L'observabilité au temps des LLM apps
Introduction
Henry Jammes, responsable principal de l'IA conversationnelle chez Microsoft, estime que 750 millions d’applications utilisant des modèles de langage (LLM) devront être développées d’ici fin 2025.
Les LLMs sont des modèles statistiques, par nature complexes et parfois imprévisibles. Ajoutez à cela une myriade d’outils potentiellement connectables au LLM et vous obtenez des architectures tentaculaires.
Dans ce contexte d’explosion des applications basées sur les modèles de langage, garantir leur fiabilité, leur performance et leur compréhension devient crucial. C’est là que deux notions entrent en jeu pour surveiller ces systèmes :
- l'observabilité qui répond à la question “pourquoi ça ne va pas ?” - alors que le monitoring répond à la question en amont “sait-on que quelque chose ne va pas ?”.
- et l’évaluation qui répond à la question “quelle note obtient mon application sur le banc de test ?”
Deux notions complémentaires pour garder le contrôle sur des systèmes toujours plus complexes.
Les acteurs du marché l’ont bien compris puisqu’on a vu depuis fin 2022 (sortie de ChatGPT) l’apparition d’une quinzaine d’outils d’observabilité et d’évaluation spécialement conçus pour les applications utilisant des LLMs [1] [2]
Dans cet article nous allons voir comment l’émergence des LLMs a rebattu les cartes du concept d’observabilité dans les applications et quelles sont les solutions naissantes pour pallier cette complexité nouvelle.
L’observabilité d’une application
Généralités
Le concept d’observabilité prend ses origines en théorie du contrôle, c'est-à-dire l’étude mathématique des systèmes. C’est une mesure de l'efficacité avec laquelle les états internes d'un système peuvent être déduits de la connaissance de ses sorties externes.
En termes simpliste c’est voir la fumée qui sort du capot de votre voiture et se dire qu’il y a un souci avec le moteur.
Les logs, métriques, traces sont souvent définis comme les trois piliers de l’observabilité. Il est pertinent de revoir ensemble ces notions car elles sont souvent sources de confusion entre les développeurs.
- Logs: Un log est un enregistrement immuable, structuré et horodaté d'événements discrets qui se sont produits au fil du temps. Il se compose généralement d'un horodatage, d'un contenu textuel et très souvent un niveau de sévérité.
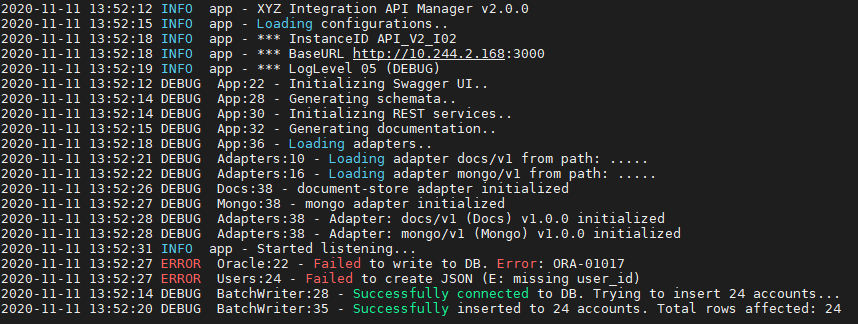
Exemple de logs
- Métriques: Les métriques sont une représentation numérique de données mesurées sur des intervalles de temps. Les métriques permettent d'exploiter des fonctions mathématiques, pour obtenir une connaissance du système sur des intervalles de temps passés, ou en mode prédictif sur des comportements à venir.
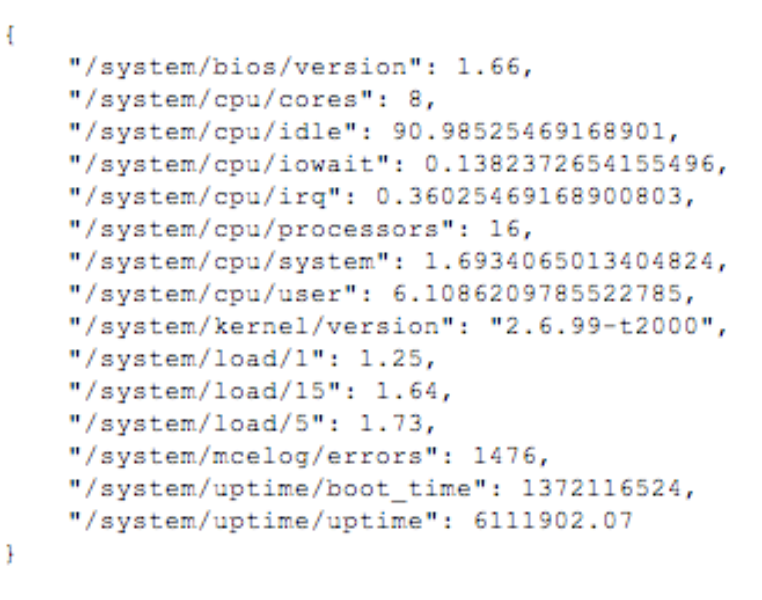
Quelques métriques système
- Traces: Une trace est une représentation d'une série d'événements distribués ayant un lien de causalité et qui encodent le flux de requêtes de bout en bout à travers un système distribué.
