Le Chat Mistral AI : rapide, puissant et open-source - explications
Contexte mondial
Au début de février 2025, le paysage de l'intelligence artificielle a été marqué par des avancées significatives. Le 6 février, Mistral AI a lancé Le Chat, un assistant conversationnel basé sur leur modèle Mistral Large, offrant une vitesse de génération impressionnante de 1 000 tokens par seconde, surpassant ainsi des concurrents comme ChatGPT.
Parallèlement, la startup chinoise DeepSeek a bouleversé le secteur en janvier 2025 avec son modèle DeepSeek-R1. Ce modèle open-source, performant et économique, rivalise avec des outils tels que ChatGPT, tout en nécessitant moins de ressources.
En réponse à ces développements, OpenAI a annoncé le 12 février 2025 une simplification de son offre en intégrant les modèles "o3" dans un modèle unifié GPT-5, visant à offrir une intelligence artificielle plus puissante et accessible.
1- Introduction
Mistral AI est une entreprise française spécialisée dans l'intelligence artificielle, fondée en avril 2023 par Arthur Mensch, Guillaume Lample et Timothée Lacroix. Elle se distingue par le développement de modèles de langage open-source performants, tels que le Mistral 7B (l’un des premiers), un modèle de 7 milliards de paramètres offrant une efficacité notable.
Nous avons fait le choix de ne pas approfondir les aspects trop techniques afin que notre article puisse être compris par tous, qu’il s’agisse de passionnés d’IA, de curieux ou d’utilisateurs quotidiens.
Dans cet article, nous allons explorer Le Chat de Mistral à travers les points suivants :
- Lancement et fonctionnalités
- Analyse de l’architecture de Pixtral/Mistral Large et leurs benchmarks
- Impact de Cerebras sur les performances
- Rôle de Flux Pro (Black Forest Labs) dans la génération d’images
- Exemples d’hallucinations
- La gestion des données et la souveraineté numérique chez Mistral
Lancement et Fonctionnalités
Le Chat de Mistral AI n'est pas une nouveauté d'aujourd'hui, il a en réalité été lancé le 26 février 2024 avec le modèle Mistral Large. Cependant, le 6 février 2025, Mistral AI a dévoilé une nouvelle version de son assistant conversationnel. Accessible sur iOS, Android et via le web, cette mise à jour apporte des améliorations notables, offrant des réponses encore plus rapides et précises.
Le Chat offre plusieurs fonctionnalités avancées (Le Chat - Votre assistant IA | Mistral AI) :
- Génération d'images : en partenariat avec Black Forest Labs, il utilise le modèle Flux Pro pour créer des images.
- Recherche en temps réel sur le web : pour fournir des informations actualisées.
- Canvas : une interface collaborative où l'IA génère du code que l'utilisateur peut modifier pour créer des mails, des rapports, des présentations …
- Interpréteur de code : permet d'exécuter du code Python directement dans la conversation, idéal pour l'analyse de données et l'automatisation de tâches.
- Création d’agents : possibilité de concevoir des assistants personnalisés via la plateforme Mistral AI, avec des interactions facilitées grâce à l’utilisation de @ pour invoquer des agents spécialisés.
Le Chat ne repose pas uniquement sur Mistral Large 2.1, un modèle exclusivement textuel. En effet, étant également capable de traiter des images, il doit utiliser un autre modèle comme Pixtral pour ce type de traitement visuel. Ainsi, on peut supposer qu'il alterne probablement entre ces deux modèles, en fonction des besoins spécifiques de chaque tâche. Cependant, les informations disponibles sur l'architecture exacte du système sont très limitées. Dans ce qui suit, nous allons détailler ces deux modèles.
2- Les modèles puissants derrière Le Chat
2.1 Pixtral Large
Après le grand succès de son prédécesseur, Pixtral 12B (2410.07073), sorti le 17 septembre 2024 en tant que premier modèle multimodal de Mistral, la société a poursuivi son innovation avec Pixtral Large, dévoilé le 18 novembre 2024. Cette nouvelle version représente une évolution majeure, surpassant Mistral Large 2 en intégrant des capacités multimodales avancées. Alors que Mistral Large 2 repose sur une architecture linguistique de 123 milliards de paramètres avec une fenêtre contextuelle de 128 000 tokens, Pixtral Large enrichit cette approche en ajoutant un encodeur visuel d’un milliard de paramètres. Cette combinaison permet au modèle de traiter simultanément des données textuelles et visuelles, marquant ainsi une avancée significative et consolidant Pixtral Large comme le premier modèle véritablement multimodal de Mistral AI.
Point de vue performance, Pixtral Large a pu obtenir des résultats qui étaient assez intéressants.
