FinOps: comment économiser 100 000 $/an en ouvrant simplement AWS Cost Explorer
Un data lake AWS dans le secteur de l'énergie. Un projet vieux de 7 ans, plusieurs équipes successives, une facture cloud que personne ne regarde. Premier réflexe en arrivant sur la mission : ouvrir AWS Cost Explorer. Pas par réflexe FinOps. Par curiosité.
Ce qui apparaît à l'écran va mener à 100 000 $ d'économies annuelles récurrentes. Sans outil FinOps, sans consultant spécialisé, sans migration cloud. Juste une facture qu'apparemment personne n'avait ouverte depuis des mois.
Voici l'histoire de trois anomalies et de leur correction.
6 500 $/mois pour un data lake qui ne devrait pas coûter autant
Le contexte : un data lake AWS qui alimente des dashboards PowerBI pour un réseau de chauffage urbain. Quelques pipelines batch, des API Lambda, du stockage S3, des requêtes Athena. Rien d'exotique. L'équipe (deux développeurs juniors) fait tourner la plateforme au quotidien sans se poser de questions sur les coûts.
La facture mensuelle : 6 500 $.
Pour ce volume de données et cette architecture, c'est anormal. Le Cost Explorer raconte une histoire, et chaque pic, chaque service inattendu dans le top 5 des dépenses est un indice.
Premier réflexe : "C'est probablement S3 ou Athena qui coûtent cher."
Premier piège : ce n'est ni S3 ni Athena le problème.
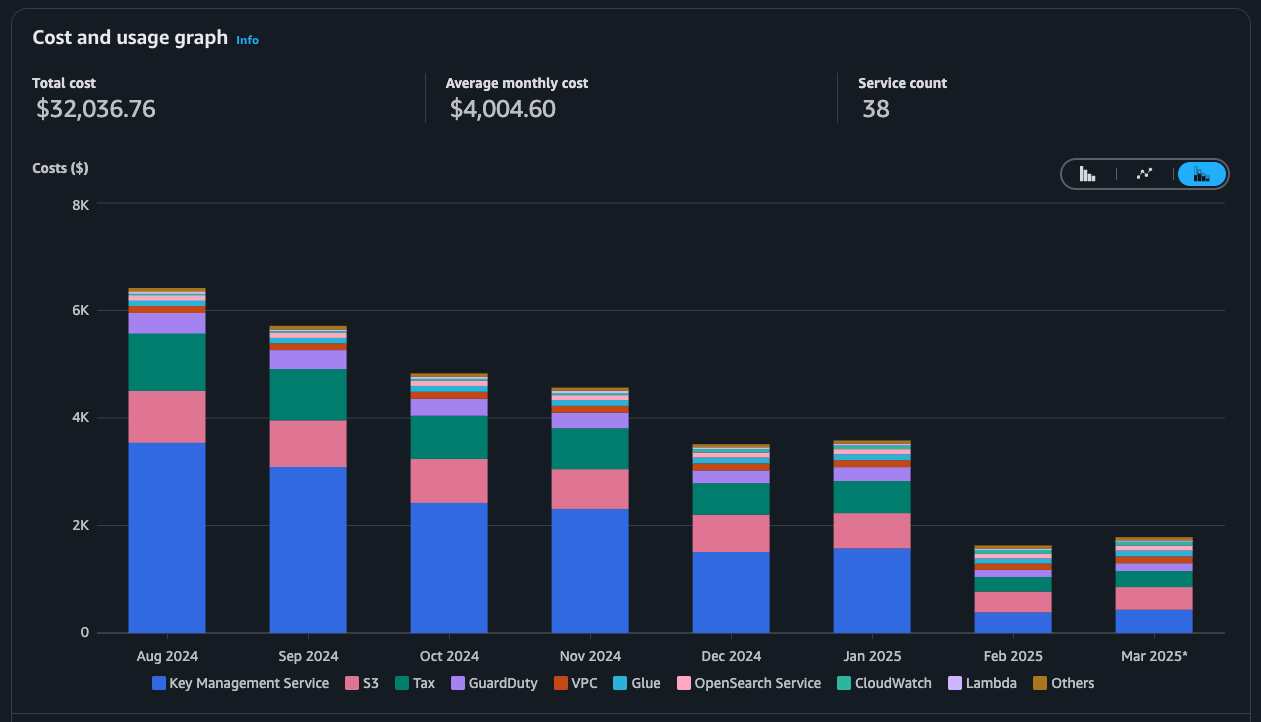
Anomalie 1 : AWS KMS, le service invisible à 4 000 $/mois
En regardant la répartition des coûts par service, un nom inattendu domine : AWS KMS (Key Management Service). Plus de la moitié de la facture mensuelle. À lui seul.
