Évaluation RAG : Bonnes pratiques pour assurer la mise en production
Vous pouvez retrouver un résumé de cette article en vidéo : Évaluation RAG en 30min
L'Évaluation est au coeur du développement de tout projet d’Intelligence artificielle. Nous nous intéressons dans cet article à la mise en place d’une évaluation rigoureuse pour assurer la mise en production des projets RAG (Retrieval Augmented Generation). Nous détaillons :
- La théorie de l’évaluation d’un projet RAG
- La pratique à travers l’approche émergente de l’Evaluation Driven Development (EDD)
Rappel du fonctionnement d’un projet RAG
Commençons par un petit rappel des spécificités d’un projet RAG. Si vous voulez en savoir plus sur le fonctionnement d’un projet RAG, je vous invite à regarder cette vidéo -ou cette article : Maîtriser le RAG. Nous nous intéressons ici aux bases qui influencent l’évaluation.
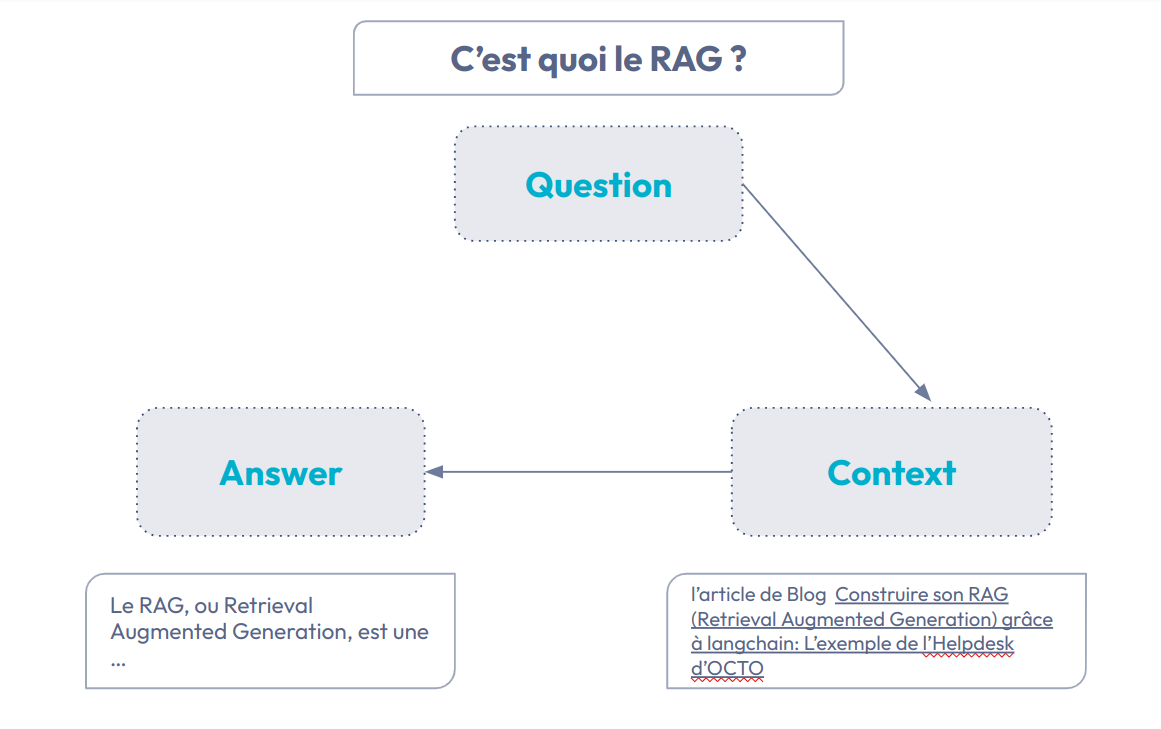
Fig 1 : Principe de fonctionnement d’un projet RAG
Pour rappel dans un projet RAG, trois artefacts entrent en jeu :
- La Question : par exemple “C’est quoi le RAG ?”