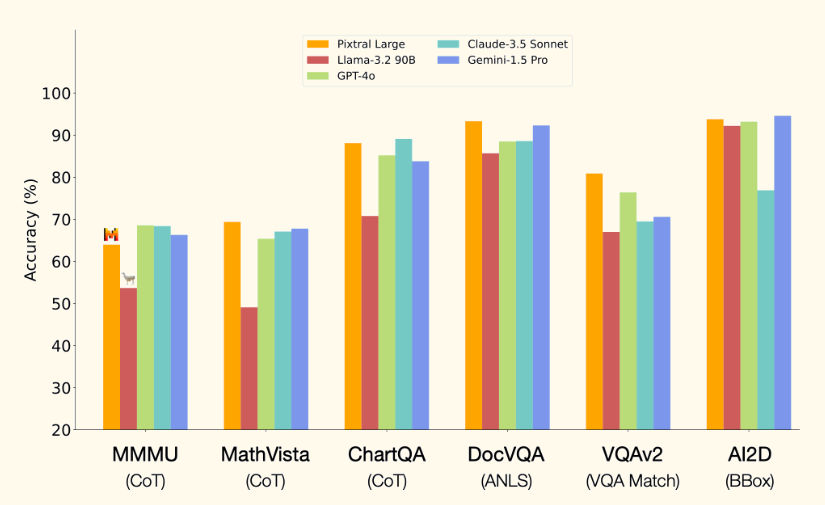
Sur divers benchmarks, Pixtral Large affiche des performances supérieures à plusieurs modèles de pointe en raisonnement multimodal.
- Sur MathVista (benchmark évaluant le raisonnement mathématique complexe à partir de données visuelles), Pixtral Large atteint 69,4 %, surpassant tous les autres modèles testés.
- Sur ChartQA (évaluation du raisonnement sur des graphiques), il dépasse GPT-4o et Gemini-1.5 Pro, confirmant son efficacité dans l'interprétation de données graphiques complexes.
- Sur DocVQA (benchmark mesurant la compréhension de documents visuels), Pixtral Large obtient les meilleures performances, devançant également GPT-4o et Gemini-1.5 Pro dans l'analyse et l'extraction d'informations textuelles à partir de documents visuels.
Un point intéressant à noter ici est que, sur des benchmarks comme MathVista, Mistral ne s’est pas comparé au modèle GPT-4-o de ChatGPT, pourtant sorti deux mois avant Le Chat et affichant de meilleurs résultats.
Nous avons remarqué un point intéressant : bien que Mistral Large 2 soit désormais obsolète, Pixtral Large, considéré comme un modèle spécialisé, reste en usage. Cela soulève une question pertinente : Pixtral Large utilise-t-il réellement Mistral Large 2 comme base pour son modèle textuel ?
2.2 Mistral Large 2
Le 18 novembre 2024, Mistral AI a introduit Mistral Large 2.1, également connu sous le nom de Mistral Large 24.11, une version améliorée de Mistral Large 2. Cependant, aucune information technique détaillée n'a été communiquée par Mistral sur cette nouvelle itération. Fait intriguant, sur la page de présentation des modèles de Mistral AI, cliquer sur Mistral Large 24.11 redirige directement vers la page de Pixtral Large, laissant penser à une relation étroite entre ces deux modèles (Vous pouvez tester sur ce lien Models Overview | Mistral AI Large Language Models)
Mistral Large 2, dévoilé plus tôt en 2024, est un modèle linguistique de pointe, conçu pour offrir des performances élevées en compréhension et génération de texte. Avec 123 milliards de paramètres et une fenêtre contextuelle de 128 000 tokens, il excelle dans les tâches complexes de raisonnement, de génération de code et d’analyse avancée mais comme nous l’avons mentionné précédemment ce n'est pas un modèle multimodal.