Une seule trace peut fournir une visibilité à la fois sur le chemin parcouru par une requête et sur la structure d'une requête. Le chemin parcouru par une requête permet aux ingénieurs logiciels et aux SRE de comprendre les différents services impliqués dans le chemin parcouru par une requête, et la structure d'une requête permet de comprendre les points de jonction et les effets de l'asynchronisme dans l'exécution d'une requête.
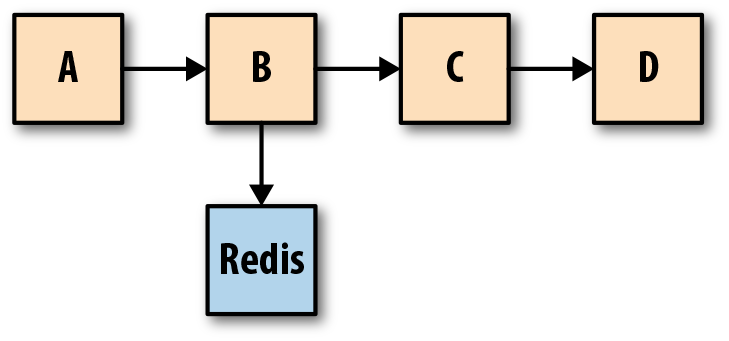
Le diagramme d’une trace
Dans le monde la gestion de risque on dit souvent que l’observabilité permet de traiter les “unknown unknowns”, c’est à dire, d’après Nishant Kabra dans The Future of Monitoring, “ les menaces et potentiels problèmes qui restent invisibles jusqu’à ce que leur impact se manifeste”**.
Ainsi l’observabilité peut se définir, à l’aide des trois piliers susmentionnés, comme la capacité d’un système à identifier ces problèmes inconnus.
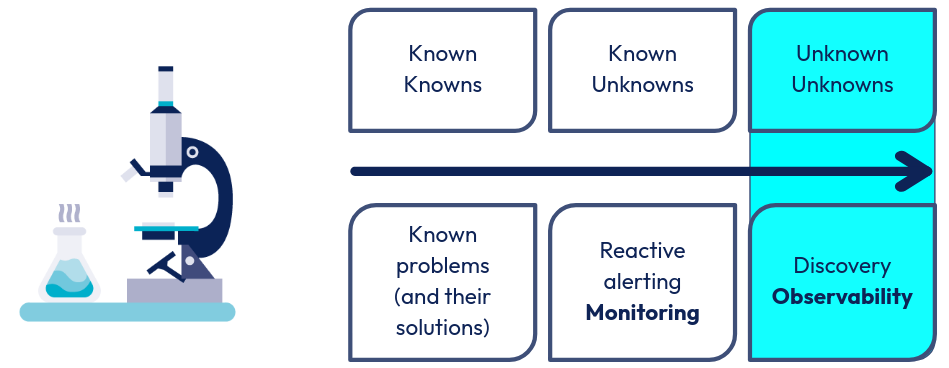
Une façon de voir l’observabilité
Mais pour pouvoir poser ces questions, encore faut-il que les données soient accessibles et transportées de manière fiable entre les systèmes.
C’est précisément ce que propose le standard OpenTelemetry (Open pour open-source, Tele pour à distance, Metry pour mesure) qui permet d’uniformiser la collecte et l'échange des données de télémétrie, comme les traces, les logs et les métriques.
Ce standard définit un protocole de communication nommé OTLP, qui sert à collecter et à transmettre les données. Il inclut également des APIs précises, ainsi que des SDK permettant d'instrumenter les applications, c’est-à-dire d’ajouter dans le code les points de collecte nécessaires pour observer leur comportement en temps réel.
Ainsi tous les outils d’instrumentation pour les applications LLMs utilisent le protocole OpenTelemetry pour collecter et échanger des données de télémétrie. Certaines bibliothèques offrent même une instrumentation automatique.
Grâce à OpenTelemetry, on dispose d’un socle commun pour les données de télémétrie. Mais avant d’expliquer comment exploiter pleinement ces données dans une app LLM faisons un pas en arrière pour voir ensemble les approches connues de monitoring dans le monde du Software Engineering.
Monitoring white box et monitoring black box comme briques d’une observabilité complète
Avant l’ère des LLM, deux approches de monitoring complétaient la panoplie DevOps : le monitoring black box (boîte noire) et le monitoring white box (boîte blanche). Le black box monitoring consiste à superviser une application du point de vue externe, exactement comme le ferait un utilisateur. On vérifie par exemple qu'une API renvoie les bonnes réponses, que le site web reste accessible ou que des scénarios fonctionnels aboutissent correctement. Il s’agit d’une approche centrée sur les symptômes observables de l’extérieur (est-ce que le service répond comme attendu du point de vue utilisateur ?).