- Le Contexte : Des sources d’informations (Documents,audio, vidéo, etc..). Par exemple, on se limite aux articles du blog d’octo.
- La Réponse (Answer) : La réponse qui prend en compte mon contexte. Dans notre exemple, cela permet d’associer avec une forte probabilité le terme RAG à Retrieval Augmented Generation.
L'interaction avec un système RAG se compose donc en deux parties (fig 2 ) :
- RETRIEVER : la partie qui s'intéresse à ramener les informations utiles pour répondre à la question. La méthodologie s’approche de ce qui est connu pour un moteur de recherche
- GENERATION : La génération d’une réponse grâce à un LLM.
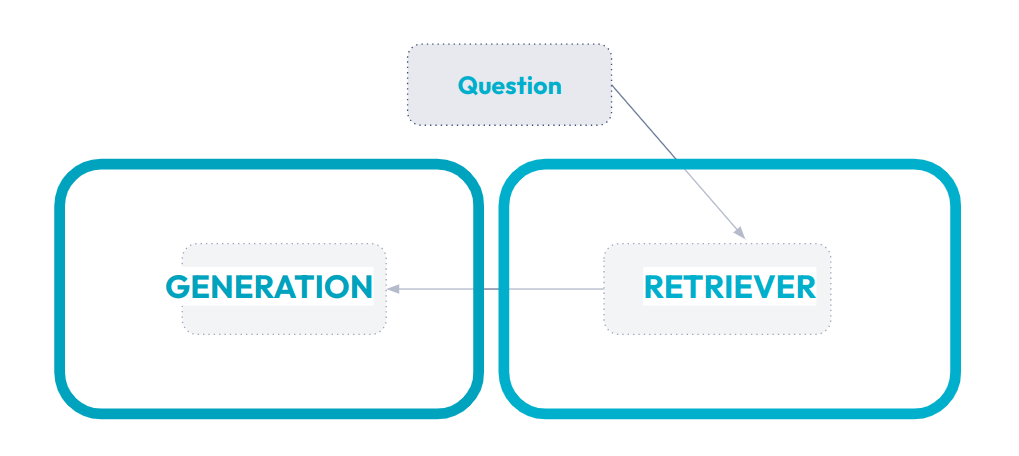
Fig 2 : RETRIEVER et GENERATION, les deux composantes du RAG.
I. Evaluation d’un projet RAG : la théorie
La théorie qui concerne l'évaluation consiste à créer des métriques que nous allons considérer fiables pour nous faire un avis sur différents critères de notre projet. Il y a Trois questions à se poser
1 - Quels sont les critères à évaluer ?
Fig 3 : définir des objectifs/critères
La première étape de l’évaluation RAG est de définir les critères (Targets) qui nous semblent importants à suivre. L’étude de langChain (State of AI 2023) faisait déjà apparaître un besoin d’évaluer sur plusieurs critères à la fois (2.3). Montrant la difficulté de se fier à un seul critère pour évaluer correctement un projet IA.
Evaluer la qualité en priorité.
Ce qu’on évalue en priorité reste souvent la qualité. Pour un RAG, les principaux concernant la partie Génération sont :
- Answer Faithfulness (fidélité de la réponse) : Est ce que la réponse généré est fidèle au contexte récupéré
- Answer Relevance (pertinence de la question) : Est ce que la réponse générée est pertinente par rapport à la question posée ?
Et pour la partie Retriever
- Context Relevance (Pertinence du contexte) : Est ce que les documents trouvés sont pertinents pour la question
De nombreux critères de qualité complémentaires sont également souvent introduit :
- Noise Robustness (Robustesse au bruit) : La robustesse au bruit évalue la capacité du modèle à gérer des documents bruités qui sont liés à la question mais qui ne contiennent pas d'informations utiles.
- Negative Rejection (Rejet négatif) : Le rejet négatif mesure la capacité du modèle à s'abstenir de répondre lorsque les documents récupérés ne contiennent pas les connaissances nécessaires pour répondre à une question.
