IA générative et réchauffement climatique : comment réduire la facture ?
Vous êtes-vous déjà demandé combien consomment réellement vos projets intégrant de l’IA générative ? Et surtout, comment en réduire l’impact environnemental ?
Ces questions ont été au cœur d’une série de conférences que nous avons animées ces derniers mois dans plusieurs villes en France : 🎬 IA générative et réchauffement climatique : comment réduire la facture ?
Cet article se veut une synthèse des principaux enseignements partagés lors de ces interventions :
- quelques constats sur l’impact environnemental de l’IA générative
- et surtout des bonnes pratiques pour les réduire dans des contextes projets.
📚 En fin d’article, vous trouverez également un ensemble de ressources pour initier une démarche Green AI dans vos cas d’usage.
Commençons par une petite question.
Lors d’une conversation avec ChatGPT (5-15 messages générant des réponses de 400 tokens en moyenne pour GPT-4o), à votre avis, cela correspond à :
- A. 5 cl d’eau (une tasse d’expresso)
- B. 50 cl (une petite bouteille)
- C. ou 5 litres (un arrosoir) ?
Les chiffres exacts n’étant pas publics, nous nous sommes basées sur des données publiées par Mistral et OpenAI afin d’estimer un ordre de grandeur de la consommation d’eau associée à une conversation avec GPT-4o, d’environ 10 requêtes, générant en moyenne 400 tokens par message.
Pour un modèle comme GPT-4o d’OpenAI, on se situerait plutôt autour de la réponse B : 50cl (une petite bouteille).
Selon les chiffres publiés par Mistral, une requête avec Mistral Large 2 (123 milliards de paramètres) consommerait environ 0,05 L d’eau. Une conversation de 10 messages représenterait environ 50 cl d’eau. Nous avons ensuite extrapolé vers GPT-4o en nous appuyant sur des hypothèses issues de sources publiques (source Ecologits), qui supposent un ordre de grandeur comparable en termes de paramètres actifs.
Cette estimation vise à illustrer un ordre de grandeur. Elle peut varier selon les différences d’infrastructure et d’exploitation, dont les données ne sont pas publiques. L’enjeu principal reste celui de l’effet d’échelle.
À l’échelle individuelle, une petite bouteille d’eau peut paraître peu. Mais si l’on ramène ce chiffre aux 2,6 milliards de requêtes quotidiennes (source OpenAI) générées par les 800 millions d’utilisateurs hebdomadaires dans le monde (source OpenAI), l’addition change d’échelle, on passe à des dizaines de milliards de litres d’eau par an. Et cela ne concerne qu’un seul modèle, en production, chez un seul acteur, et donc une part très limitée de l’écosystème global de l’IA.
Par ailleurs, l’analyse du coût environnemental d’un système est multicritère : en plus de la consommation d’eau, il faut aussi prendre en compte la consommation énergétique, les émissions de gaz à effet de serre associées, ainsi que l’extraction des ressources nécessaires à la fabrication des infrastructures (GPU, serveurs, data centers).
Pourquoi parle-t-on d’eau lorsqu’on évoque l’IA générative ? C’est parce que les installations qui permettent à ces systèmes de fonctionner doivent être constamment refroidies. Les modèles d’IA fonctionnent grâce à des serveurs très puissants, installés dans des data centers, qui consomment beaucoup d’électricité et produisent beaucoup de chaleur. Pour éviter la surchauffe, ces centres utilisent des systèmes de refroidissement, souvent à base d’eau, car elle permet d’absorber efficacement la chaleur. Elle circule dans des circuits fermés ou alimente des tours de refroidissement afin de maintenir une température stable. L’eau ne sert donc pas à « créer » l’IA, mais à assurer le bon fonctionnement des équipements qui la rendent possible. (The Water Footprint Of Data Center Workloads : A Review Of Key Determinants, 2025)
L’enjeu n’est pas de renoncer à l’IA générative, mais de l’implémenter, de la structurer et de l’exploiter de manière responsable.
Commençons par quelques constats.
L’IA forcing : une stratégie qui booste la demande
Depuis l’arrivée de ChatGPT en novembre 2022, le nombre d’outils d’intelligence artificielle a explosé. En parallèle, l’IA générative s’est intégrée aux outils que nous utilisions déjà sans IA : moteurs de recherche, logiciels, plateformes en ligne. Ces fonctionnalités, souvent mises en avant par de petites étoiles ou boutons visibles dès l’accueil, nous incitent fortement à les utiliser.

Image extraite de : Le forcing de l’IA, Limites Numériques 2024.
Prenons deux exemples pour illustrer ce propos :
Exemple 1/ Aujourd’hui si vous ouvrez un document sur Adobe, avant même d’avoir accès au contenu de ce document, on va vous proposer d’utiliser un Assistant IA pour chatter avec ce document.
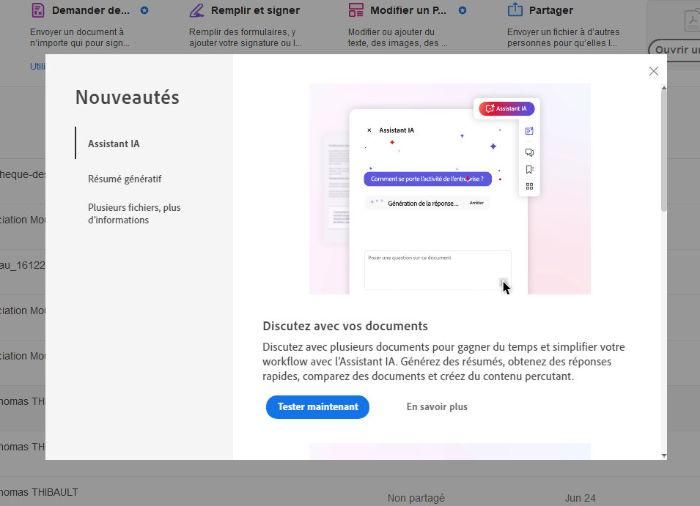
Image extraite de : Le forcing de l’IA, Limites Numériques 2024.
Exemple 2/ Aujourd’hui si vous faites une recherche internet avec Qwant, cette recherche internet est forcément couplée avec une requête envoyée à une IA Conversationnel par défaut.
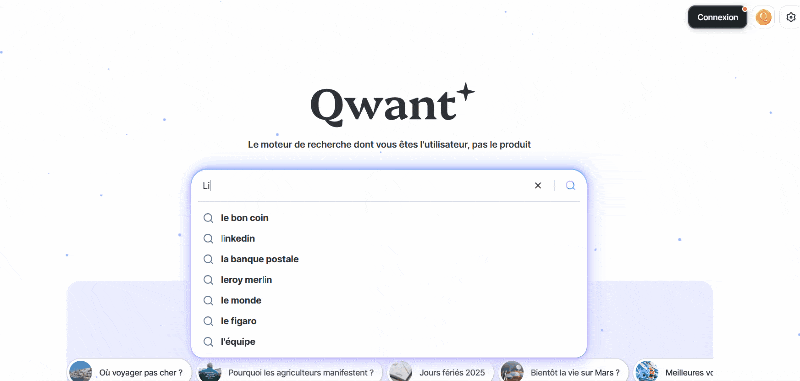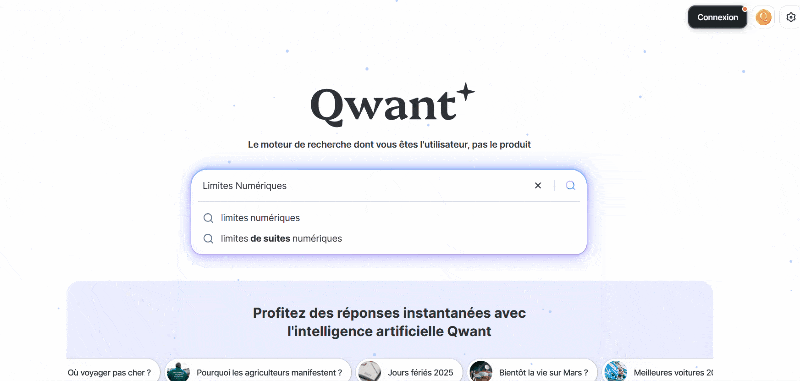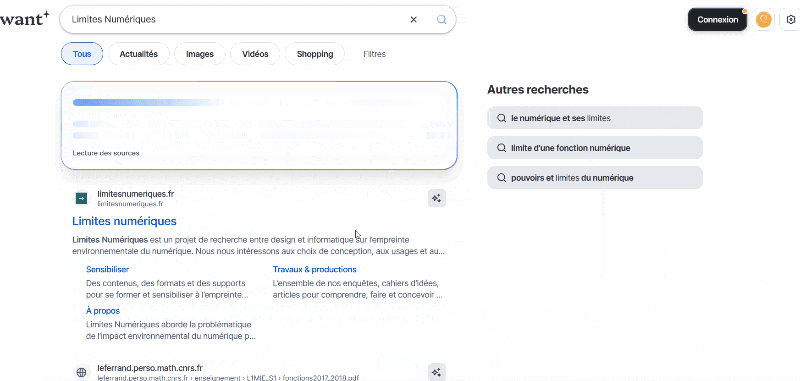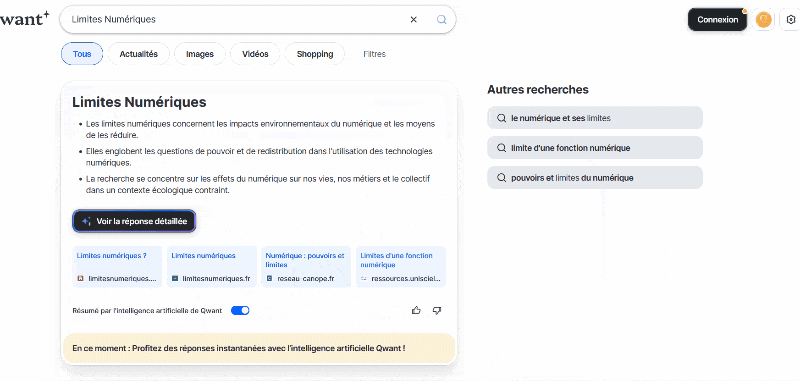
Image extraite de : Le forcing de l’IA, Limites Numériques 2024.