En revanche, le white box monitoring vise l’interne : on instrumente les composants pour collecter des métriques détaillées (compteurs, logs internes, états) afin de détecter proactivement des anomalies ou des goulots d’étranglement en se demandant comment le système fonctionne-t-il en interne ? Dans un système traditionnel, combiner les deux approches est idéal : le black box détecte les problèmes visibles en production, tandis que le white box permet d’agir en amont en surveillant la santé interne du système.
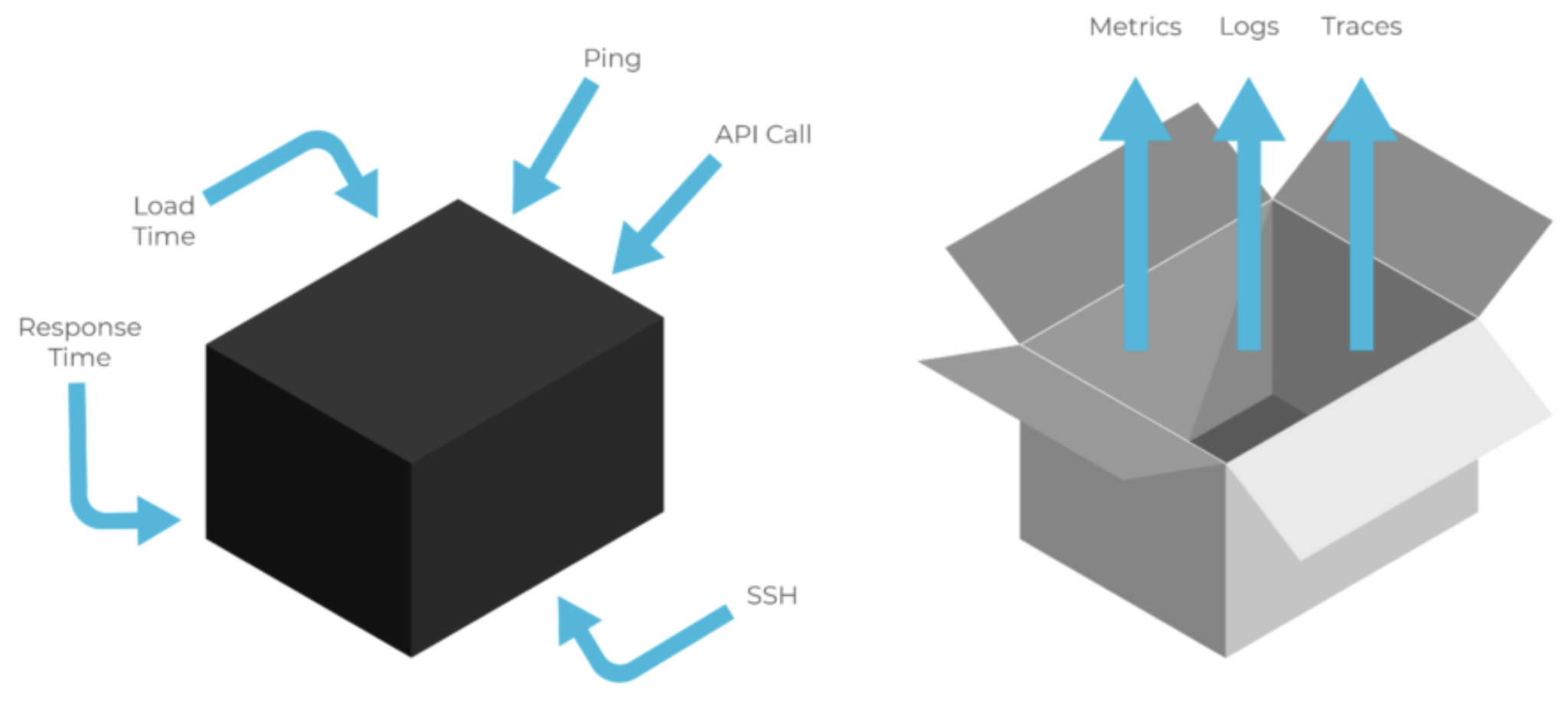
Black box monitoring vs. white box monitoring [3]
L’observabilité dans le monde des LLMs
La structure opaque d’une app LLM
Est-ce que ces briques sont réalisables dans le contexte d’une app LLM ?
Cette question se pose rapidement à toute équipe intégrant un LLM : peut-on monitorer le modèle de l’intérieur, ou doit-on le traiter comme une boîte noire absolue ? La réponse dépend en grande partie de l’hébergement du modèle et de son degré d’accessibilité :
- LLM via API publique hébergée (ex. OpenAI, Azure OpenAI, Anthropic…) :
Dans ce cas, le modèle est fourni comme service externe. Vous envoyez des prompts et recevez des complétions, sans accès aux mécanismes internes du modèle. Le monitoring se limite aux métriques exposées par le fournisseur (nombre de requêtes, tokens consommés, temps de réponse, taux de contenu bloqué), adoptant ainsi une approche purement black box qui observe uniquement les entrées et sorties. - LLM auto-hébergé (ex. LLaMA, Mistral, Falcon…) :
Ici, vous disposez d’un contrôle total de l’environnement d’exécution. Cela permet de surveiller les ressources système (CPU/GPU, mémoire, temps de calcul par token) et d’instrumenter en partie la logique d’inférence, par exemple en mesurant la perplexité ou en récupérant la distribution des probabilités (logits) des tokens générés. Des outils d’interprétabilité (visualisation d’attention, détection de neurones activés) peuvent également être utilisés, bien que leur usage reste plus exploratoire qu’opérationnel.