- Information Integration (Intégration de l'information) : L'intégration de l'information évalue la capacité du modèle à synthétiser des informations provenant de plusieurs documents pour répondre à une question complexe.
- Counterfactual Robustness (Robustesse contrefactuelle) : La robustesse contrefactuelle teste la capacité du modèle à reconnaître et à ignorer les inexactitudes connues dans les documents, même lorsqu'on lui fournit des informations sur une éventuelle désinformation.
Des critères plus généraux ont également toute leur importance dans la réussite d’un projet RAG. Quelques exemples des plus fréquent rencontrés :
- READABILITY (Lisibilité) : Évaluer la lisibilité du texte généré ou des informations ramenées.
- LATENCY (latence) : Mesure la rapidité avec laquelle le système peut trouver des informations et répondre, ce qui est crucial pour l'expérience utilisateur.
- SAFETY (sûreté ou sécurité): Est ce que mon système est sensible à des attaques de prompt injection, etc..
- TOXICITY (Toxicité) : Est ce que mon RAG peut avoir un comportement toxique? Si je lui demande comment construire une bombe par exemple etc..
- BIAS : Est ce que mon RAG est sensible à certains Biais. Si la question est posée par un homme ou une femme est ce que ça impacte le format de la réponse ?
- FINANCIAL COST (cout financier) : Quel est le cout à l’utilisation de mon service
- ENVIRONMENTAL COST : Quel est l’impact environnemental ? Souvent on se restreint à la mesure Co2 de l’utilisation mais peut aller plus loin.
Nous avons données ici des idées de critères intéressants à évaluer pour s’assurer de la pertinence de notre projet RAG. Comme nous venons de la voir, les critères de qualité ne sont pas les seuls ! Il faut définir, en fonction du cas d’usage et notre positionnement, ceux les plus importants.
2. Comment j’évalue ?
Lorsqu’on connaît les critères/objectifs à évaluer, il faut maintenant construire les ensembles d’évaluation sur lesquelles les évaluations vont être construites. Pour rappel, trois artefacts composent un RAG : Question, Context, Answer. L’exercice va être donc simplement de construire ces listes de Questions et les informations attendues (appelé ground truth - vérité terrain) Context et Answer (fig 4).
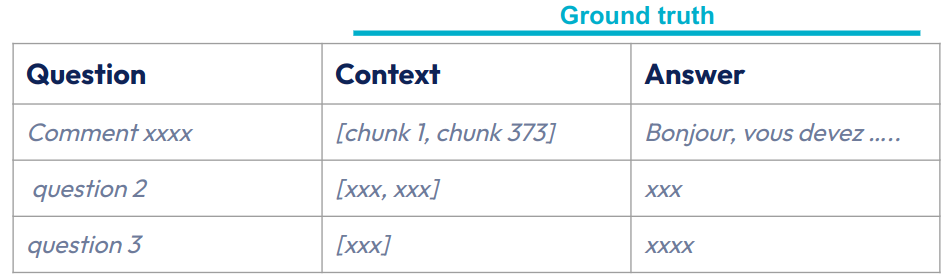
Fig 4 : Exemple d’ensemble d’évaluation
Combien de questions dans la base d’évaluation RAG ?
Le nombre de triplets __Q__uestion-__C__ontext-__A__nswer (QCA) à construire dépendra toujours de nos objectifs. Il faut que ça soit suffisamment important pour considérer les résultats comme interprétable, et pas trop important pour que les coûts d'exécution restent raisonnables.
OpenAI donne une idée du lien entre niveau de confiance et taille de l’ensemble d’évaluation (lien OpenAI ). Si je veux être capable d’affirmer qu’un RAG A avec une performance de 95% est meilleur qu’un RAG B avec 84% ( différence > à 10%) il faut environ une centaine de QCA.