Et ce ne sont pas les deux seuls exemples : Linkedin, Notion, Messenger, Google Play Store…ont également adopté cette fonctionnalité.
Cette tendance, qui consiste à pousser les utilisateurs à recourir à l’IA, à nous forcer à l’utiliser sans même nous en rendre compte, est appelée « AI Forcing ».
C’est un sujet sur lequel se sont penchés des chercheurs français (Le Forcing de L’IA, 2024) : la manière dont les entreprises poussent à l’adoption de l’IA par le design de l’interface utilisateur et qui stimule artificiellement la demande.
L’explosion du marché de la GenAI éloigne l’industrie des objectifs climatiques
L’IA est déjà très présente dans notre quotidien mais certaines projections indiquent que le marché mondial de l’IA générative pourrait être multiplié par cinq d’ici 2030 par rapport à 2025, pour atteindre près de 400 milliards de dollars.
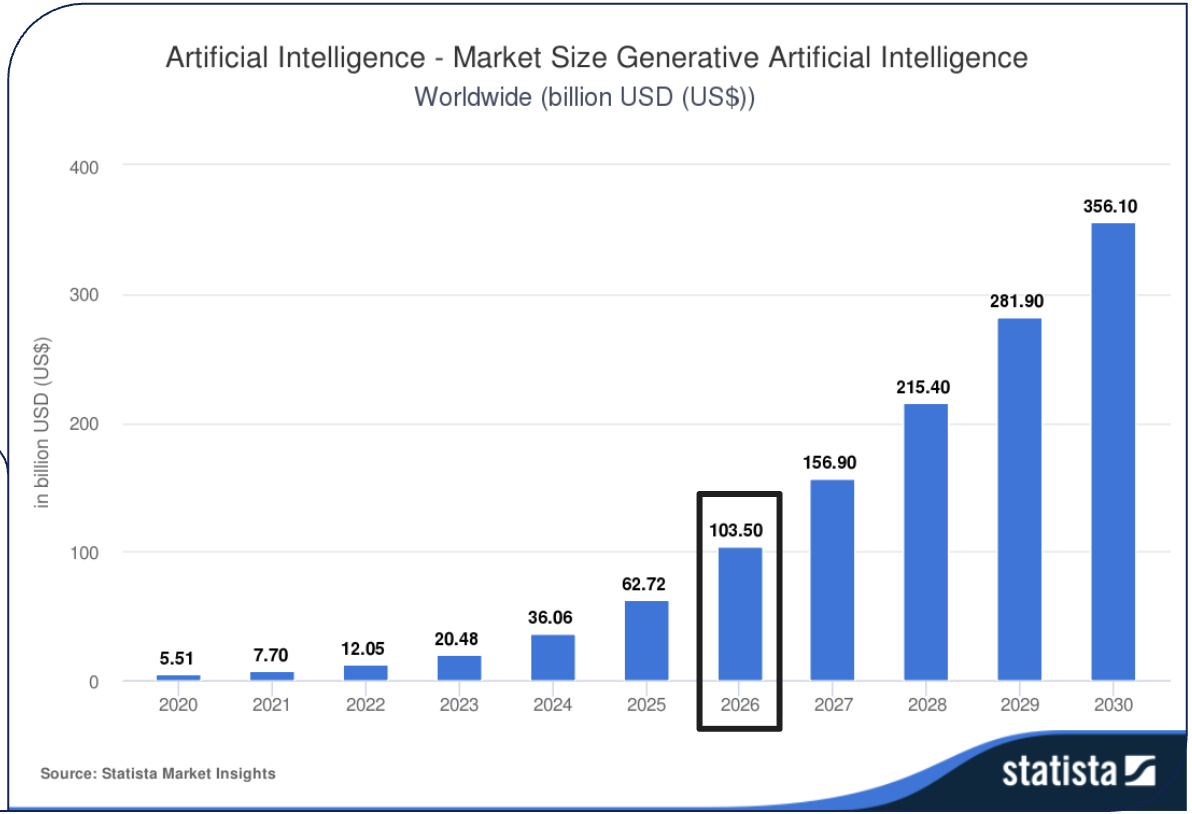
Extrait de la conférence (source Market Size Generative Artificial Intelligence – Statista Market Insights accessible dans cet article)
Avant l’arrivée de l’IA les GAFAM étaient dans une bonne dynamique pour atteindre une neutralité carbone en 2030 (basée sur des mécanismes compensatoires) (source Bloomberg), et depuis 2021-2023 la tendance s’est complètement inversée : la course à l’IA générative a éloigné l’industrie des objectifs climatiques.
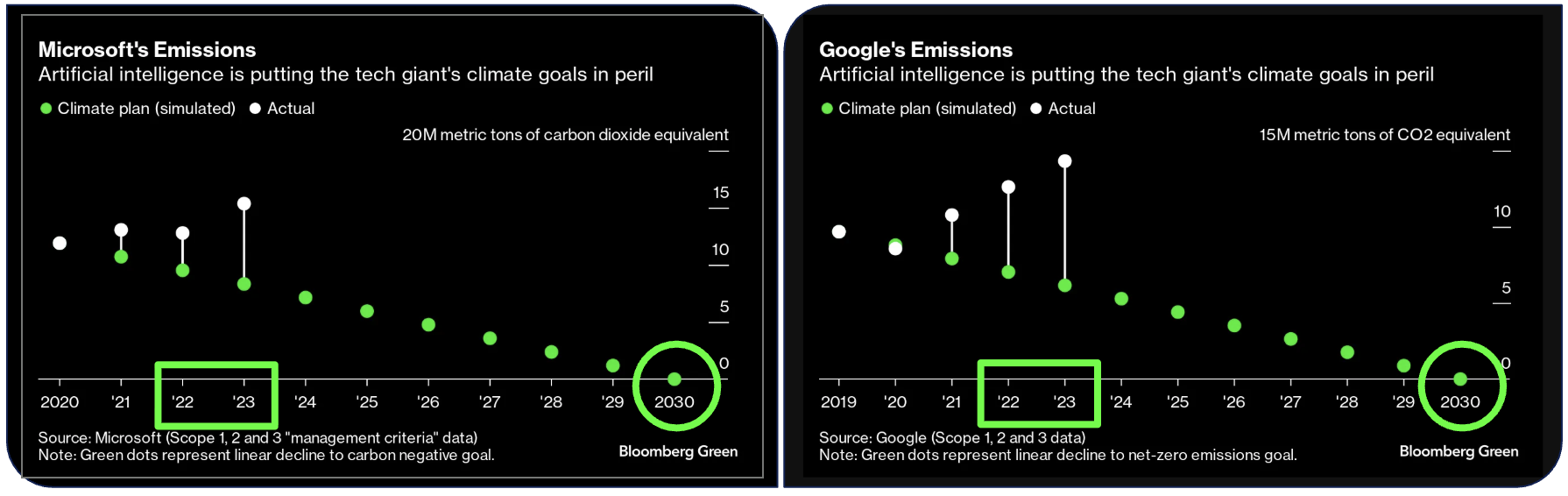
Extrait de la conférence (source Bloomberg green)
Alors, quel est le coût environnemental de l’IA générative ?
De nombreux chercheurs et spécialistes ont tenté, ces deux dernières années, d’estimer l’impact environnemental de l’IA générative. La question est complexe pour deux raisons principales.
- le manque de transparence des acteurs industriels
- la complexité du cycle de vie des modèles et la multiplicité des postes d’impacts,
Un coût difficile à calculer de par un manque de transparence dans l’industrie
Les grands acteurs de l’industrie communiquent peu sur leurs processus et leurs impacts.