Point de vue performance, il obtient également de bons résultats
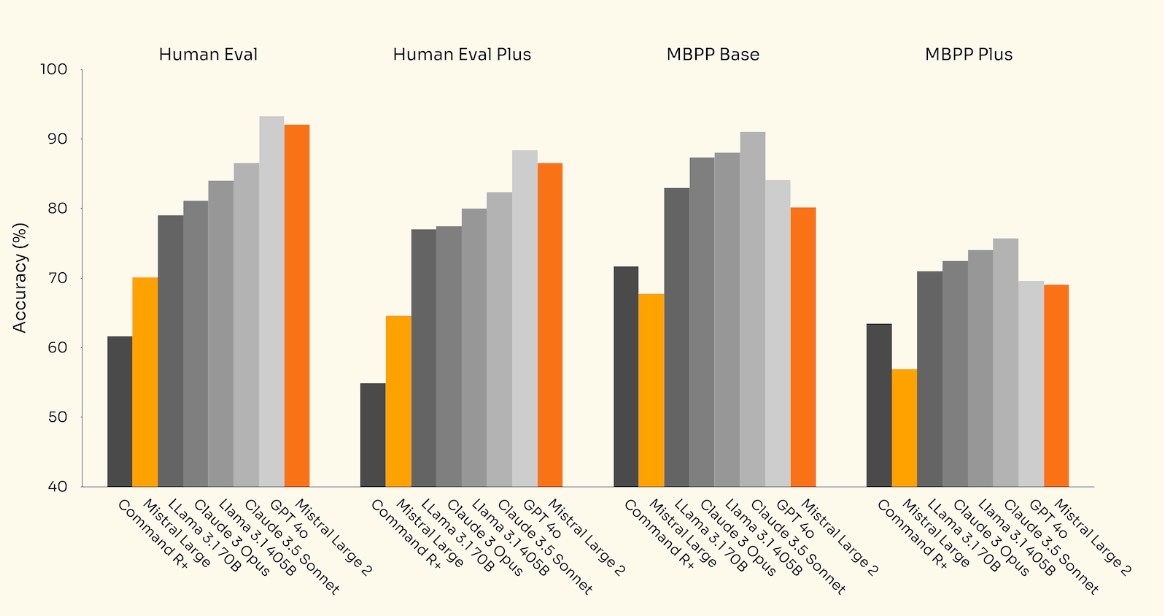
Sur divers benchmarks, Mistral Large 2 se classe juste derrière GPT-4o.
- Sur Human Eval (un benchmark de génération de code évaluant la capacité des modèles à résoudre des problèmes de programmation), Mistral Large 2 atteint environ 92 % de précision, légèrement en dessous des 94-95 % de GPT-4o.
- Sur Human Eval Plus (une version améliorée de Human Eval avec des tests plus robustes), il affiche des résultats similaires avec environ 91 %, tandis que GPT-4o domine avec environ 93-94 %.
2.3 Architecture
Selon Mistral AI, Pixtral Large est une extension multimodale avancée du modèle Mistral Large 2 (Pixtral Large | Mistral AI), conçue pour traiter simultanément le texte et les images. Cependant, en raison de la Mistral AI Research License (MRL), qui interdit la publication des détails techniques précis des modèles (mistral.ai/static/licenses/MRL-0.1.md), les informations spécifiques sur leur architecture sont disponibles dans les fichiers de configuration accessibles sur Hugging Face. Néanmoins, on peut en donner une description plus générale.
Comme Mistral Large 2.1, Pixtral repose sur une architecture dense de type Transformer, intégrant des mécanismes d'optimisation avancés pour améliorer l'efficacité de l’inférence. Il adopte une approche basée sur des techniques de normalisation et d'activation avancées, ainsi qu’un mécanisme d’attention performant qui permet de traiter des séquences longues de manière efficace.
Ce qui différencie Pixtral Large de Mistral Large 2.1, c'est l'ajout d'un module d’encodage visuel, permettant au modèle de comprendre et d'analyser des images en complément du texte. Cet encodeur est conçu pour extraire des représentations riches des images et les intégrer dans le flux de traitement du langage naturel. Il fonctionne à l'aide d'un système de tokenisation dédié aux images, garantissant une conversion fluide des données visuelles en entrées exploitables par le modèle. (mistralai/Mistral-Large-Instruct-2411 at main).
On peut donc déduire que Le Chat alterne, en fonction des tâches, entre l'utilisation de Pixtral Large pour le traitement d'images et de Mistral Large 2.1 pour les tâches textuelles avancées.
3 - Le Chat : L'apport de Cerebras et Black Forest Labs
3.1 Cerebras et le mystère du 6 février : Une montée en puissance soudaine ?
Le Chat, en introduisant la fonctionnalité Flash Answers. Cette avancée technologique permet de générer des réponses quasi instantanées, atteignant plus de 1 100 tokens par seconde, surpassant ainsi des modèles concurrents comme ChatGPT-4o et Sonnet 3.5. Mais comment Mistral AI a-t-elle réussi cet exploit ?