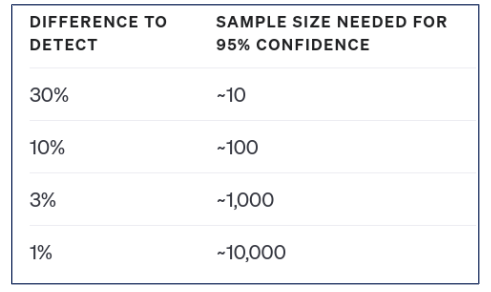
Fig 5 : lien entre niveau de confiance et taille d’ensemble d’évaluation
Quelles questions dans ma base d’évaluation RAG ?
Les ensembles d’évaluation doivent nous permettre d’évaluer les critères avec une certaine représentativité. C’est pourquoi dans une démarche d’évaluation rigoureuse plusieurs ensembles d’évaluation seront nécessaires.
Le premier ensemble d’évaluation, le principal, doit être représentatif de ce qu’on attend en production pour que les résultats obtenus à partir de celui-ci nous permettent de donner des métriques représentative de l’utilisation future (ou existante) de notre projet RAG.
Ensuite de nombreux ensembles (ou sous ensembles) d’évaluation seront constitués pour être plus représentatifs de certains sous groupes de nos utilisateurs, ou de certaines thématiques à expliquer avec par exemple pour certains critères :
- Toxicité, une sur représentation de questions incitant à un comportement non souhaité
- Negative Rejection, de nombreuses questions où la réponse n’est pas disponible dans le context
Comment Construire mon ensemble d’évaluation RAG ?
Il existe plusieurs façons de construire un ensemble d’évaluation :
- La principale méthodologie consiste à créer manuellement ces ensembles de Question, Context, Answer. Des experts métiers constituent ces ensembles.
- Si le projet RAG répond à un besoin existant (question au support, etc), il est possible d’utiliser des données d’historique pour constituer des ensembles d’évaluation représentatifs de ce que nous pouvons attendre en production.
- La dernière méthodologie qui émergent consiste à la générer automatiquement : Synthetic Data Generation (Génération de données synthétiques)
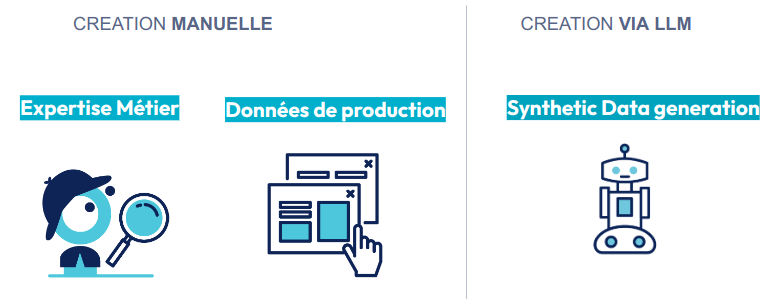
Fig 6 : Principales méthodologies de création d’un ensemble d’évaluation
Création d’ensemble d’évaluation via un LLM
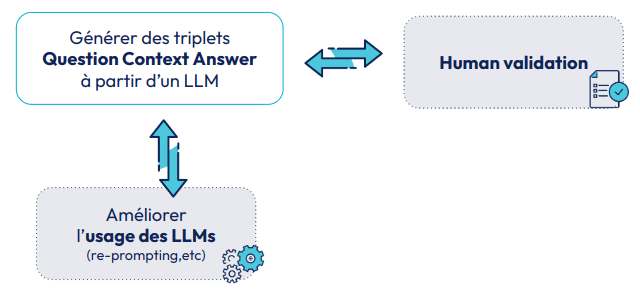
Fig 7 : Génération d’ensembles de validation RAG à partir d’un LLM
Une idée émergente consiste simplement à utiliser des grands modèles de langages (LLM) pour générer les triplets Question,Context,Answer. Les différentes méthodologies consistent à ajouter des étapes de validation humaines de ces triplets et des façons intelligentes d’utiliser les LLMs (prompt). A date, nous n’avons pas de méthodologie dominante, mais nous observons des exemples intéressants. Par exemple l’outil Ragas ( framework d’évaluation RAG), propose une méthodologie
La première étape consiste à créer un graphe de connaissance de l’ensemble des documents utilisés par le RAG. Ce graphe de connaissance constitue ensuite un des paramètres du prompt pour générer les QCA (fig 8). Pour ajouter de la variabilité, Ragas propose de générer ces QCA avec des styles différents, des personas différents ( Qui pose la question ? ) des tailles de questions différentes, etc..
