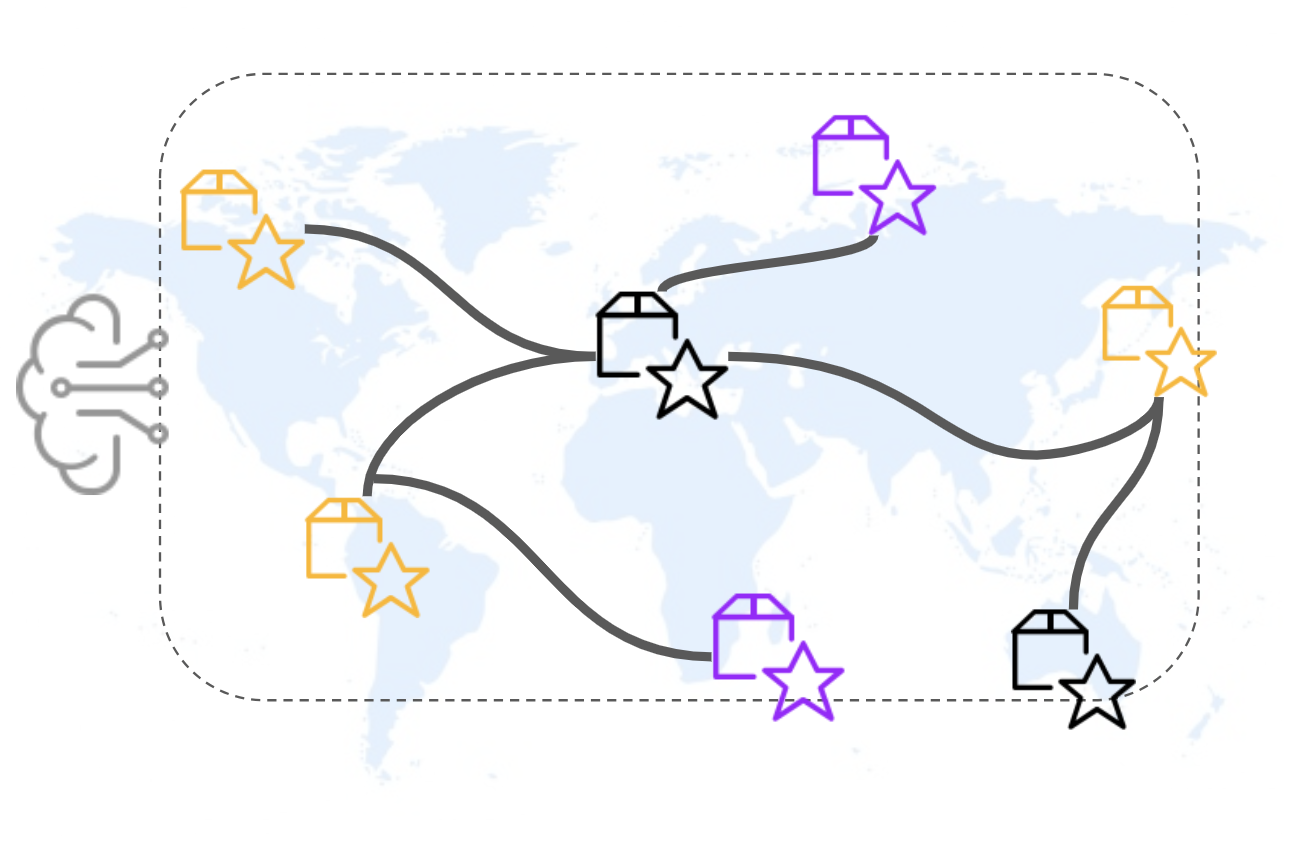
Fig 3: Des data products exploités automatiquement par des LLM
Nous avons tous assisté à la déferlante ChatGPT depuis sa sortie en Octobre 2022. Son succès phénoménal(4) tient au nouveau mode d’échange en langage naturel qu’il propose, pour exploiter et raisonner sur les connaissances indexées par les moteurs de recherche. L’interaction n’est plus une restitution simple du texte mais est une synthèse similaire à celle réalisée par un humain après l’assimilation d’une information.
L’engouement pour ce nouveau mode d’accès à la connaissance a entraîné un foisonnement de réflexions sur son impact et son adoption dans les processus d’entreprise existants, et en premier lieu, de manière assez naturelle dans les services supports de type helpdesk.
Parmi ces nouvelles approches, les RAGs (Retrieval Augmented Generation), ont affiné ce nouvel échange homme-machine en le contextualisant à une connaissance spécifique. L’intérêt est de rendre plus pertinentes les réponses des LLMs. Via du prompt engineering, le LLM est contextualisé préalablement des informations textuelles d’un domaine, telles que des documents stockés sur un sharepoint, une base de connaissances de FAQ, ou des manuels d’utilisation.
L’idée est de réussir à proposer un échange en langage naturel avec un “IA experte” d’un domaine particulier.