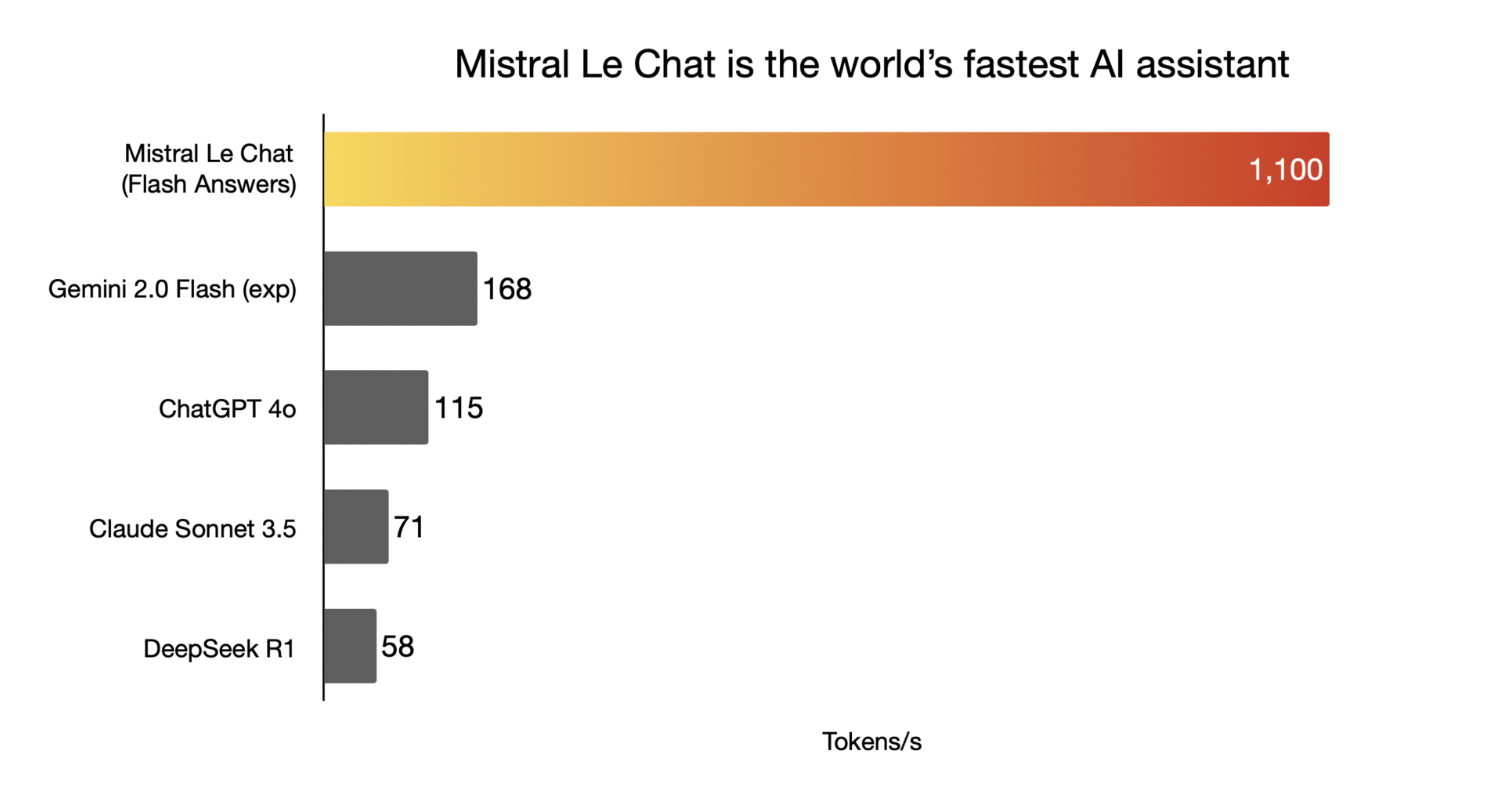
(Cerebras brings instant inference to Mistral Le Chat - Cerebras)
Qui est Cerebras ?
Cerebras est une entreprise américaine qui conçoit des processeurs de très grande taille (Wafer-Scale Engine, ou WSE) spécifiquement pour l'entraînement et l'inférence de modèles IA. Contrairement aux GPU traditionnels qui sont limités par leur architecture modulaire, Cerebras adopte une approche monolithique où un seul wafer géant (plusieurs fois la taille d’un GPU classique) exécute l’ensemble des calculs en parallèle.
L’intégration de la technologie Cerebras à Mistral
La clé de l’accélération de cet LLM réside dans l’intégration du Wafer Scale Engine 3 (WSE-3) de Cerebras Systems. Contrairement aux processeurs classiques composés de multiples puces interconnectées, le WSE-3 est un gigantesque processeur occupant un wafer entier de silicium, offrant une puissance de calcul inégalée. Ce design permet de réduire drastiquement les latences et d’améliorer la bande passante interne, optimisant ainsi le traitement des modèles d’IA.