En dépit de ces possibilités, il faut souligner que même autohébergé, le LLM reste en grande partie une boîte noire dans son raisonnement. On ne dispose pas de logs métier internes décrivant « pourquoi » il a produit telle phrase comme on le ferait avec un code applicatif instrumenté. Le monitoring white box au sens strict (surveiller pas à pas la logique interne) n’est donc pas réalisable, à moins d’avoir un modèle spécialement instrumenté pour cela.
D’après le site d’Arize AI - “L’observabilité LLM est une visibilité complète de chaque couche d'un système logiciel basé sur LLM : l'application, le prompt et la réponse”, mais pas le modèle en lui-même. On se trouve donc dans un cas où une certaine partie de la boîte peut être éclairée (tout ce qui s’interface avec le LLM) et l’autre partie reste opaque (tout ce qui se trouve à l’intérieur du LLM), en bref certains microservices sont observables et d’autres non, on pourrait parler ici de monitoring grey box.
Comment “éclairer” cette partie opaque du système ? Il faut chercher à capter les signaux pertinents qui entrent et sortent du LLM. Voici quelques idées constituant une liste non exhaustive de ce qu’il faut instrumenter dans une application LLM.
- Prompt : ce qui est envoyé au LLM
- Réponse : ce que retourne le LLM sous forme lisible
- Embeddings : ce que retourne le LLM (ou un autre modèle d’embedding utilisé dans l’app) sous forme vectorielle
- Base de donnée / API externe : ce que le LLM peut requêter
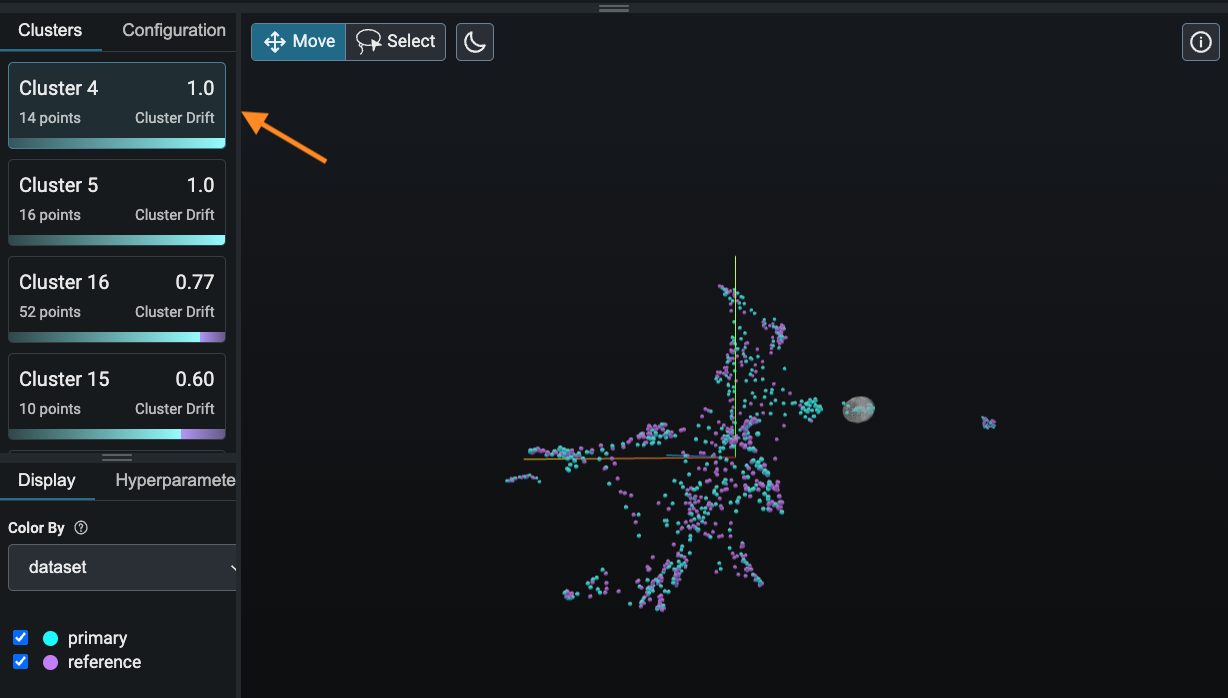
Représentation 3D des embeddings (représentation vectorielle)
Sur l’image ci-dessus un outil d’observabilité permet d’observer des embeddings présents dans une app LLM dans un espace en 3 dimensions. Cela permet d’analyser leur répartition dans l’espace afin d’expliquer des causes de comportements observés en run.