KMS, c'est le service de chiffrement d'AWS. Chaque écriture génère une clé via KMS pour chiffrer le fichier ; chaque lecture déclenche un appel KMS pour déchiffrer cette clé. Indispensable pour la sécurité. Mais à quel prix ?
Le problème : les API exposent des données de consommation énergétique sur 5 ans. Quand un utilisateur métier fait une requête sur cette période, le système parcourt des centaines de fichiers Parquet dans S3. Chaque fichier = un appel KMS.
Le calcul :
- 130 fichiers reçus par jour
- Une requête sur 5 ans = plus de 230 000 appels KMS
- Tarif AWS : 0,03 $ pour 10 000 requêtes
La facture pique. Et elle pique d'autant plus que KMS n'est pas un service qu'on surveille instinctivement.
La solution : concaténer pour mutualiser
L'idée vient en regardant la structure des fichiers S3 :
130 fichiers par jour. Et si chaque jour n'en produisait qu'un seul ?
Un fichier au lieu de 130. Un appel KMS au lieu de 130. Sur 5 ans, de 230 000 appels à quelques milliers.
Implémentation : un script de concaténation Parquet, exécuté quotidiennement après l'ingestion. Moins de 50 lignes de code.
Résultats :
| Métrique | Avant | Après |
|---|---|---|
| Appels KMS mensuels | ~3 000 000 | ~162 000 |
| Coût KMS mensuel | ~4 000 $ | ~300 $ |
| Réduction des appels | - | -95 % |
| Économies annuelles | - | ~45 000 $/an |
De 3 millions d'appels à 162 000. Une optimisation d'une journée.
Leçon 1 : Les coûts cloud les plus élevés viennent souvent des services les plus discrets. KMS à 0,03 $ pour 10 000 requêtes paraît dérisoire. Multiplié par 3 millions d'appels mensuels, le dérisoire devient significatif.
Anomalie 2 : des licences fantômes à 20 000 $/an
En creusant au-delà du Cost Explorer : des licences logicielles toujours actives pour des personnes qui ne sont plus là.
C'est un classique des projets à fort turnover. Les développeurs partent, mais leurs comptes et licences restent. Personne ne pense à les résilier. La DSI paie, le budget est imputé au projet, tout le monde continue.
En auditant les abonnements nominatifs liés au projet, le constat est édifiant : des licences GitLab, Jenkins, Jira, Confluence et des comptes AWS toujours actifs pour des développeurs ayant quitté l'entreprise depuis des mois, parfois des années. Chaque départ non suivi d'un offboarding propre laissait une traînée de licences fantômes.
Chaque licence prise isolément paraît anodine. Cumulées : 20 000 $/an de licences inutiles.
La résolution ? Un mail à la DSI avec la liste des comptes concernés et leur date de départ.
Pas de code. Pas de refactoring. Juste de l'attention.
Leçon 2 : Le FinOps ne se limite pas aux services cloud. Les licences SaaS, les abonnements oubliés, les outils qui traînent d'une équipe à l'autre sont des postes de dépense invisibles qui s'accumulent silencieusement.
Anomalie 3 : 10 repositories, 10 pipelines CI/CD, 10 fois le coût
Le projet avait évolué de manière organique. Chaque cas d'usage dans son propre repository. Au total : plus de 10 repositories disparates, chacun avec sa pipeline CI/CD, ses images Docker, ses environnements de build.
Le problème, au-delà de la maintenabilité :
- 10 images Docker buildées et stockées séparément dans ECR
- 10 pipelines GitHub Actions qui tournent indépendamment
- Des dépendances dupliquées dans chaque repository
- Des images de base reconstruites N fois au lieu d'être réutilisées
La solution : un monorepo.
Consolidation des 10+ repositories en un seul monorepo unifié :
- Une image de base Docker partagée
- Des workflows GitHub Actions avec déclenchement par chemin (paths:), seul ce qui change est buildé
- Des dépendances mutualisées
Économies : 10 000 $/an (principalement les minutes GitHub Actions, plus les coûts ECR et bande passante de build).
Leçon 3 : L'architecture du code a un coût cloud direct. 10 repositories = 10 pipelines = 10 fois les coûts de CI/CD et de stockage d'images. La consolidation technique est aussi une optimisation financière.