D’abord Meta en 2024 (publication Llama-3.1-405B juillet 2024), et plus récemment Mistral (papier juillet 2025) et Google (papier Août 2025) ont partagé des données sur l’impact environnemental de leurs modèles d’IA Générative. Des chiffres qui ont été critiqués par la communauté de chercheurs et experts en impact environnemental de l’IA pour plusieurs raisons :
- Prise en compte partielle du cycle de vie de l’IA générative, certains ne communiquent que sur un poste d’impact spécifique pendant l'entraînement, d’autres que sur la phase d’inférence (source : article de Ketan Joshi).
- Les publications récentes mettent en avant l’impact marginal à l'inférence, c'est-à-dire l’impact d’une seule requête individuelle, qui est minime, et invisibilisent le nombre total d’utilisateurs, la longueur et la complexité des conversations (source : article de Ketan Joshi).
- Enfin, aucun chiffre n’est donné pour les modèles d’image, de vidéo ou de raisonnement, qui sont pourtant aujourd’hui bien plus énergivores que de la génération de texte (source MIT Technology Review).
Une communication partielle
Lors de la publication de son Llama 3-405B, Meta a inclus les émissions carbone de son modèle, le premier acteur à partager ce type d’information. Carbone4, une agence en décarbonation, a réalisé une ACV (Analyse de Cycle de Vie, multicritère, multi-étape) sur ce modèle et partagé les estimations pour les postes qui n’ont pas été inclus dans la publication de Meta : au moins 10 000 tonnes de CO₂. Cette sous-estimation est liée au fait que Meta s’est concentré uniquement sur les émissions très ciblées liées à l'électricité des GPU pendant l'entraînement, il ne fait pas mention des autres postes de consommation hors GPU pendant l'entraînement, ni des postes liés aux autres phases du cycle de vie comme on a vu plus haut, en particulier l'inférence.

Extrait de la conférence. La première ACV, analyse multi-critères, multi-étapes. Source carbone4 d’après Meta et études Carbone4.
En juillet 2025, Mistral se distingue en matière de transparence en publiant une analyse sur l’impact environnemental de son modèle Mistral Large 2. C’est le premier acteur à fournir une ACV, une évaluation multicritère : les émissions de CO₂, la consommation d’eau et l’utilisation de matières premières, ce qui couvre les principaux postes d’impacts de l’IA générative, et sur l’ensemble du cycle de vie du modèle.
Sur une période de 18 mois, l’impact cumulé de l’entraînement et de l’inférence du modèle est estimé à :
- 20,4 tonnes de CO₂, soit l’équivalent de 10 allers-retours Paris–New York
- 281 000 m³ d’eau consommée, soit 100 piscines olympiques
- 660 kg d’équivalent antimoine, correspondant à la production de 3,3 milliards de pièces de 2 centimes d’euro
Estimations réalisées avec un comparateur carbone.
Plus complètes et plus robustes que les chiffres publiés par Meta, ces données offrent davantage de transparence, mais se révèlent aussi plus préoccupantes en mettant en lumière le véritable impact environnemental de l’IA générative.
L’industrie de l’IA générative en est encore à ses débuts. Elle s’ajoute aux problématiques environnementales déjà existantes liées au numérique dans son ensemble. Pourtant, son adoption devient systématique et ses usages sont de plus en plus intégrés dans notre quotidien.
Un coût difficile à calculer dû en partie à un cycle de vie complexe
Avant qu’un modèle d’IA générative soit mis à disposition des utilisateurs, il y a plusieurs étapes de développement clefs. Sont décrites ci-dessous les étapes de développement d’un modèle fondamental de base, sur lequel les applications qui intègrent de l’IA vont se baser.

L’analyse communiquée par Mistral montre les différentes étapes de développement et d’exploitation d’un modèle
1. La recherche et développement : un coût sous-estimé
Avant l’entraînement réel d’un modèle fondamental, c’est-à-dire un modèle de grande taille, entraîné sur des volumes massifs de données et capable de réaliser des tâches généralistes, il y a d’abord une longue phase exploratoire de R&D nécessaire, qui peut durer des mois, voire des années. Des équipes d’ingénieurs, de chercheurs, créent, testent et itèrent massivement sur différentes variations de configurations : architectures, paramètres, datasets, techniques d’optimisation et d’entraînement. À ce stade, on cherche la performance maximale et les impacts de cette phase sont non seulement souvent non inclus dans les publications, mais aussi sous-estimés (source Boris Gamazaychikov, head of sustainability chez Salesforce). Un papier de recherche peut impliquer des dizaines, voire des centaines de runs d'entraînement pour un modèle publié. La R&D n’est d’ailleurs accessible qu’aux organisations ayant accès à l’infrastructure matérielle spécifique à l'entraînement de ces modèles.
2. L’infrastructure matérielle : une forte pression sur les ressources
Les LLM nécessitent des infrastructures spécifiques : GPU/TPU puissants, coûteux et rares (NVIDIA A100, H100), des data centers hyperscale capables de les héberger, nécessitant des systèmes de refroidissement efficaces, et dans certains cas, des sources d’énergie dédiées.
Ces infrastructures et matériels ont eux-mêmes un cycle de vie : extraction des ressources (silicium, terres rares, etc.), fabrication des composants, transports, construction des bâtiments, consommation énergétique et hydrique, et enfin fin de vie et recyclage. Une part importante de l’impact environnemental se situe à ce niveau matériel (61% de la consommation matérielle pour Mistral Large 2).
Les GPU utilisés pour l’IA bénéficient des procédés de fabrication parmi les plus sophistiqués. Ils contiennent une densité très élevée de transistors, gravés à l'échelle nanométrique (7 nm, 5 nm) à l’aide de technologie de lithographie extrêmement complexe et coûteuse. Leur surface est aussi 3 à 8 fois plus grande que celle d’un CPU classique, augmentant la probabilité de défaut. À cette échelle, la moindre imperfection rend le die (la puce brute) inutilisable, et les rendements (“yield”) de ce type de GPU sont faibles, avec environ 50 % de pertes. La quasi-totalité des GPU destinés à l’IA sont fabriqués par TSMC à Taïwan où le mix électrique local est très carboné (charbon, gaz). Enfin, en raison de leur haute densité de puissance, ces GPU ont une durée de vie effective plus courte (2-3 ans) avec 9 % de défaillance annuelle, et ils sont difficiles à maintenir et à réparer (source Stanley Layman group).
Cette sophistication technologique s’applique également aux datacenters, dont la densification de puissance des racks accentue l’importance des systèmes de refroidissement, souvent basés sur des systèmes utilisant de l’eau, ainsi que la consommation d'énergie, dont la localisation a un impact majeur sur l’empreinte environnementale, en raison du mix énergétique régional.
3. L’entraînement : un poste majeur par la quantité de données
L’entraînement d’un LLM vise à optimiser les centaines de milliards de paramètres du modèle et va se dérouler sur plusieurs semaines, et des centaines, voire des milliers de GPU fonctionnent en continu, jour et nuit, pour traiter des milliards de documents (textes et images).
Historiquement, l’entraînement était la phase la plus énergivore du machine learning. Aujourd’hui, nous avons vu qu’avec la taille massive des modèles et l’adoption généralisée de l’IA générative, l’impact cumulé de l’inférence peut dépasser celui de l’entraînement, malgré son coût absolu élevé.
4. L’inférence : un poste majeur par la taille des modèles et leur adoption massive
L’inférence correspond à l’utilisation du modèle en production. Depuis l’arrivée des LLM, la phase d’inférence est devenue une source d’impact majeur. À ce stade, les GPU sont utilisés en continu, mais plusieurs techniques d’optimisation du modèle et du processus de mise en production sont mises en place pour économiser des ressources.
Chaque requête utilisateur reçue est traitée par le LLM qui effectue des calculs matriciels pour fournir une réponse, et mobilise pendant une fraction de temps des ressources.
Comme vu plus tôt avec les chiffres de Mistral, le coût d’une requête semble minime (1,14 gCO₂e, 45 mL d'eau et 0,16 mg de Sb eq pour Mistral Large 2), mais quand on ramène à l’échelle des millions voire milliards de requêtes par jour (2,5 milliards de requêtes par jour pour OpenAI, source OpenAI), l’empreinte environnementale de l’inférence devient massive, malgré les optimisations (si Mistral Large 2 avait eu autant d’utilisateurs que ChatGPT en un an : 1 million tCO₂e, 41 millions m³ d'eau, et 146 t Sb eq par an).
5. Les réseaux et les terminaux utilisateurs
Les requêtes entre les utilisateurs et les modèles transitent par des infrastructures réseau : routeurs, antennes, fibres optiques, serveurs intermédiaires. Ce sont des infrastructures physiques, qui ont leur propre cycle de vie, et leurs propres impacts.
Aussi, les utilisateurs interagissent avec les modèles d’IA avec leurs propres machines (ordinateurs, smartphones), qui ont également leur cycle de vie et leurs impacts qu’il faut aussi prendre en compte au ratio de leur utilisation.
Dans les deux cas, les postes d’impact sont majoritairement liés à la fabrication et à la consommation énergétique pendant l’utilisation.