Les erreurs silencieuses
En plus de cette opacité, la nature même des données générées par un LLM est problématique d’un point de vue de l’observabilité. En effet, contrairement à un microservice classique, un LLM ne loggue pas d’exception lorsqu’il "se trompe". Une réponse peut avoir l’air parfaitement structurée, tout en étant factuellement fausse ou inappropriée. Ces erreurs sans signal technique sont les plus pernicieuses. Il est donc nécessaire de compléter le monitoring technique par du contrôle qualité métier. L’opacité interne du modèle fait qu’on ne dispose pas d’indicateur de confiance natif. On ne sait pas si le modèle est sûr de lui ou non sur une réponse donnée. C’est un défi pour le debugging : si l’application produit une sortie erronée, on ne peut pas inspecter une pile d’appel ou des variables internes pour trouver l’endroit où ça a dévié – il faut souvent mener une enquête plus complexe, en rejouant le prompt, en testant des variantes, etc. Cette opacité incite à collecter davantage de données contextuelles (d’où l’intérêt de tracer tout l’enchaînement d’un agent par exemple) pour pouvoir raisonner a posteriori sur les causes possibles d’un raté.
C’est pour cette raison que nous proposons dans cet article un quatrième pilier à la définition d’observabilité. Ce pilier, c'est l’évaluation. Comme nous allons le voir dans la partie suivante, ce pilier se base sur l’étude de métriques particulières spécifiques aux LLM.
Évaluation
Évaluer pour déployer en confiance
Déployer une application utilisant un LLM en production n’est jamais un processus figé. Même lorsqu’un modèle répond parfaitement aux tests initiaux, il peut rapidement dériver ou régresser sous l'effet des évolutions constantes des données d’entrée, des connaissances obsolètes, des mises à jour discrètes du modèle ou bien dû à la simple évolution de l’application elle-même.

Déployer une application utilisant un LLM en production
Les LLMs génèrent des résultats non déterministes dans des contextes réels, comme les hallucinations aussi connues sous le nom de “confabulations” (production imaginaire venant combler une lacune de mémoire), qui nuisent à l’expérience utilisateur et posent des risques majeurs. Ainsi, une évaluation régulière permet de détecter rapidement les anomalies, assurant que le modèle reste précis, pertinent et sûr à mesure que l’application se développe. Cette évaluation peut se faire sur la version en cours de développement (phase de build) ou sur la version aux mains des utilisateurs finaux (phase de run).
Pour évaluer une application LLM, il faut constituer un dataset avec des prompts et une vérité terrain (ground truth) associée. Selon la tâche, cela peut être une réponse correcte, une note de qualité, ou un label (ex. : “toxique / non toxique”). Idéalement, il combine un large panel de cas réels, critiques et piégeux.
Il existe plusieurs approches complémentaires :
Tests fonctionnels : vérifient que l'application suit les bonnes étapes et retourne des sorties attendues pour des entrées précises.
Tests de régression : comparent les comportements d’une version à l’autre (prompts, outils, modèles), pour détecter les dérives ou pertes de performance sur des workflows critiques.
Évaluations qualitatives : basées sur des critères comme la clarté, la pertinence, la factualité ou le style. Réalisées par des annotateurs humains ou via LLM.
Tests comportementaux et adversariaux : entrées piégeuses, ambiguës ou malveillantes visant à tester les failles logiques, les hallucinations ou les vulnérabilités de sécurité.
Validation des garde-fous (guardrails) : vérifient que les règles de sécurité (filtrage, blocage, contraintes métier) sont respectées.
Évaluation humaine (boucle de rétroaction utilisateur) : feedback utilisateur en production, via notation ou signaux implicites (engagement, clics, rejets, etc.).
L’évaluation s’appuie sur les données rendues accessibles par l’observabilité : logs d’entrées/sorties, traces d’exécution, métriques système (latence, coût, usage GPU), et feedback utilisateur. Ces artefacts permettent de construire, de suivre la performance au fil du temps, et de détecter les dérives.
Contrairement aux systèmes classiques, l’évaluation d’une application LLM ne peut pas se limiter à des métriques quantitatives standard, elle doit intégrer des dimensions qualitatives. En combinant observabilité fine et évaluation continue, on obtient un levier pour développer des systèmes fiables, sûrs et adaptatifs.
Le LLM comme évaluateur (LLM as a Judge)

LLM as a Judge
Pour certaines évaluations qualitatives, il est possible d’utiliser des LLMs afin d’évaluer une application basée elle-même sur des LLMs (un LLM qui évalue un ou des LLMs), une approche appelée "LLM-as-a-Judge". Elle permet une évaluation rapide et cohérente des données de sorties, améliorant l'efficacité et la reproductibilité des évaluations. Elle réduit le coût d'évaluation qui auparavant était supportée par des humains.