Le bilan : 100 000 $/an
| Source d'économie | Économies annuelles | Effort |
|---|---|---|
| Optimisation KMS (concaténation fichiers) | 45 000 $ | 1 jour de dev |
| Suppression de licences inutilisées | 20 000 $ | 1 mail |
| Consolidation en monorepo | 10 000 $ | 2-3 semaines |
| Autres optimisations AWS* | 25 000 $ | Continu |
| Total | ~100 000 $/an | 1 mois |
*lifecycle policies S3, right-sizing Lambda, nettoyage snapshots EBS, rétention logs CloudWatch
Le ratio effort/gain est disproportionné. 45 000 $ pour une journée de travail. 20 000 $ pour un mail.
Pourquoi ça arrive systématiquement
Ce type de gaspillage n'est pas un cas isolé. C'est un pattern récurrent dans les projets cloud, amplifié par trois facteurs :
1. Le turnover efface la mémoire
Quand une équipe change, la connaissance des choix techniques, et de leurs conséquences financières, disparaît. L'équipe suivante hérite d'une infrastructure qu'elle n'a pas construite et qu'elle ne questionne pas.
2. Personne ne se sent responsable de la facture
Dans beaucoup d'organisations, la facture cloud est gérée par la DSI ou la finance. L'équipe de développement ne la voit jamais. Aucun lien entre le code qui tourne et l'argent qu'il coûte.
3. Les coûts cloud sont contre-intuitifs
Le cloud, c'est de l'unitaire multiplié par du volume. Et le volume est souvent invisible. 0,03 $ pour 10 000 requêtes KMS. Dérisoire. Sauf quand l'architecture en génère 3 millions par mois.
Checklist FinOps "Jour 1" pour une reprise de projet
Avant même de lire le code :
1. Ouvrir AWS Cost Explorer (ou l'équivalent chez le cloud provider). Regarder l'évolution des coûts sur 6 mois. Chercher les anomalies, les pics, les tendances à la hausse. Vous apprendrez énormément sur le projet.
2. Identifier le top 5 des services les plus coûteux. Un service inattendu dans le top 5 ? C'est un signal. Creusez.
3. Regarder les coûts par service ET par opération. Le diable est dans le détail : ce n'est pas S3 qui coûte cher, c'est un certain type de requête sur S3 qui coûte cher.
4. Auditer les licences et abonnements SaaS liés au projet. Demander à la DSI la liste complète. Vérifier que chaque licence correspond à un usage réel et à une personne encore en poste.
5. Chercher les ressources orphelines : instances EC2 arrêtées mais pas supprimées, snapshots EBS inutilisés, load balancers sans cibles, environnements de dev oubliés.
6. Vérifier la stratégie de stockage S3 : des données en Standard qui devraient être en Infrequent Access ou Glacier ? Des buckets qui grossissent sans politique de rétention ?
7. Regarder le coût des logs CloudWatch. La conservation de logs est un poste de dépense souvent négligé.
Le FinOps n'est pas un métier, c'est un réflexe
On associe souvent le FinOps à des équipes dédiées, des outils spécialisés, des dashboards complexes. Ces choses ont leur place dans les grandes organisations avec des budgets cloud à 7 chiffres.
Mais pour la grande majorité des projets, le FinOps le plus efficace, c'est un développeur curieux qui ouvre la facture. Pas besoin d'être certifié FinOps Practitioner. Pas besoin d'un outil à 50 000 $/an. Il faut juste s'y intéresser.
Trois convictions après cette expérience :
1. Les plus grosses économies viennent des problèmes les plus simples. Concaténer des fichiers, supprimer des licences oubliées, consolider des repositories. Rien de glamour, mais ça chiffre.
2. Le meilleur moment pour faire du FinOps, c'est la reprise d'un projet. Le regard est neuf. Les anomalies sautent aux yeux. Ce qui choque, c'est souvent ce qui coûte.
3. Chaque équipe devrait avoir accès à sa facture cloud. Si les développeurs ne voient jamais le Cost Explorer, ils ne peuvent pas optimiser ce qu'ils ne mesurent pas.
100 000 $ par an. En ouvrant un écran que personne ne regardait.
Le FinOps le plus rentable, c'est celui qu'on fait le premier jour.
Ce réflexe d'aller chercher là où ça fait mal plutôt que là où c'est visible, il s'applique à bien d'autres contextes. Comme la performance d'une API audio temps réel, où le bottleneck n'était pas non plus là où on le cherchait.
Pour aller plus loin, voici le contexte complet de cette mission : Du marécage à l'autonomie : redresser un projet data en tant que Tech Lead