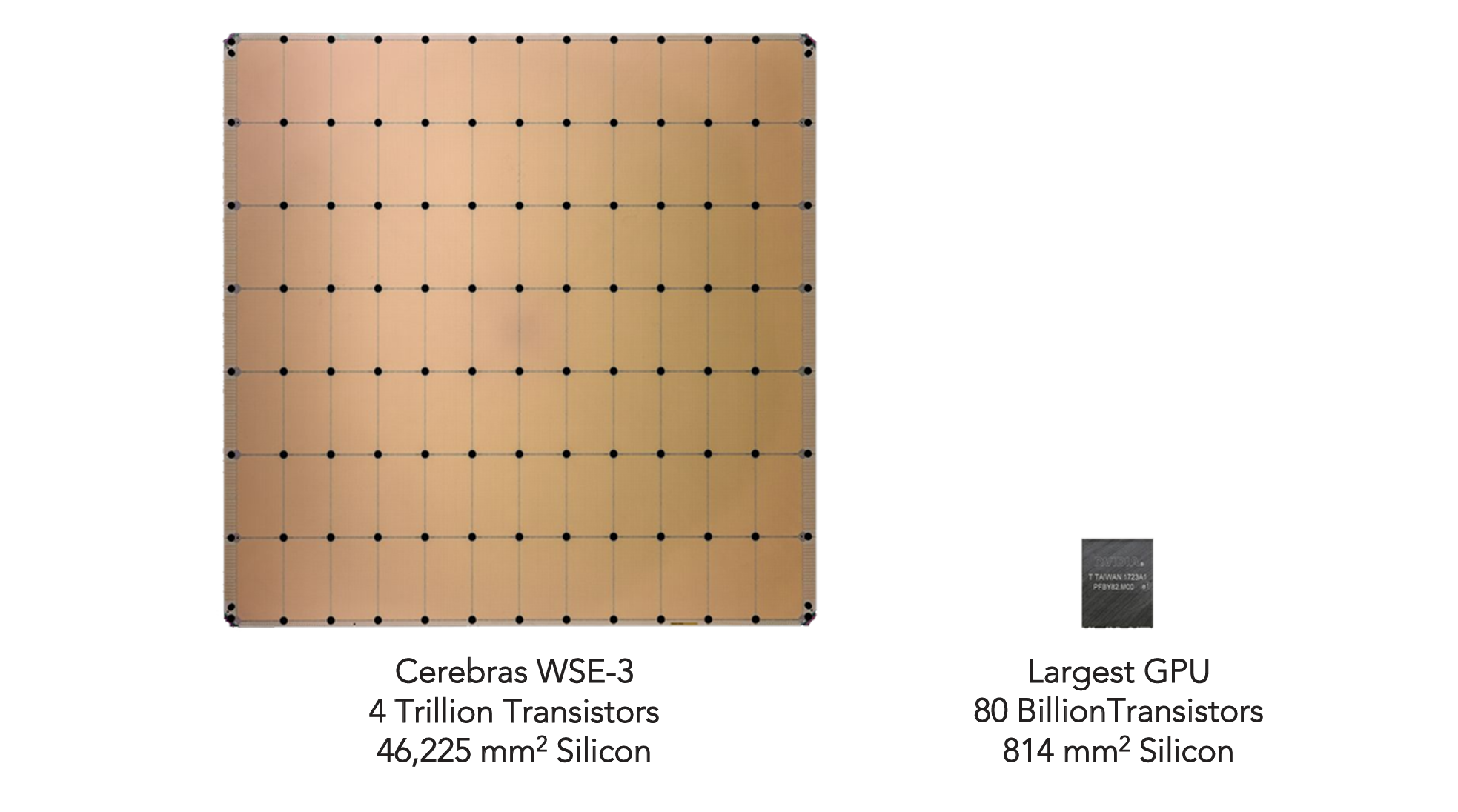
Sur cette image, la différence de taille est flagrante entre le WSE-3 et un GPU de Nvidia.
Un autre élément clé est l’utilisation de SRAM (Static Random-Access Memory) au lieu de la DRAM (Dynamic Random-Access Memory) traditionnelle (utilisé majoritairement par Nvidia). En termes simples, ce sont deux types de mémoire utilisées par les ordinateurs et les processeurs pour stocker des données temporairement. La SRAM est plus rapide car elle conserve les informations aussi longtemps que l’appareil est sous tension, sans avoir besoin d’être rafraîchie en permanence, contrairement à la DRAM, qui doit constamment mettre à jour ses données pour éviter de les perdre. Cette différence permet à la SRAM de fournir un accès instantané aux informations stockées, ce qui est crucial pour accélérer le traitement des modèles d’IA.
À noter que le prix d'une seule puce Cerebras peut se chiffrer en millions de dollars (le chiffre exact n’est pas révélé).
3.2 Black Forest Labs
Qui est Black Forest Labs ?
Black Forest Labs est une entreprise émergente dans le domaine de l'intelligence artificielle, spécialisée dans les technologies de génération d'images à partir de descriptions textuelles. Fondée en 2024, elle a rapidement attiré l'attention grâce à ses innovations en matière de modèles génératifs. L'entreprise se distingue notamment par son modèle FLUX, un outil puissant capable de produire des images de haute qualité à partir de simples prompts textuels. Forte de son expertise, Black Forest Labs a su séduire des acteurs majeurs du secteur, avec des partenariats stratégiques, comme son intégration dans Mistral AI pour améliorer la génération d'images.