Cependant, cette méthode comporte des risques. Les LLM peuvent présenter des biais, favorisant par exemple les réponses d’un même modèle ou reflétant une préférences pour les réponses plus verbeuses. De plus, l’évaluateur peut manquer de compréhension contextuelle, menant à des évaluations superficielles. Cette pratique sera aussi dépendante du LLM choisi et peut donc représenter un coût d’évaluation variable.
Pour atténuer ces risques, il est recommandé de superviser cette évaluation et de la combiner avec des évaluations humaines, assurant ainsi une analyse plus complète et nuancée. Il est aussi possible de spécialiser (fine-tune et/ou reinforcement learning) un LLM pour des évaluations critiques afin de garantir un résultat stable, cohérent et aligné avec les attentes, à condition bien entendu de posséder les ressources nécessaires. [4] [5] [6]
Exemple d’application : observabilité et évaluation d’une application RAG
Après avoir présenté l’observabilité et les évaluations dans le cadre des applications LLMs, nous voulons désormais illustrer nos propos avec une méthodologie d’instrumentation et d’évaluation appliquée à une application RAG. Cette technique permet d’enrichir les questions posées à un LLM avec des connaissances issues d'une base documentaire afin d'améliorer la pertinence des réponses générées.
Cette méthodologie se divise en 5 étapes :
- Étape 1 : récupération des logs, métriques et traces du RAG via une instrumentation du code applicatif ;
- Étape 2 : exportation des logs, métriques et traces vers une interface de visualisation ;
- Étape 3 : réalisation des évaluations du RAG ;
- Étape 4 : Ajout des évaluations dans l’interface créée dans l’étape 2 ;
- Étape 5 : Analyse des données de chaque pilier (logs, traces, métriques, évaluations) pour, en fonction des observations réalisées, améliorer ou modifier le RAG et son code applicatif.
La plupart des outils d'observabilité proposent leur propre interface visuelle pour analyser efficacement les traces, logs et métriques en temps réel. Cependant, si l’on désire implémenter nous même une interface personnalisée, il est totalement possible de réaliser cela grâce à des outils comme Grafana. Voici des exemples d’interfaces visuelles présentant des traces d’appels à un RAG ainsi que leurs métriques :
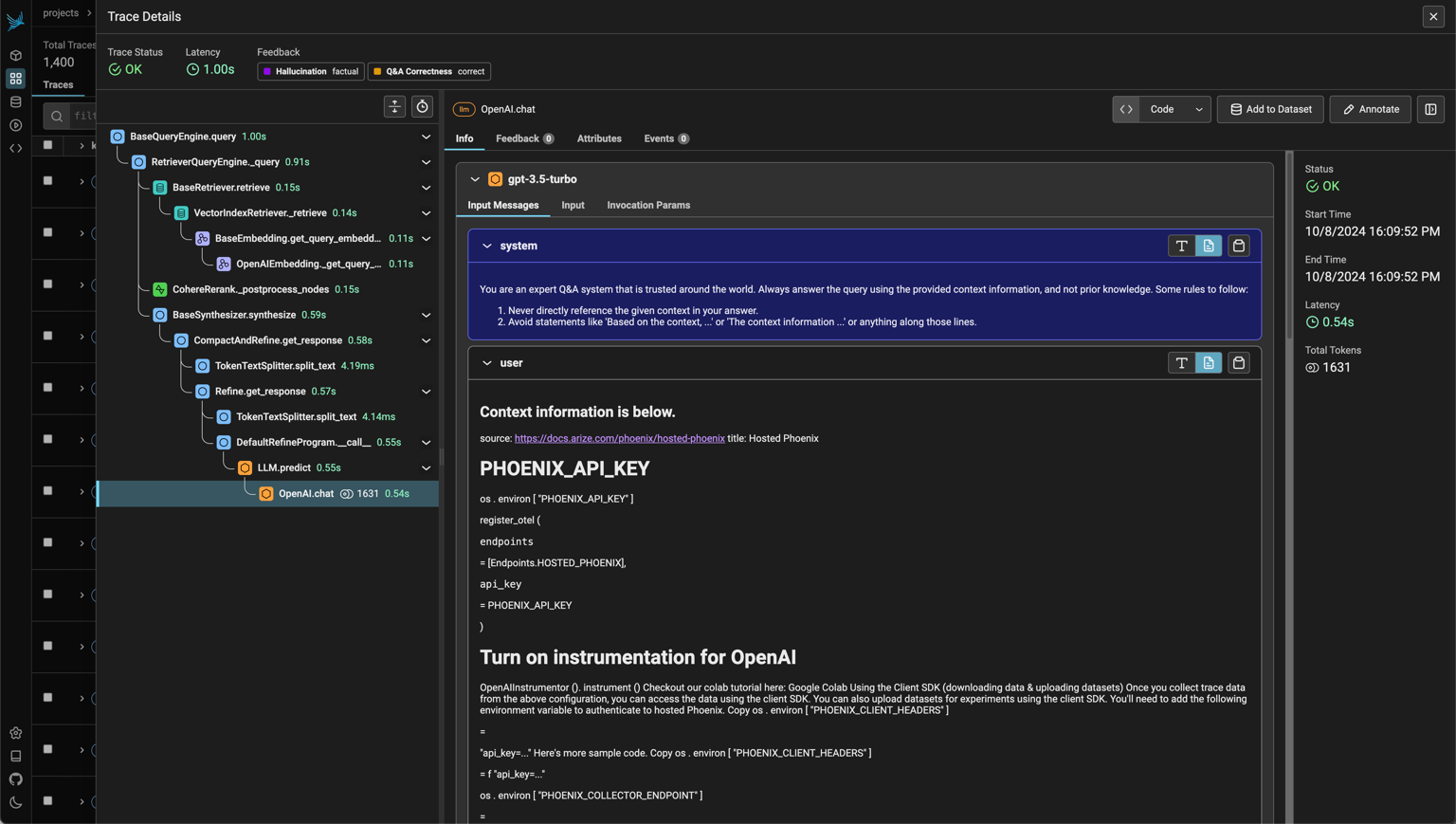
Screenshot de l’interface de Phoenix représentant une trace d’une application RAG avec son workflow et ses inputs/outputs
Concernant les différents types d’évaluations listés dans la partie précédente, deux approches complémentaires existent : utiliser directement les fonctionnalités intégrées dans l’outil d’observabilité ou exploiter des librairies externes spécialisées.