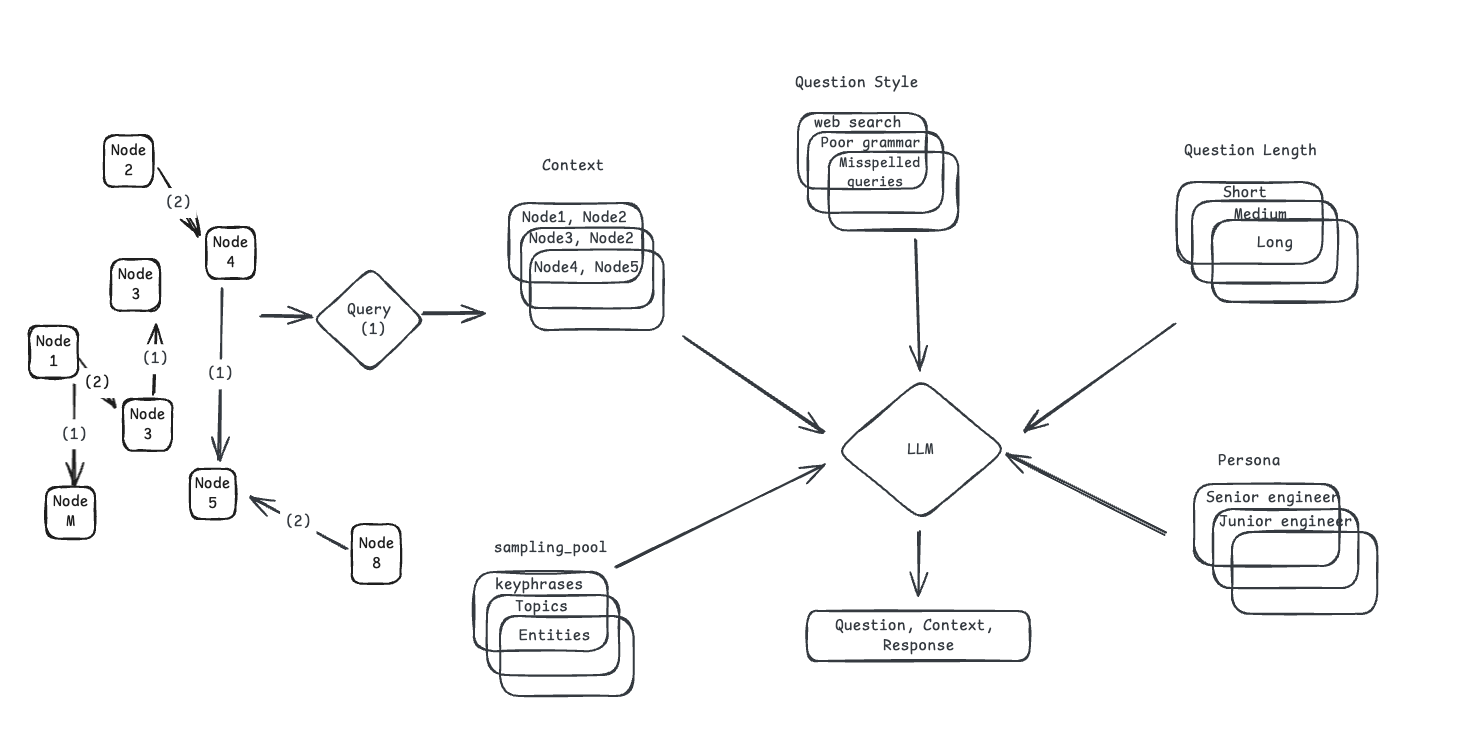
Fig 8 : méthodologie de création d’ensemble d’évaluation RAG via LLM - Ragas
D’autres méthodologies existent (par exemple proposée par AWS Generate synthetic data for evaluating RAG systems using Amazon Bedrock ) et vont émerger dans les prochains mois/années. Ce qui semble important reste de garder une petite étape de validation humaine pour confirmer et adapter la qualité des QCA.