6. Les effets indirects de l’usage et l’effet rebond
Un effet auquel on ne pense pas est l’impact des tâches réalisées avec l’IA. En effet, au-delà des impacts cités ci-dessus, l’empreinte d’un système IA ne dépend pas seulement de sa fabrication et de son utilisation, mais aussi des effets produits avec le système. Une IA utilisée pour optimiser durablement des systèmes ou résoudre des problèmes environnementaux permet de mitiger une partie de son propre coût environnemental. Par contre, si elle sert à décupler des activités à faible valeur ou qui ont un impact fort sur l’environnement, elle peut détériorer son impact environnemental. Dans certains de ces cas, on parle de l’effet rebond, lorsque les gains d’efficacité entraînent une augmentation de l’usage au global, ce qui décuple la pression sur les ressources malgré les optimisations techniques.
En bref, le coût environnemental réel de l’IA générative ne se limite pas à l’entraînement ou à l’inférence. Il doit être évalué sur l’ensemble du cycle de vie du modèle, de sa conception à son utilisation, et doit prendre en compte les différents critères d’impact, au-delà des émissions carbone. Sans cette vision globale, les estimations restent partielles et sous-évaluent l’impact environnemental réel de l’IA générative.
Nos bonnes pratiques pour intégrer de l’IA sur des projets
D’un point de vue environnemental, le constat n’est pas très réjouissant, et chez beaucoup d’entre nous, il renforce même un sentiment d’impuissance et d’éco-anxiété qui est déjà présent face aux enjeux climatiques.
Mais le meilleur antidote à l’anxiété reste l’action.
L’IA générative reste avant tout un outil, alors informons-nous, parlons-en au sein de nos équipes, intégrons des critères environnementaux dans les choix techniques et appliquons les bonnes pratiques pour améliorer l’impact de nos projets.
La partie suivante synthétise les bonnes pratiques que nous avons partagées dans le cadre de la conférence :🎬 IA générative et réchauffement climatique : comment réduire la facture ?
Vous trouverez deux notebooks d’introduction à la mesure des impacts environnementaux de l’IA générative en fin de cet article.
Bonne pratique #1 : Questionner son besoin
La première question, finalement très simple, à se poser lorsqu’on envisage d’intégrer de l’IA dans un contexte de projet : ai-je réellement besoin d’IA générative ?
L’objectif n’est pas d’utiliser le modèle le plus puissant, mais le modèle le plus adapté pour son cas d’usage, ses enjeux et ses contraintes, et offrant le meilleur compromis entre performance, coût et impact environnemental.
L’IA existe depuis des décennies, une grande variété de modèles était largement utilisée avant l’apparition des LLM. Et encore aujourd’hui, dans de nombreux cas, des approches plus classiques, par exemple du machine learning, des architectures simples de deep learning, et parfois même de simples règles de gestion, peuvent rester parfaitement adaptées, en particulier dans des contextes d’industrialisation.
L’IA générative est impressionnante, mais elle reste un outil. Sur certains cas d’usage, elle est évidemment le meilleur choix, mais sur d’autres, une simple régression logistique pourrait être plus performante, plus simple à industrialiser et bien sûr plus sobre.
En effet, l’utilisation de LLM en contexte d’industrialisation introduit une complexité importante : leur taille impose souvent des infrastructures dédiées (GPU), ou une gestion des coûts (appels API), et leur nature non déterministe implique de la complexité dans leur évaluation, versioning et monitoring. Intégrer un LLM en production implique une révision de stack technique avec des outils spécifiques, et des nouvelles pratiques. Et cette complexité peut être justifiée par la valeur apportée.
Cette première bonne pratique consiste à ancrer son choix sur le besoin plus que sur la technologie. Les étapes :
- Clarifier l’objectif, les enjeux, et le problème à résoudre.
- Identifier les contraintes :
- Quel usage (POC ou industrialisation ? Des contraintes pour l’industrialisation ?)
- La performance est-elle un enjeu critique ? (l’impact d’un gain d’un point d’accuracy est-il crucial ?)
- Quelles sont les contraintes de coûts, délais, techniques ?
- Explorer itérativement les solutions :
- Peut-on utiliser des règles métier ?
- Quelles familles de machine learning classique sont pertinentes ?
- Quels modèles de deep learning utiliser ?
- Quel type et modèle de LLM sont les plus pertinents pour le cas d’usage ?
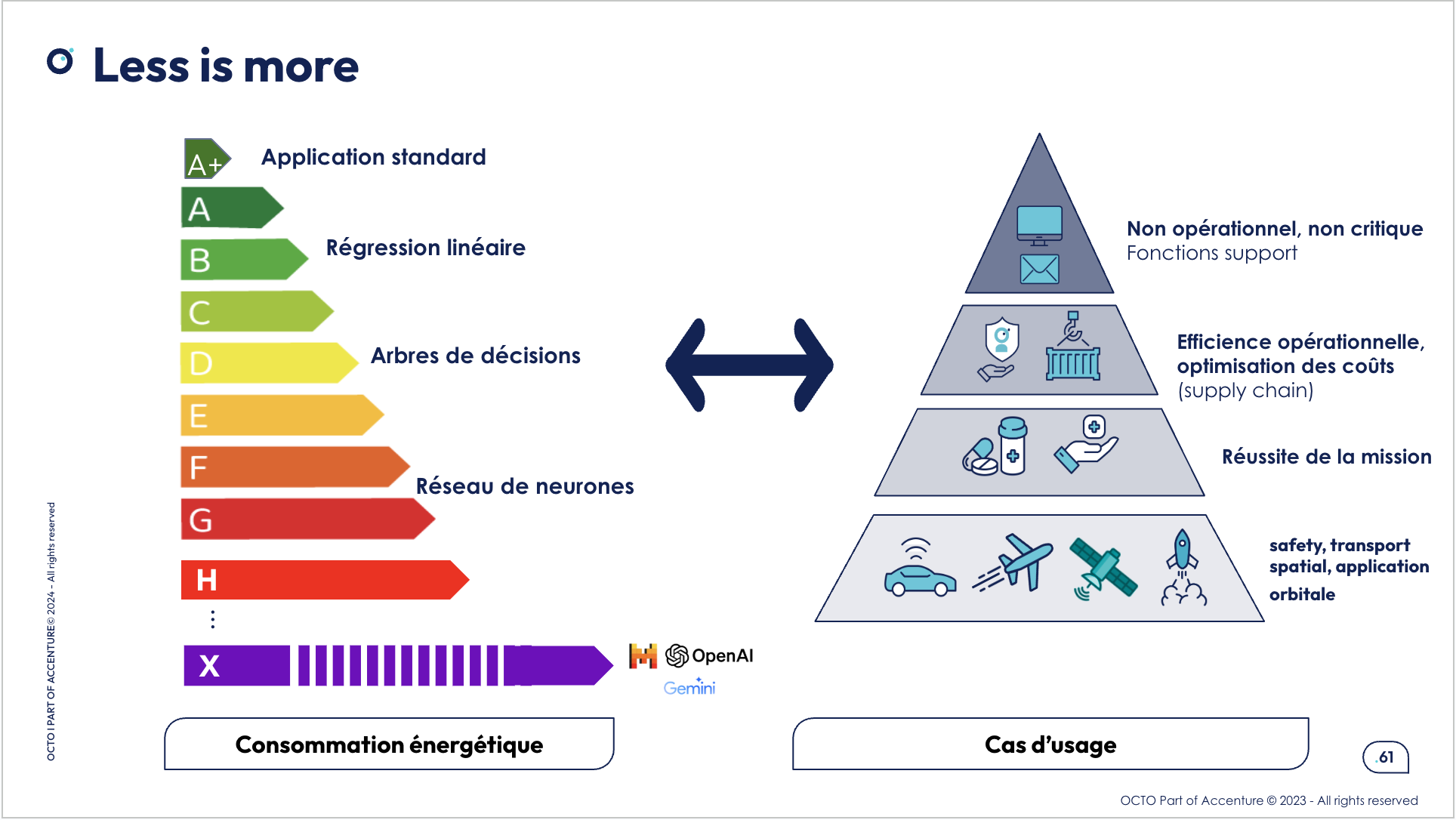
Extrait de la formation OCTO Technology - Green AI : l’intelligence artificielle responsable
Bonne pratique #2 : Viser petit
Après avoir exploré et choisi la catégorie de modèle, si l’on choisit de travailler avec de l’IA générative, la deuxième étape est de choisir la taille du modèle.
En effet, plus un modèle est grand et a de paramètres (c’est-à-dire les poids qui connectent les neurones), plus le volume de calcul sera important, et donc le temps d’exécution long, et in fine l’impact environnemental élevé. Les émissions sont directement corrélées à la taille des modèles.
On va donc se questionner sur le choix de la taille du modèle en fonction des enjeux et des contraintes du cas d’usage : on identifie le plus petit modèle pertinent, puis on teste des modèles plus grands de manière incrémentale en fonction des performances obtenues. Ainsi, on évite le surdimensionnement.