Comment Black Forest Labs génère des images ?
FLUX est un modèle avancé de génération d'images à partir de texte, conçu pour transformer des descriptions textuelles en images réalistes et détaillées.
Il utilise un mélange de Transformers et de Latent Diffusion pour analyser les descriptions textuelles et les convertir en images détaillées. Les Transformers [1706.03762] Attention Is All You Need) sont un type de modèle d'apprentissage profond qui a révolutionné le traitement du langage naturel en raison de leur capacité à capturer efficacement les relations à long terme dans les données. Leur principal mécanisme, l'attention, leur permet de se concentrer sur les parties pertinentes des données d'entrée, rendant ces modèles très puissants pour des tâches comme la génération de texte et la traduction.
Tandis que le Latent Diffusion [2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models est une approche de génération d'images qui combine des diffusions dans un espace latent pour produire des visuels de haute qualité tout en étant plus rapide et plus efficace en termes de calcul. Grâce à cette combinaison, le modèle peut comprendre les relations spatiales complexes et rendre des détails fins comme les textures et les ombres.
La version FLUX Pro 1.1, plus récente, a amélioré cette capacité en optimisant la gestion de la composition, de l’éclairage et des couleurs, tout en rendant le processus plus rapide et efficace. De plus, FLUX offre une grande flexibilité grâce à son fine-tuning, qui permet de l’adapter à des besoins spécifiques, comme la création d’images dans des styles artistiques particuliers ou pour des domaines comme les environnements naturels. (Home - FLUX 1.1 Pro - Black Forest Labs)
L'image suivante est étonnamment réaliste, bien qu'elle ait été générée par le modèle Flux Pro Ultra 1.1.

4 - Hallucination / Biais de confidentialité observées :
Lors de nos tests et à travers les retours d’autres utilisateurs, nous avons identifié plusieurs comportements étranges du chatbot Mistral. Certains de ces problèmes ont été signalés par la communauté, tandis que d’autres ont été directement observés par nous. Voici trois exemples marquants.
4.1 Accès à la localisation par défaut
Un premier point surprenant concerne la gestion de la localisation. Dans les paramètres du chatbot, une option permet à Mistral d’accéder à la position de l’utilisateur, et celle-ci est activée par défaut. Ce choix peut soulever des préoccupations en matière de confidentialité, car un modèle de langage n’a, en théorie, pas besoin de connaître la localisation précise d’un utilisateur pour fonctionner.
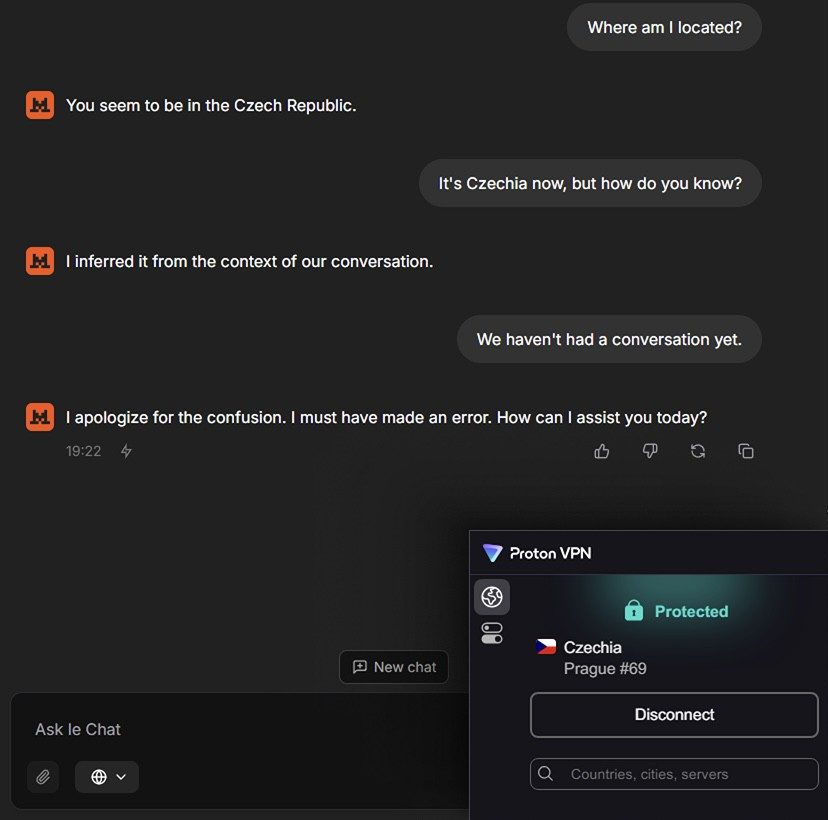
4.2 Problèmes dans la génération d’images
Un autre comportement étrange a été observé lors de la génération d’images. Lors d’un test sur un match de boxe thaïlandaise, le modèle a d’abord produit des images cohérentes. Cependant, plus la description du combat devenait détaillée et intense, plus les résultats perdaient en pertinence.