Faut-il mettre à jour les ensembles d’évaluation RAG ?
Les ensembles d’évaluation ont une durée de vie. Il n’est pas rare qu’une réponse à une question varie au cours du temps. On n’invente rien, la plupart des entreprises ont souvent maintenu des FAQ avec la même problématique ! Il est donc important d’ajouter des informations relatives à la date de création de la QCA ainsi que la dernière date de validation ( principalement humaine ). Des stratégies de maintien de la qualité devront être mis en place (fréquence, et niveau de vérification dépendront du cas d’usage)
Comme tout artefact, les ensembles d’évaluation auront un cycle de vie, et on parlera donc de méthodologie de “versionning”.
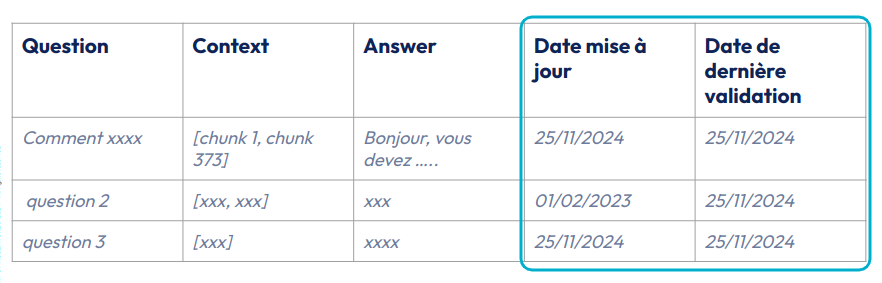
Fig 9 : Assurer la qualité d’un ensemble de validation
3. Comment Je mesure quantitativement ?
Nous connaissons les critères à évaluer, nous avons construit des ensembles d’évaluation pour obtenir des résultats représentatifs. Il est maintenant nécessaire de définir la méthodologie pour obtenir une valeur numérique (métrique) pour nos différents critères à partir de ces ensembles d’évaluation : Nous allons construire des évaluateurs (Scorers en anglais)
Les métriques classiques du Retriever - RAG
La partie “Retriever” d’un projet RAG peut être vu comme un moteur de recherche où l’objectif est de simplement de ramener les bons documents (on parle souvent de “chunks”). Les meilleurs évaluateurs pour calculer la pertinence du retriever ( RETRIEVER Relevance) s'approchent de ceux classiques des moteurs de recherche.
D’un côté les métriques qui ne prennent pas en compte le rang des éléments ramenés :
- Précision : Cette métrique mesure le pourcentage de documents récupérés qui sont pertinents par rapport à la question posée. Elle permet d'évaluer la capacité du système à minimiser les faux positifs, c'est-à-dire les documents ramenés qui ne sont pas pertinents.
- Rappel : Le rappel mesure le pourcentage de documents pertinents qui ont été récupérés par rapport à l'ensemble des documents pertinents disponibles. Cela permet de savoir si le système est capable de trouver la majorité des informations pertinentes pour une requête donnée.
Des métriques qui prennent en compte le rang :
- Mean Reciprocal Rank (MRR) : moyenne du rang du premier document sur l'ensemble des requêtes
- Mean Average Precision (MAP) la moyenne des scores de précision moyenne pour chaque requête.
Les métriques classiques de la “Generation” - RAG
Pour étudier la pertinence de la réponse (Answer relevance), les principales métriques consistent à mesurer l’effort minimum pour passer de la réponse générée à la bonne réponse “ground truth”.
Les métriques statistiques couramment utilisées pour calculer ces différences au niveau des mots sont :
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) [37] est un ensemble de métriques conçues pour évaluer le chevauchement de contenu entre le texte généré et le texte de référence. On peut résumer ROUGE comme une métrique qui s’intéressent au “RAPPEL” au niveau des mots.