Dans le cas d’un RAG, les évaluations ciblent principalement deux aspects de l'application ayant chacun des métriques data science (à ne pas confondre avec la notion de métrique présente dans l’observabilité) :
La partie récupération de contexte : Est-ce que le contexte récupéré est pertinent pour la question ? Une des métriques connues est la Mean Reciprocal Rank (MRR)
La partie génération de contenu : Est-ce que la réponse est pertinente ? Parmi les métriques usuelles, on trouve la faithfulness, la response relevancy mis en avant par la librairie RAGAS
Ces résultats d'évaluations peuvent ensuite être intégrés à l'interface d'observabilité afin d'offrir une vue consolidée permettant une analyse approfondie de la solution mise en place. Voici un exemple d’interface intégrant pour chaque trace d’un RAG des évaluations :
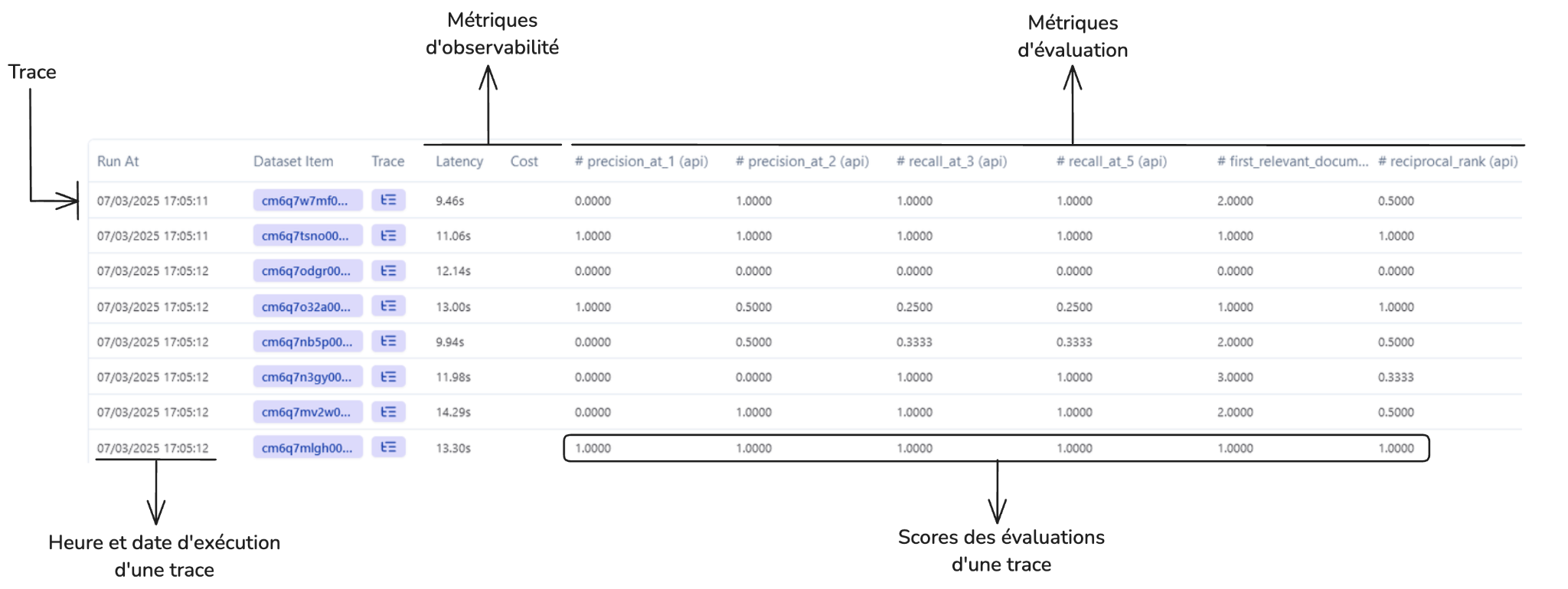
Screenshot d’un interface présentant différentes traces et leurs évaluations
Grâce à cette instrumentation complète et aux évaluations réalisées, il est désormais possible d'identifier les faiblesses et points d'amélioration de l'application ainsi que leurs causes. On pourrait donc utiliser ces observations pour mettre en place l’EDD (Evaluation Driven Development). L’EDD [7] se positionne comme une évolution du TDD dans les projets intégrant des LLMs.