Cette catégorie correspond aux petits modèles de langage, appelés SLM (Small Language Models), qui présentent de nombreux avantages : ils sont bien plus rapides et plus faciles à déployer avec des ressources accessibles (en local ou dans le cloud), ils sont donc moins coûteux et génèrent moins d’émissions. Ils sont particulièrement adaptés aux cas d’usage spécifiques, aux déploiements locaux ou offline, ou encore dans le cadre d’applications embarquées ou d’infrastructures limitées. En revanche, ils ont aussi des inconvénients : ils sont moins performants sur des tâches très complexes ou généralistes, ils ont généralement besoin d’être fine-tunés, et ont une fenêtre de contexte plus petite.
Pour une utilisation en local, on utilisera Hugging Face, la plateforme de partage open source de la communauté. Il est possible d’y télécharger des modèles open weights, qui peuvent être utilisés localement, déployés, et continuer à être entraînés. On peut rechercher des modèles en fonction de différents critères, notamment leur nombre de paramètres, ce qui permet de comparer des modèles de taille similaire et de faire le meilleur choix en commençant par les plus petits. Il existe plusieurs sous-catégories en fonction des contraintes d’infrastructure : les modèles de moins de 2 milliards de paramètres peuvent être exécutés sur smartphone ou CPU ; entre 3 et 8 milliards de paramètres, on commence à avoir besoin de plus de puissance, un GPU en local ou dans le cloud (NVIDIA T4), et enfin, les modèles entre 9 et 32 milliards de paramètres nécessitent des puces plus coûteuses (NVIDIA A100, H100).
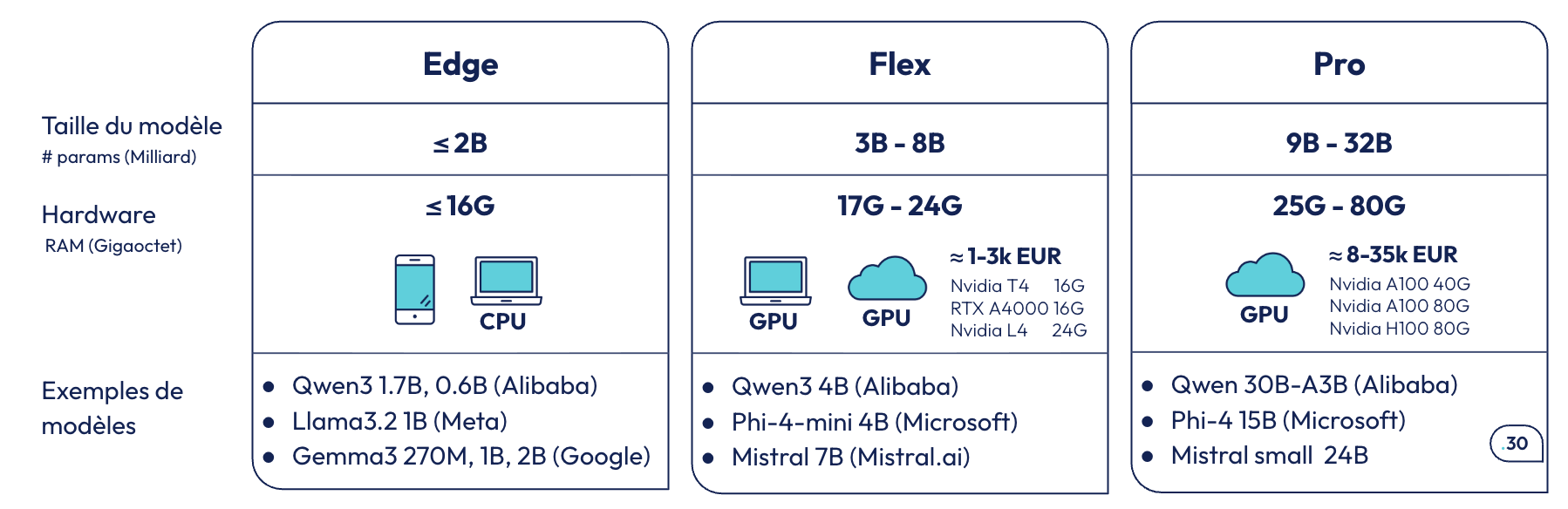
Extrait de slide de la conférence
Dans le cas de l’utilisation de modèles via API, on ne connaît pas la taille exacte des modèles. On utilise comme indicateur indirect le prix par token : plus un modèle est grand, plus son coût d’utilisation est élevé, et plus son impact environnemental est important. Dans le cadre des assistants conversationnels ou des outils d’aide au développement, lorsque le prix par token n’est pas disponible, quand on compare différents modèles chez un même fournisseur, on peut également se guider par la vitesse de réponse : les modèles plus petits sont généralement plus rapides et plus efficaces.
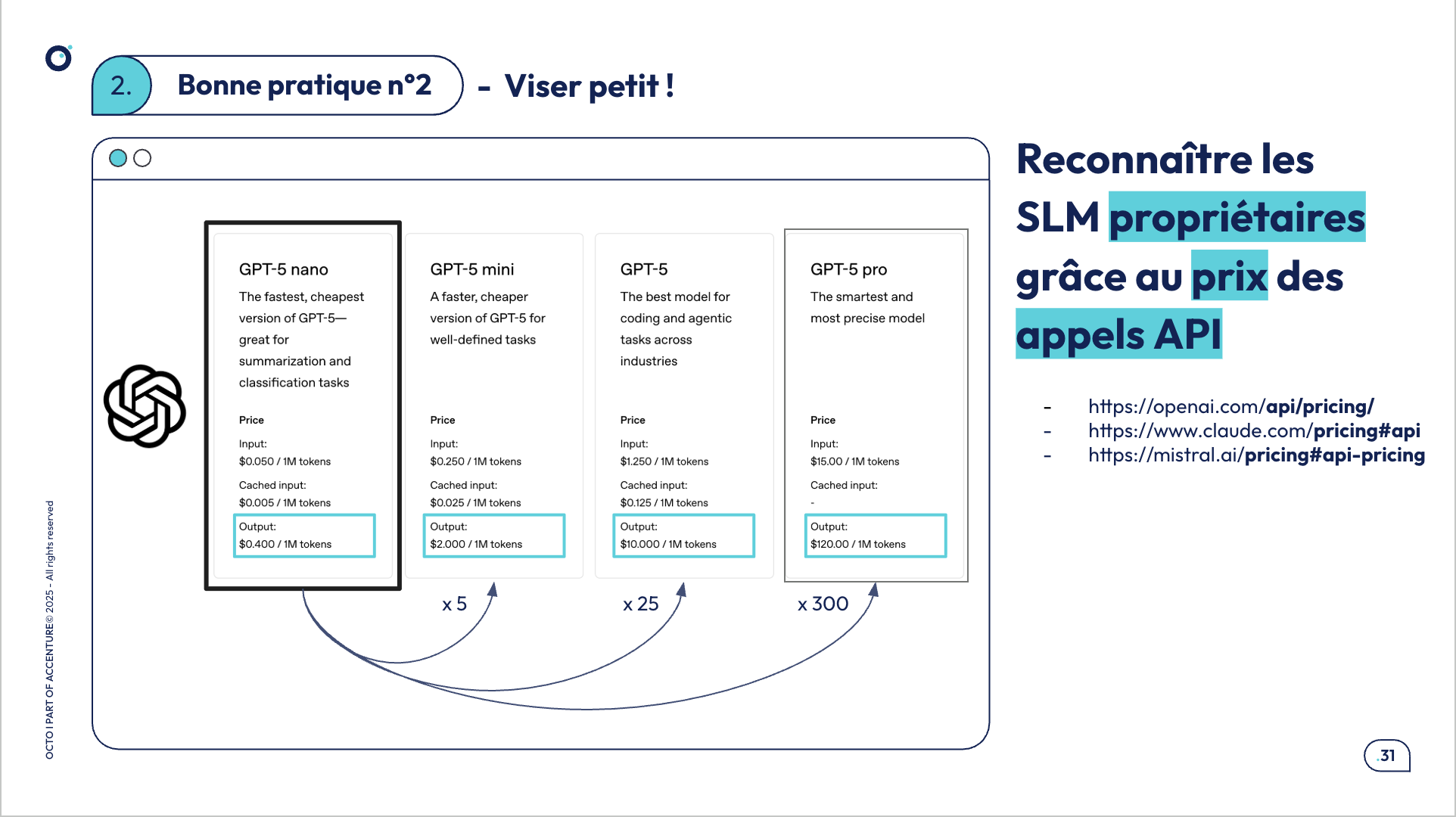
Extrait de slide de la conférence : Prix par token pour les modèles d’OpenAI (source OpenAI) - novembre 2025
On note que les modèles plus petits sont conseillés pour des tâches spécifiques, ce qui rappelle les caractéristiques des SLM.

Prix par token pour les modèles d’OpenAI (source OpenAI) - génération de vidéo - février 2026
On note d’ailleurs le prix élevé de la génération de vidéo en comparaison avec la génération de texte, ce qui pourrait être un indice de l’échelle des coûts et des émissions carbones associées.
Bonne pratique #3 : Optimiser les modèles
Une fois que nous avons déterminé le modèle d’IA générative avec la taille optimale, la troisième étape est d’explorer les techniques d’optimisation des modèles. Ce sont des stratégies pour réduire la taille du modèle tout en préservant au maximum ses performances comme par exemple la quantification ou la distillation.