- BLEU (Bilingual Evaluation Understudy) calcule la précision des n-grams dans le texte généré par rapport au texte de référence. C’est la PRÉCISION au niveau des mots.
__
__Certaines métriques plus intéressantes utilisent la représentation vectorielle, créée à partir d’un modèle d’embedding qui essaie de garder le sens sémantique. On commence à parler de tokens à la place de mots, les plus connues :
- BERTScore : En utilisant des embeddings de BERT, BERTScore mesure la similarité entre chaque mot de la réponse générée et les mots de la référence. Contrairement aux métriques basées sur des correspondances exactes, BERTScore permet d’évaluer la qualité sémantique de la réponse, même en présence de reformulations ou de synonymes.
- MoverScore utilise également des embeddings contextualisés pour calculer la distance entre les tokens du texte généré et ceux de la référence. Cependant, contrairement à BERTScore, qui repose sur une correspondance un-à-un (ou "alignement strict") des tokens, MoverScore permet une correspondance plusieurs-à-un (ou "alignement souple").
- WMD distance : Compare des textes en prenant en compte les distances minimum que doivent parcourir les mots du text A pour s’approcher d’un mot du text B.
Vous trouverez un bon article sur ces métriques ici : https://eugeneyan.com/writing/llm-patterns/#evals-to-measure-performance
Pourquoi les métriques statistiques classiques ne suffisent pas pour l’évaluation RAG.
Lorsqu’on a commencé à introduire des modèles d’embedding, nous nous sommes approchés de distances sémantiques ( où on regarde le sens des mots, phrases, etc..). Mais malgré ces progrès, comprendre l’importance de certains mots par rapport à la question n’est pas simple dans nos calculs de distances. L’exemple ci-dessous (fig 10) montre que des réponses avec un seul chiffre de différent sur des centaines de mots peuvent être totalement fausses. Pourtant les métriques précédentes auront tendance à donner une image d’une réponse très proche de la “ground truth” donc sans doute juste…

Fig 10 : Difficulté à comparer deux textes quasiment identiques.
Évaluation RAG, aller plus loin que les méthodologies statistiques.

Fig 11 : différents types d’évaluation RAG par rapport à la pertinence et la scalabilité
Les évaluateurs présentés précédemment, considérés comme les méthodologies classiques du traitement du langage (Traditional NLP), bien que scalable (temps d'exécution faible) manquent rapidement de pertinence sur l’évaluation RAG. C’est pourquoi, deux alternatives méthodologiques sont principalement présentes dans le cadre d’une Évaluation RAG : L’évaluation humaine, et l’utilisation de LLM en tant que juge (LLM as a judge).
Evaluation RAG grâce à l’évaluation humaine
La méthodologie la plus fiable pour évaluer la qualité d’un RAG reste l’évaluation humaine. Elle consiste tout simplement à demander à l’humain d’évaluer une réponse générée (RESULTS) par rapport à la réponse attendue (GROUND TRUTH). Souvent cela consiste simplement à maintenir un tableau (cf table X) où on demande à évaluer la pertinence de la question et de la réponse. On ajoute souvent une dernière colonne pour expliquer la raison de l’évaluation. Le problème du recours à l’humain consiste évidemment dans son coût. C’est pourquoi le recours à l’évaluation humaine est réalisé assez rarement en fonction de l’étape du projet : tous les X jours,semaines ou mois.