Ainsi, les LLMs combinés avec de la recherche sémantique permettent d’exploiter et de raisonner de façon massive sur des données textuelles non structurées propres à une organisation. La notion d’actions, intégrée à des outils GenAI permettent ensuite de requêter automatiquement des API dans le cadre de ce contexte de connaissance particulier. Nous allions ainsi la puissance de raisonnement des LLM à des bases de connaissances particulières.
(Pour une introduction au RAG: article de blog octo Construire son RAG (Retrieval Augmented Generation) grâce à langchain: L’exemple de l’Helpdesk d’OCTO - OCTO Talks !)
Le data self service
On peut alors imaginer l’adaptation d’outils comme OpenAI GPTs ou Langchain OpenGPTs pour faciliter l'exploitation de notre patrimoine data, permettant ainsi d’échanger en langage naturel avec cet “internet” des données disponible au sein des organisations.
L’ambition des organisations “data driven”, associée aux revendications des métiers d'obtenir l’accès libre aux données (on parle de “data démocratisation”) est peut-être en passe d’être réalisée. La barrière de compréhension de ce qu’est une donnée, de sa structuration en tables et jointures de tables, de maîtrise du SQL, ou d’outils de Business Intelligence, s’abaisse pour proposer une interface propre aux humains, le langage courant.
L’enjeu revient alors à construire le patrimoine documentaire que le LLM va devoir comprendre.
Qu’est-ce qu’une donnée?
Un chiffre, une chaîne de caractères associés à un concept (ou entité).
En tant qu’utilisateur, cette donnée ne fait aucun sens sans y associer une entité.
“1000”, est-il le chiffre d’affaires en euros, ma marge brute, mon nombre de collaborateurs en France ?
Associé à une entité à la définition claire et partagée, ce nombre devient une information utile dans nos analyses ou nos échanges avec nos collègues.
Imaginons donc la modélisation d’un graphe de mes entités (on parle de knowlege ou semantic graph) permettant de les relier entre elles (le knowledge graph relie plusieurs noeuds, ici plusieurs entités telles qu’un client lié à un article par sa prise de commande via le canal du site web), où chaque entité possède une description textuelle m’en donnant une définition précise ainsi que d’autres propriétés documentaires me permettant de bien la cerner. On se rend compte que l’on commence à décrire un “data contract” pour chacune de ces entités(5).
Cet effort de standardisation et de documentation de mes données pourrait également alimenter des IA expertes via des RAGs associés aux LLMs..
Et c’est ici que l’exploitation des récentes avancées dans le GenAI va nous permettre d’assimiler ces informations, les corréler grâce aux contrats de données, et ainsi proposer à nos utilisateurs la génération automatique de SQL ou de rapports. En définitive, une vraie exploitation “no-code” de notre patrimoine data.
Pouvons-nous compter sur les avancées en LLMs afin qu’ils digèrent ces informations et génèrent des actions, comme un code SQL, qui soit pertinent sur un contexte métier ?
Même s'il n’existe pas encore de solution “sur étagère” qui implémente cette capacité de consommer notre patrimoine data et de le restituer, nous pensons que nous disposons aujourd’hui de tous les outils.
Par exemple, la capacité des LLMs à structurer, valider et générer des réponses avec des formats précis n’est plus à prouver. Nous pouvons citer :
- La structuration JSON offerte par la dernière version de GPT4. Elle permet de spécifier que l’espace de sortie du LLM ne sera pas en langage naturel mais directement un format interprétable par nos programmes, le JSON.
- Dans l’écosystème open-source le format GBNF, proposé par llama.cpp permet de contraindre la sortie du LLM avec une grammaire fixe.
- On trouve également la preview de Copilot for PowerBI qui permet la génération de rapports automatiques.
Conclusion
De même que ChatGPT a créé la conversation avec le Web, la combinaison des LLMs, des RAGs et de l’accès aux APIs existantes dans les entreprises va permettre le dialogue des métiers avec toutes les données de leur organisation. Elle va créer ce pont entre les investissements massifs de ces dernières années et une vraie adoption des utilisateurs. Ces investissements, qui ont rarement eu un ROI positif, constituent maintenant les fondations de ce nouvel âge de la donnée.
Le Data Mesh décrit une première convergence socio-technique avec le data product, la standardisation de sa description, documentation et accès automatisant la découverte et l’accès aux patrimoines data. Les systèmes de RAG puis d’agents propres aux LLMs nous donnent les leviers nécessaires à l’exploitation automatique des données.
ChatGPT a formé des centaines de millions d’humains à interagir avec une IA. Une convergence sur l’adoption de la data va donc s’opérer.
- Innovation : quand le groupe AXA siffle la fin de la récré
- Que deviennent les data labs
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh (martinfowler.com)
- ChatGPT vient de battre un incroyable record de popularité (01net.com)
- Partager la donnée analytique en toute confiance grâce aux Data Contracts
Pour tout savoir sur les enjeux Data & IA, rendez-vous sur notre page dédiée. Découvrez aussi La Grosse Conf, la conférence Data & IA by OCTO qui pose un cadre à la mesure des enjeux. Programme, infos et billetterie sur lagrosseconf.com.