Pour notre exemple, imaginons que notre solution ne génère pas des réponses satisfaisantes par rapport à la question de l’utilisateur. On pourrait alors décider d’analyser les traces et remarquer que la récupération de contexte ne retourne pas les bons documents. Cette observation nous permettrait ensuite de décider de concentrer nos efforts sur l’amélioration de cette partie.
Conclusion
L’apparition des LLMs redéfinit la façon de surveiller et de diagnostiquer nos architectures d’applications. De par leur complexité, il devient indispensable d’adopter une approche rigoureuse pour garantir leur bon fonctionnement et leur amélioration continue. L’observabilité avec évaluation ne doit plus être perçue comme une option, mais comme une fondation incontournable pour toute application LLM en production.
L’observabilité des apps LLM, avec l’évaluation comme un de ses piliers, permet de mieux comprendre les comportements internes et externes d’une app LLM, même dans des architectures partiellement opaques.
Nous retenons que la qualité d’une évaluation ne repose pas sur l’outil choisi, mais sur la clarté des hypothèses qu’on cherche à valider, et sur la pertinence des signaux qu’on collecte. Une instrumentation bien pensée, alignée sur les dimensions critiques de l’application (ex. : factualité, robustesse, coût), a plus d’impact que le choix d’un outil en particulier. Par exemple, des méthodes comme LLM-as-a-Judge peuvent accélérer les cycles d’itération, mais ne remplacent pas une réflexion sur ce qu’on cherche à mesurer, ni l’intervention humaine quand l’évaluation devient trop contextuelle.
Les applications LLM ne peuvent pas être "parfaites" au sens traditionnel : elles opèrent dans un espace flou, avec des sorties non déterministes, une logique implicite et des critères de qualité souvent ambigus. C’est précisément pour cette raison que l’instrumentation, l’évaluation ciblée, et le feedback continu ne sont pas des bonus, mais des mécanismes structurels pour comprendre, contrôler et faire évoluer ces systèmes de manière fiable.
A suivre
Dans notre prochain article, nous présenterons une sélection d’outils d'observabilité que nous avons expérimentés, afin de vous aider à choisir parmi l’offre croissante.
Bibliographie
[1] Coralogix. (2025, 27 février). 10 LLM Observability Tools to Know in 2025 - Coralogix. https://coralogix.com/guides/aiops/llm-observability-tools/
[2] Dilmegani, C. (2025, 6 avril). Top 40+ LLMOps Tools & Compare them to MLOPs in 2025. AIMultiple. https://research.aimultiple.com/llmops-tools/
[3] Multi-Cloud Monitoring: A Cloud Security Essential. (2023, 2 février). Multi-Cloud Monitoring: A Cloud Security Essential https://www.meshcloud.io/en/blog/multi-cloud-monitoring-a-cloud-security-essential/
[4] Yu, J., Sun, S., Hu, X., Yan, J., Yu, K., & Li, X. (2025, 17 février). Improve LLM-as-a-Judge Ability as a General Ability. arXiv.org. https://arxiv.org/abs/2502.11689
[5] Hu, R., Cheng, Y., Meng, L., Xia, J., Zong, Y., Shi, X., & Lin, W. (2025). Training an LLM-as-a-Judge Model : Pipeline, Insights, and Practical Lessons. arXiv (Cornell University). https://doi.org/10.1145/3701716.3715265
[6] Liu, Z., Wang, P., Xu, R., Ma, S., Ruan, C., Li, P., Liu, Y., & Wu, Y. (2025, 3 avril). Inference-Time Scaling for Generalist Reward Modeling. arXiv.org. https://arxiv.org/abs/2504.02495
[7] Xia, B., Lu, Q., Zhu, L., Xing, Z., Zhao, D., & Zhang, H. (2024, 21 novembre). Evaluation-Driven Development of LLM Agents : A Process Model and Reference Architecture. arXiv.org. https://arxiv.org/abs/2411.13768
Inspirations
La Grosse Conf. (2025, 18 mars). LLMOps, on s’y met tout de suite ? - Ali El Moussawi [Vidéo]. YouTube. https://www.youtube.com/watch?v=JIj16o-PErU
Beyond the AI MVP : What it really takes. (2025, 1 février). Lawrence Jones. https://blog.lawrencejones.dev/ai-mvp/