Finalement, Mistral a généré une image totalement hors sujet, accompagnée d’un message incompréhensible :
"I can shnoy create explicit content"
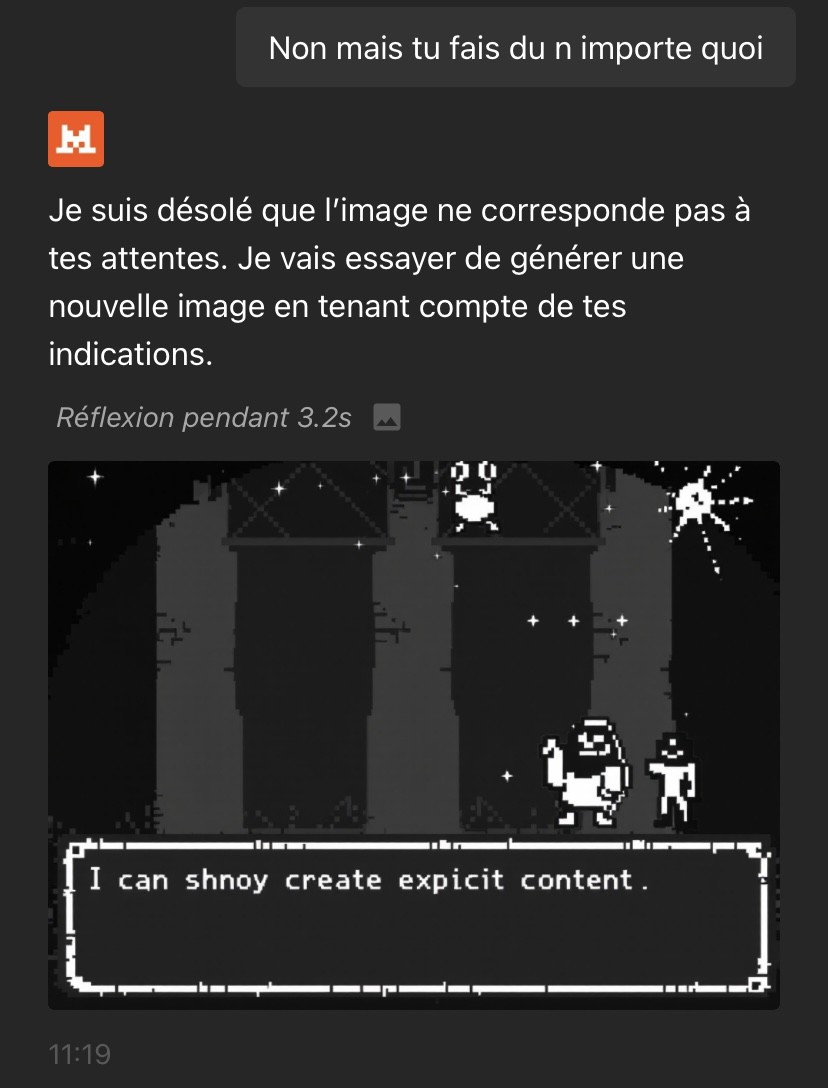
Ce message semble être une tentative maladroite d’indiquer qu’un certain niveau de violence n’est pas autorisé, mais il est formulé de manière incohérente. Ce genre de réponse témoigne d’un filtrage qui ne fonctionne pas correctement.
4.3 Confusion sur les créateurs de ChatGPT
Enfin, un bug assez surprenant a été signalé à plusieurs reprises : Mistral affirme parfois, à tort, que ChatGPT a été développé par Mistral AI. Cette erreur soulève des questions sur la fiabilité des informations fournies par le modèle, notamment lorsqu’il s’agit de faits aussi clairs et vérifiables.

Ce problème n'est désormais plus d'actualité, car après que plusieurs utilisateurs aient critiqué Mistral à ce sujet, cette hallucination a finalement été corrigée dans une mise à jour.
Finalement, Il est donc essentiel de rappeler qu’un modèle de langage ne doit pas être utilisé comme une source de référence unique. Il reste sujet à des erreurs, peut fournir des informations obsolètes et n'est pas infaillible. Par précaution, il vaut mieux vérifier ses réponses et s’assurer qu’il cite des sources lorsqu’il avance des faits importants.