La quantification
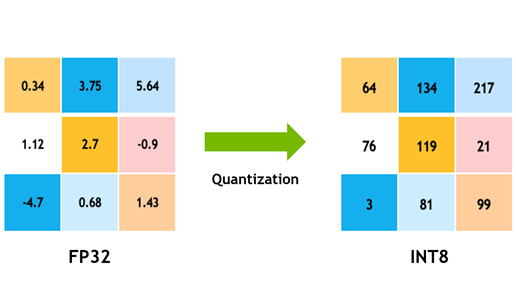
Image extraite de : NVIDIA Developer Blog, article « Achieving FP32 Accuracy for INT8 Inference Using Quantization-Aware Training with TensorRT », 2020.
La quantification est une technique d’optimisation consistant à réduire la précision numérique des poids d’un modèle. Concrètement, les poids habituellement représentés en précision 32 bits sont convertis en 16 bits (FP16) ou 8 bits (INT8), ce qui permet de diminuer significativement la taille mémoire du modèle tout en accélérant les temps de calcul.
Pour donner un ordre de grandeur : passer de FP32 (4 octets par paramètre) à INT8 (1 octet) divise la taille mémoire par quatre. Sur un modèle de plusieurs milliards de paramètres, le gain est immédiat : moins de mémoire GPU, moins de transferts mémoire, et donc moins d’énergie consommée à chaque requête.
Dans la pratique, on distingue deux grandes approches :
- Post-Training Quantization (PTQ) : on quantifie un modèle déjà entraîné. Méthode simple et peu coûteuse, souvent suffisante pour l’inférence.
- Quantization-Aware Training (QAT) : la quantification est simulée pendant l’entraînement afin de limiter la perte de performance.
Pour les LLM open weight, la quantification 8 bits et 4 bits est largement utilisée afin de permettre l’exécution sur du matériel plus accessible. Des bibliothèques comme bitsandbytes sont devenues des standards dans l’écosystème Hugging Face. On retrouve aussi des outils natifs dans PyTorch et des optimisations côté déploiement via ONNX Runtime.
Du point de vue environnemental, l’effet est surtout visible en phase d’inférence : réduction de la mémoire active, baisse de la consommation par requête, et meilleure densité d’utilisation des GPU. En revanche, l’impact sur le coût énergétique du pré-entraînement reste limité.
La distillation
La distillation de modèles est une approche dans laquelle un modèle de grande taille (le teacher) transmet ses connaissances à un modèle plus compact (le student). Le modèle “student” est entraîné pour reproduire les prédictions du modèle teacher, ce qui permet d’obtenir un modèle plus léger et plus rapide, tout en conservant une grande partie des performances du modèle initial.
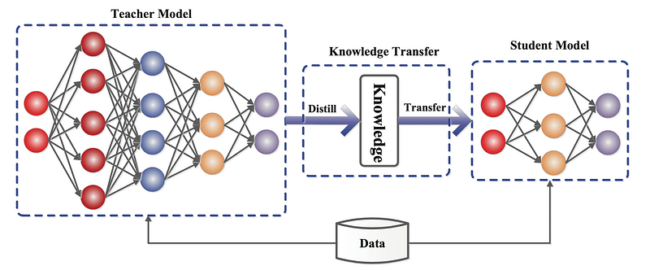
Image extraite de : arXiv:2006.05525v7 - Knowledge Distillation: A Survey, Gou et al.
L’image ci-dessus illustre le concept général de transfert de connaissances auquel nous faisons référence. Il est simplifié par rapport à l’article cité, qui propose une revue détaillée des différentes méthodes spécifiques de distillation.
La distillation a été introduite en 2015 (Hinton et al.), depuis il en existe de nombreuses variantes (Gou et al.), notamment la distillation séquentielle (offline) ou parallèle (online), ainsi que des approches basées sur la mimique des prédictions du modèle (response-based), de ses représentations intermédiaires (feature-based), ou des relations entre échantillons (relation-based).
La distillation peut sembler une technique avancée, mais il existe des variantes simplifiées proches d’un fine-tuning classique : par exemple, entraîner un modèle student à partir d’un dataset généré par le teacher.
Comme pour toute méthode de fine-tuning, le modèle résultant peut réussir à atteindre de très bonnes performances, même parfois supérieures à celles du modèle teacher sur une tâche spécifique. Mais ce type de modèle implique un coût supplémentaire ainsi qu’une complexité accrue pour la maintenance du modèle en production.
Par ailleurs, la quantification, la distillation et d’autres techniques d’optimisation sont déjà intégrées dans de nombreux modèles disponibles sur Hugging Face (voir image ci-dessous) ainsi que ceux mis à disposition par les éditeurs via leurs API. Des librairies d’optimisations permettent de continuer d'entraîner des modèles optimisés de manière très efficace (Unsloth.ai), ou d’aller plus loin dans les techniques d'optimisation de modèles (pruna.ai).
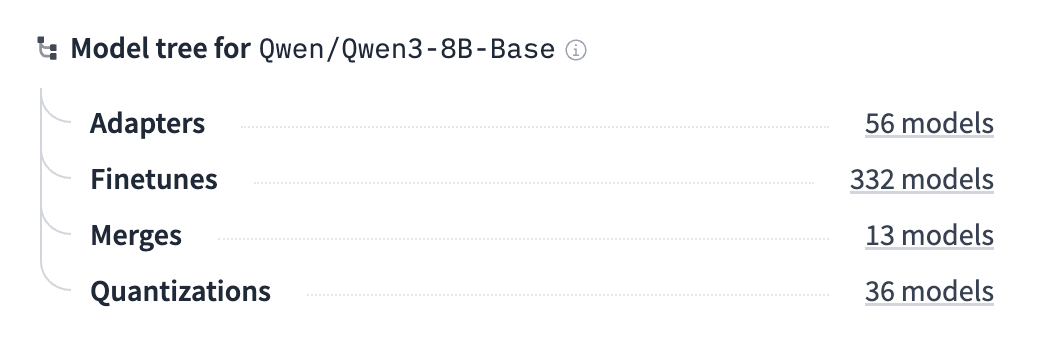
Arborescence des modèles basés sur Qwen/Qwen3-8B-Base - 36 modèles quantisés disponibles
Bonne pratique #4 : Optimiser la mise en production
Pour avoir un réel impact sur l’empreinte environnementale de notre modèle, il est indispensable de choisir une zone de faible intensité carbone pour la mise en production… et cette intensité dépend directement du mix énergétique régional !
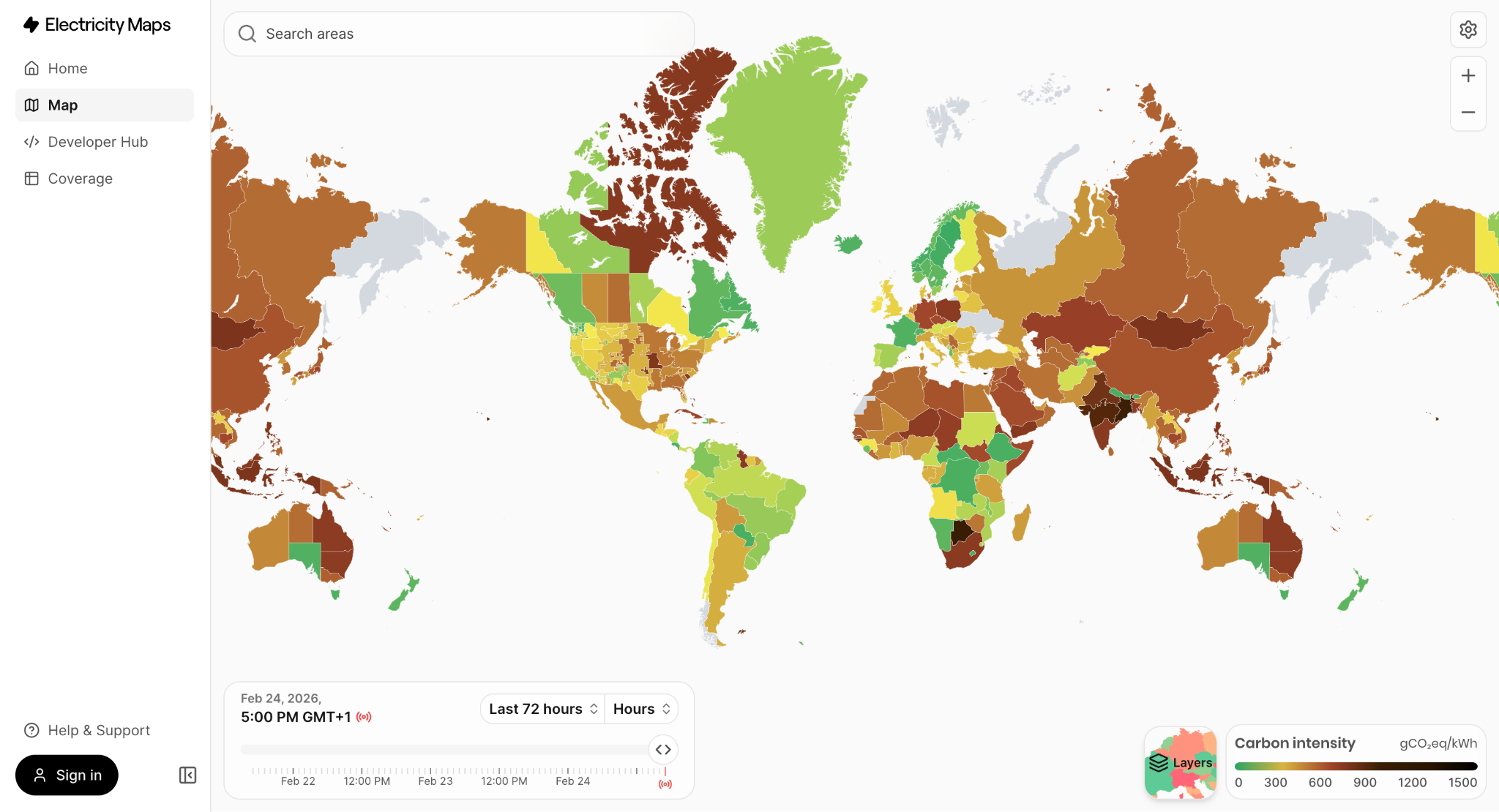
Capture d’écran d’une plateforme permettant de visualiser en temps réel l’empreinte carbone de l’électricité dans le monde (source Electricity maps)
Ce choix est loin d’être anodin : un modèle hébergé en France peut émettre jusqu’à 21 fois moins de CO₂ qu’un modèle hébergé à Varsovie, pour une charge de calcul équivalente. En effet, ça s’explique par l’intensité carbone de l’électricité (gCO₂/kWh), qui varie beaucoup selon le mix énergétique des pays. La production d’électricité en France repose majoritairement sur le nucléaire, peu carboné, tandis que d’autres pays comme la Pologne utilisent majoritairement des énergies fossiles comme le charbon.