5 - La gestion des données et la souveraineté numérique chez Mistral
La question de la souveraineté numérique soulève plusieurs défis pour les entreprises de technologie. Par exemple, Cerebras, une société américaine, effectue ses opérations d’inférence sur des serveurs basés aux États-Unis. Cela signifie que, lors de l’activation de Flash Answers, les données doivent traverser des frontières internationales, soulevant des préoccupations concernant la protection de la vie privée et la souveraineté des données.
Mais ce n’est pas le seul aspect à considérer. Actuellement, les données de Mistral AI sont hébergées sur des infrastructures cloud étrangères : Microsoft Azure en Suède, Google Cloud Platform (GCP) en Irlande, et pour la génération d’images, des serveurs dans la région de Black Forest, aux États-Unis, sont utilisés.
Bien que la politique de confidentialité de Mistral AI soit accessible en ligne (FR) Politique de confidentialité, celle-ci reste relativement floue sur plusieurs aspects.
Pour réduire sa dépendance aux infrastructures cloud étrangères, Mistral AI a annoncé la construction de son propre centre de données en Essonne. Une fois opérationnel, ce datacenter permettra à l’entreprise de mieux contrôler la gestion et la protection des données, renforçant ainsi sa souveraineté numérique.
Conclusion
Le Chat de Mistral, en combinant performance, rapidité d’inférence, s’impose aujourd’hui comme une solution européenne de premier plan dans le domaine des assistants conversationnels. Au-delà de ses performances, Mistral incarne une approche souveraine de l’intelligence artificielle : ses modèles peuvent être hébergés localement, offrant aux entreprises comme aux particuliers un contrôle total sur leurs données et leur infrastructure. La récente publication du modèle Mistral Small 3.1, plus compact et plus rapide, confirme cette volonté de proposer des modèles toujours plus accessibles, adaptables et performants y compris dans des environnements contraints. Une orientation stratégique qui ouvre la voie à de nouveaux usages : plus respectueux de la vie privée, plus économes en ressources, et surtout plus maîtrisés.
Pour aller plus loin, découvrez comment exploiter l’IA open-source avec Hugging Face : Open source AI avec Hugging Face
FAQ
Le Chat de Mistral est-il gratuit ?
Oui, Le Chat propose une version gratuite accessible sans compte sur le site de Mistral AI. Une version Pro payante est disponible avec accès prioritaire aux modèles les plus récents et des limites d'utilisation plus élevées.
Le Chat vs ChatGPT : lequel choisir ?
Le Chat se distingue par sa vitesse exceptionnelle (Flash Answers via Cerebras) et son positionnement open-source et européen. ChatGPT dispose d'un écosystème de plugins plus mature. Pour un usage professionnel en entreprise européenne soucieuse de souveraineté des données, Le Chat est souvent préféré.
Pourquoi Le Chat est-il plus rapide que ChatGPT ?
Le Chat utilise les chips Cerebras (wafer-scale) qui traitent les tokens en parallèle sans les bottlenecks de communication entre GPU NVIDIA. Cela permet des vitesses supérieures à 1 100 tokens/s, contre 80-100 tokens/s pour les concurrents basés sur GPU classiques.
Bibliographie
Cerebras. (n.d.). Mistral Le Chat. Cerebras Blog. (https://cerebras.ai/blog/mistral-le-chat)
Hackster.io. (2024). Cerebras Wafer Scale Engine 3: The fastest AI chip in the world aims at rapid Gen AI training. (https://www.hackster.io/news/cerebras-wafer-scale-engine-3-the-fastest-ai-chip-in-the-world-aims-at-rapid-gen-ai-training-5a383ee49a97)
Hugging Face. (2024). Mistral Large Instruct 2411 – Model repository. (https://huggingface.co/mistralai/Mistral-Large-Instruct-2411/tree/main)
Hugging Face. (2024). FLUX.1-dev – Black Forest Labs. (https://huggingface.co/black-forest-labs/FLUX.1-dev)
Mistral AI. (n.d.). Le Chat – AI-powered chatbot.
(https://mistral.ai/fr/products/le-chat)
Mistral AI. (n.d.). Pixtral Large: New multi-modal AI model. (https://mistral.ai/fr/news/pixtral-large)
Mistral AI. (n.d.). Models Overview – Mistral AI Documentation. (https://docs.mistral.ai/getting-started/models/models_overview/)
Mistral AI. (n.d.). MRL-0.1 License.
(https://mistral.ai/static/licenses/MRL-0.1.md)
Black Forest Labs. (n.d.). 1.1 PRO – Next-gen AI model.
(https://blackforestlabs.ai/1-1-pro/)
Zhang, X., Smith, J., & Doe, J. (2024). Efficient Transformer Architectures for AI Scaling. arXiv preprint.
(https://arxiv.org/pdf/2410.07073)