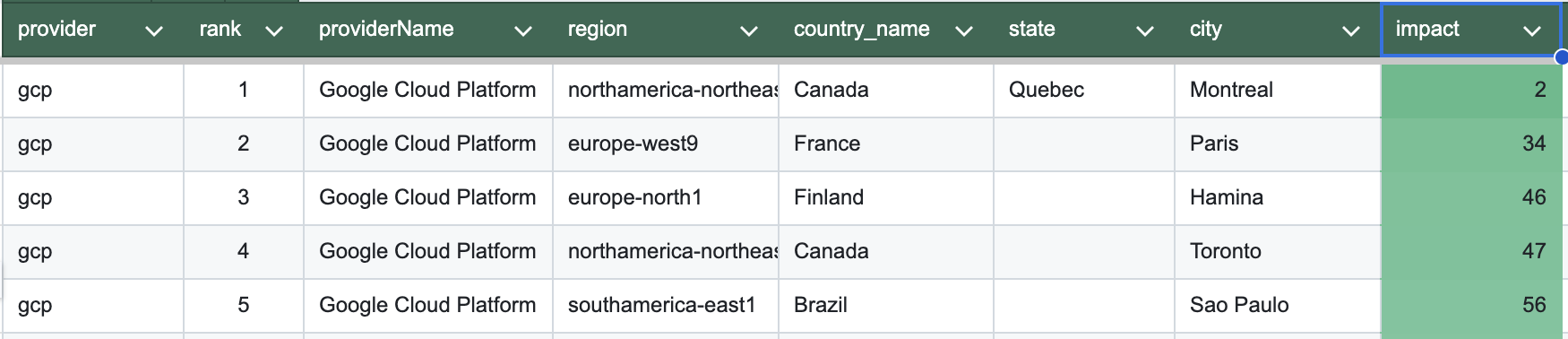
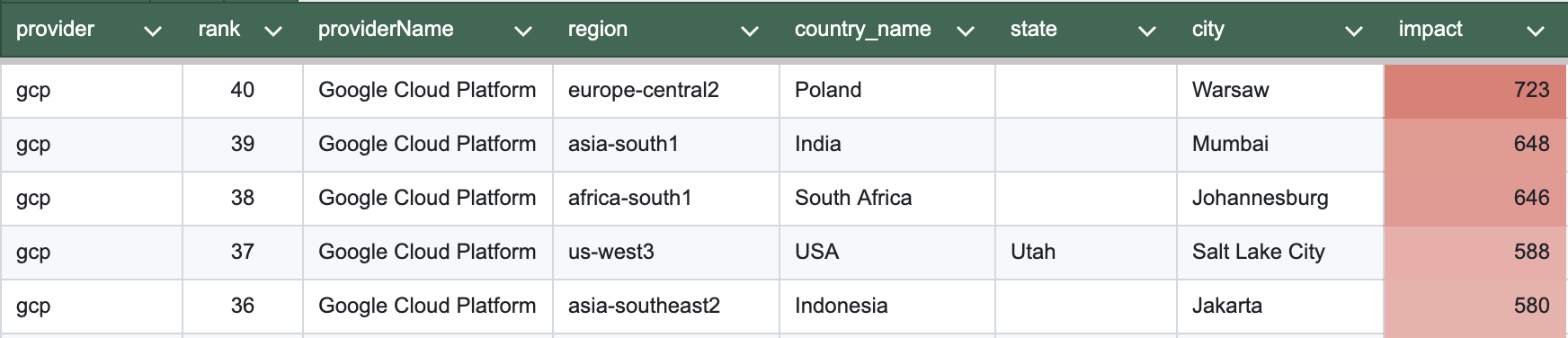
Image extraite du dépôt GitHub de CodeCarbon (source cloud/impact.csv)
Si on souhaite aller encore plus loin pour l’optimisation de la mise en production, quelques quick wins :
- Limiter la fenêtre de calcul : réduire le nombre de tokens traités et générés au strict nécessaire.
- Arrêts automatiques : libérer les ressources dès qu’elles ne sont plus utilisées.
- Parallélisation des calculs : exécuter plusieurs calculs en même temps pour gagner en efficacité.
- Inférence par batch : regrouper plusieurs requêtes afin d’optimiser l’utilisation des ressources.
- Caching : réutiliser les résultats fréquents pour éviter des calculs inutiles.
Bonne pratique #5 : Mesurer l’impact de ses projets
Toutes les bonnes pratiques communiquées jusqu’alors sont des bonnes pratiques pour réduire l'impact environnemental, mais c’est également essentiel de savoir ce que l’on consomme.
C’est pourquoi nous évoquons à présent notre dernière bonne pratique : mesurer l’impact de nos projets Gen AI.
Pour cela on vous propose trois outils qui permettront de mesurer l’impact environnemental à différents niveaux (Code Carbon, Cloud Carbon FootPrint et Ecologits).
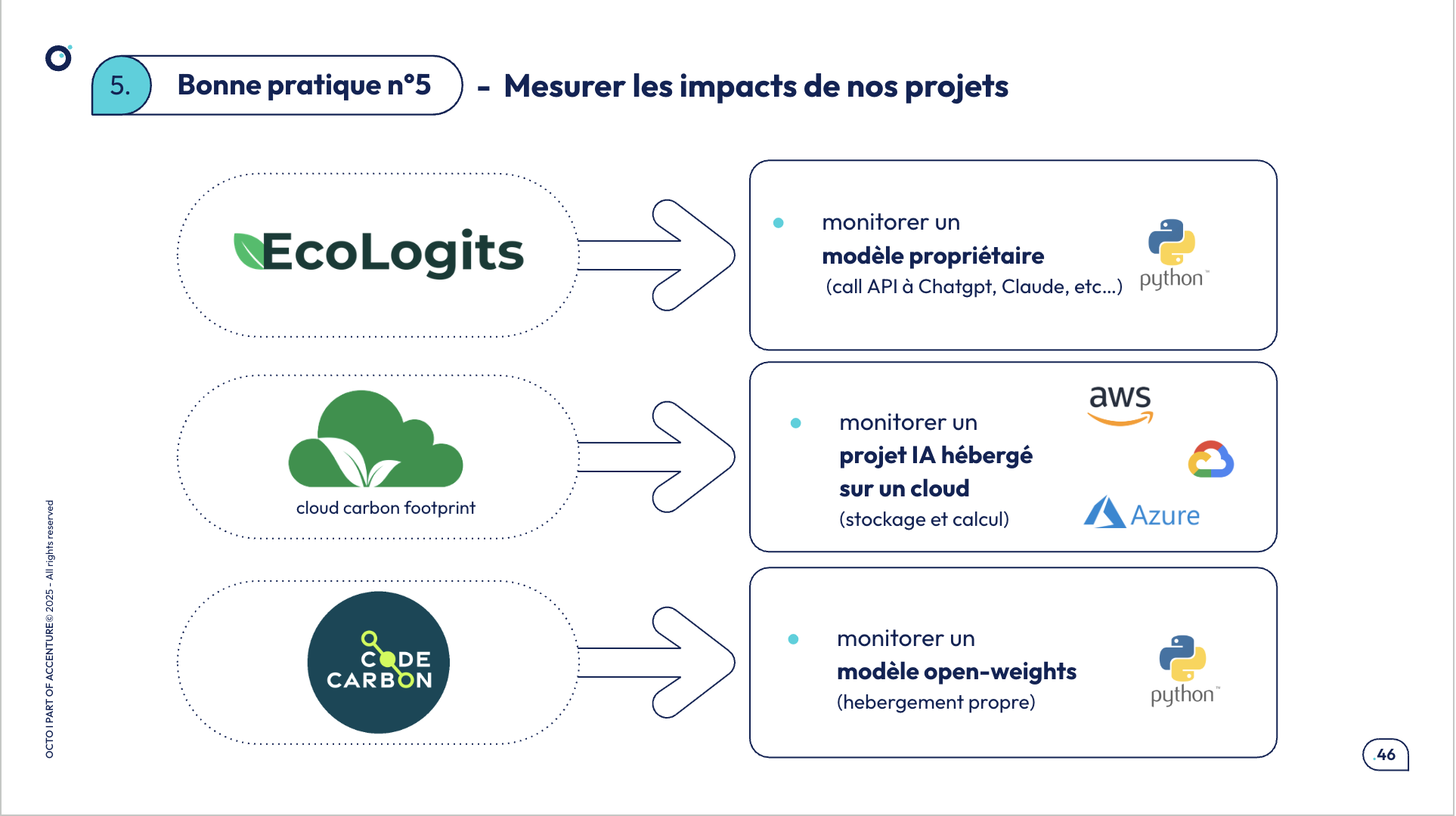
Extrait de slide de la conférence : trois outils de mesure environnementale pour trois cas d’usage
Ecologits
Ecologits est une bibliothèque Python, pensée pour estimer l’empreinte carbone des appels API vers des modèles de langage propriétaires comme ChatGPT, Claude ou Gemini. Ces fournisseurs ne communiquant que très peu d’informations sur leurs modèles, Ecologits s’appuie sur un ensemble d’hypothèses à partir de données open source et d’informations publiques disponibles pour proposer des estimations cohérentes.
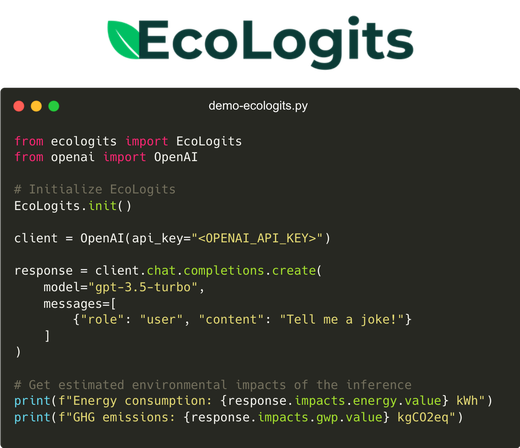
Exemple de prise en main rapide d’ecologits (source ecologits)
Cette librairie est très simple d’utilisation, on instancie un objet “Ecologits”, qui va identifier automatiquement l’appel API et se greffer à la réponse.
Nous mettons également à votre disposition un notebook de prise en main d’ecologits qui contient des exemples, un tutoriel pas à pas, des comparaisons et qui donne également des informations sur la librairie et la méthodologie de calcul.
📚 Notebook de prise en main d’Ecologits : lien github
CodeCarbon
CodeCarbon est une bibliothèque Python open source qui permet de mesurer en temps réel la consommation énergétique d’un morceau de code en prenant en compte l’utilisation CPU et/ou GPU associée et d’en déduire les émissions CO₂ associées. L’outil détecte automatiquement la localisation de la machine afin de prendre en compte le mix énergétique local, et génère un fichier CSV et un dashboard pour suivre et analyser l’impact environnemental du code.

Extrait de la conférence : il existe plusieurs modes d'utilisation
Nous mettons également à votre disposition un notebook de prise en main de CodeCarbon qui contient des exemples, un tutoriel pas à pas, des comparaisons et qui donne également des informations sur la librairie et la méthodologie de calcul.
📚 Notebook de prise en main de Codecarbon : lien github
Cloud Carbon Footprint
Cloud Carbon Footprint est une application web open source conçue pour l’analyse de l’empreinte carbone d’une infrastructure cloud complète (compatible avec AWS, Azure ou Google Cloud). L’outil se connecte aux API des fournisseurs pour récupérer les données d’usage, puis applique des modèles de calcul afin d’estimer la consommation énergétique et les émissions de CO₂. Il propose des tableaux de bord clairs, avec des visualisations par service et par région, ainsi que des pistes concrètes d’optimisation pour réduire l’impact environnemental.
| Code Carbon | Ecologits | Cloud Carbon FootPrint | |
|---|---|---|---|
| Type d’outil | Bibliothèque Python | Bibliothèque Python | Application Web Open Source |
| Périmètre de mesure | Code exécuté localement ou sur serveur | Appels API vers LLM propriétaires | Infrastructure Cloud Complète |
| Méthode de mesure | Mesure directe de la consommation CPU/GPU et RAM | Estimations basées sur des hypothèses et données open source | Récupération données via APIs cloud + modèles de calculs |
| Granularité | Par fonction/script/entraînement | Par requête API | Par service/région/compte cloud |
| Output | Fichier csv/logs avec kWh, CO₂ et Dashboard | Métriques par requêtes (tokens, CO₂ estimés) | Dashboard web interactifs, exports, recommandations |
| Idéal pour | Data Scientist, AI Engineer | Développeur utilisant des LLM via API | DevOps, FinOps |
| Limite | - Besoin d’avoir accès au code - Ne prends pas en compte les appels API | - Besoin d’avoir accès au code - Basé sur des hypothèses et non sur des données publiées - Liste des modèles non exhaustive | - Manque de granularité - Besoin d’autorisation spécifique au niveau du Cloud - Ne couvre pas tous les Clouds. |
Pour conclure, les cinq principes à retenir
Nous arrivons à la fin de cet article, dans lequel nous avons partagé les différents enseignements de notre conférence, et en particulier les grands principes à intégrer dans une démarche d’intégration de l’IA générative dans un système applicatif.
S’il ne fallait retenir que cinq principes clés pour réduire l’impact environnemental de vos projets intégrant de l’IA générative, ce seraient les suivants :
1/ Clarifier son besoin
Lors des phases préliminaires, posons-nous des questions pour clarifier le besoin : quel est mon besoin, quel est mon problème ? Existe-t-il une solution plus simple ? L’IA générative apporte-t-elle de la valeur ? Quelles sont les performances d’un modèle plus classique ?
2/ Choisir des modèles petits
Plus un modèle est grand, plus son impact environnemental est fort. Commençons nos explorations avec des modèles légers, puis montons en complexité si les performances ne sont pas suffisantes.
3/ Choisir des modèles optimisés
Il existe des techniques d’optimisation qui permettent de réduire la taille des modèles. La quantification et la distillation sont deux techniques accessibles très performantes.
4/ Optimiser la mise en production
Le choix de la zone d’hébergement est déterminant : privilégier des régions à faible intensité carbone permet de réduire significativement l’empreinte environnementale du modèle. D’autres techniques sont utilisées en production : autoscaling et mise en veille automatique, limite de la fenêtre de contexte, caching, batch inference, parallélisation.
5/ Mesurer et suivre les impacts
Enfin, il est indispensable de connaître l’impact environnemental de ses projets dès les phases de développement à l’aide d’outils dédiés comme Ecologits, Cloud Carbon Footprint ou CodeCarbon.
Et des ressources…
La conférence
🎬 IA générative et réchauffement climatique : comment réduire la facture ?
Les notebooks
Pour se familiariser avec la mesure des impacts de l’IA générative, nous mettons à disposition deux notebooks :
- 📚 Codecarbon : mesurer les impacts d’un modèle utilisé en propre (en local, ou déployé sur le cloud)
- 📚 Ecologits : mesurer les impacts d’un modèle utilisé via API
Nos inspirations
- Pour se questionner, foncez visionner le talk inspirant de Tristan Nitot, directeur associé Communs numériques et Anthropocène chez OCTO :
🎬 Tristan Nitot - L’humanité a-t-elle les moyens de s’offrir l’IA ? - Pour aller plus en détail sur les impacts environnementaux de l’IA, vous pouvez consulter l’excellent article de Bon pote, [Intelligence artificielle : le vrai coût environnemental de la course à l’IA](https:// https://bonpote.com/intelligence-artificielle-le-vrai-cout-environnemental-de-la-course-a-lia/)
- Pour approfondir la compréhension des enjeux liés aux datacenters et à la fabrication des GPU, vous pouvez consulter les conférences passionnantes proposées par Hubblo, disponibles en rediffusion :🎬 Faire parler les GPUs et 🎬 À la recherche des datacenters français.
- Pour aller plus en détails sur l’AI forcing: Le forcing de l'IA | Limites numériques
Issu du papier Imposing AI: Deceptive design patterns against sustainability (Université de Strasbourg & Designer Éthiques)