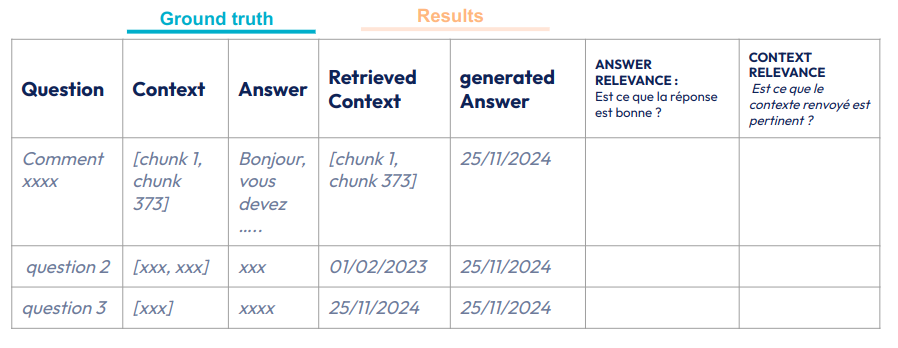
Fig 12 : Exemple d’ensemble d’évaluation pour vérification manuelle
L’évaluation - LLM as a Judge
“LLM as a Judge” est une méthodologie émergente pour évaluer un RAG qui consiste à utiliser un LLM ( le juge) pour évaluer une réponse en fonction de critères. L’objectif est de s’approcher de l’efficacité de l’évaluation humaine tout en réduisant considérablement les coûts financiers et le temps d’attente. Les principaux types de LLM as a judges :
- Pairwise comparison (comparaison par paires): Le Juge LLM compare deux réponses générées et décide de la meilleure
- Single Output Scoring (score à sortie unique) : Le Juge LLM attribue une note à une réponse générée en fonction de critères (fig 13). Une variante connue consiste à ajouter une réponse de référence (ground truth) dans le prompt pour aider le LLM.

Fig 13: Exemple de prompt pour un LLM as a judge qui fournit un score unique.
Est ce qu’un LLM sait évaluer ?
Des études, comme Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, ont montré que les LLMs pouvaient s’approcher d’une évaluation humaine : Les jugements des meilleurs LLMs (comme GPT4) sont très corrélés avec celui de la majorité des humains, identiques dans 85% des cas (alors que les humains se mettent d’accord que dans 81% des cas). Cette approche devient peu à peu incontournable pour évaluer efficacement. Dans son article state of AI, langchain déclarait déjà qu’en 2023, 58% des évaluations sur leur plateforme (langsmith) étaient réalisées par des LLMs. Nous recommandons cependant de toujours vérifier que les résultats issues de méthodologies quasi-automatiques (LLM as Judge) sont corrélés avec les résultats issues d’une évaluation humaine. Pour cela, sur un même critère (par exemple ANSWER RELEVANCE), réaliser une évaluation humaine et vérifier que les résultats issues d’un LLM as a Judge sont alignés.
Quel est le meilleur LLM pour évaluer / juger ?
La capacité de juger n’est pas donnée à tous les LLMs. De nombreux benchmarks ( comme JudgeBench ) émergent pour tenter de comparer les différents modèles dans leur capacité à distinguer les réponses correctes de celles incorrectes. Un Judge Arena a été créé pour laisser l’humain juger de la capacité du LLM à juger : le ELO des Juges LLM est créé !
On parle souvent de GPT4-o comme meilleur modèle de Juge, mais grâce au fine-tuning, des modèles OpenSource spécialisés (Prometheus) pour cette tâche peuvent être tout aussi pertinents (cf JudgeBench & Judge Arena)
Online Evaluation
Jusqu’à présent nous avons vu ce qu’on appelle l’Offline Evaluation qui consiste à réaliser des résultats sur des ensembles statiques que nous pouvons tout à fait lancer en “batch” (tous les X jours,semaines, mois). L’ Online évaluation ( parfois appelé évaluation temps-réel) s'intéresse plus particulièrement aux interactions utilisateurs avec notre application. C’est une évaluation essentielle en production. Les principaux éléments consistent à ajouter de nouveaux critères et éléments à suivre :
- Les traces (ou logs) dont les différents appels avec les LLMs
- Interactions utilisateurs : taux de clics (sur les sources ou la réponse), A/B testing, etc..
- Anomalie d’utilisations : Distribution des requetes, etc.
Les outils managés pour l’évaluation RAG
Nous sommes de plus en plus outillés dans notre processus d’évaluation. De nombreux frameworks et services managés peuvent être utilisés. Il est important de les comparer sur deux axes (fig 14) :
- Un premier axe (ordonné) orienté sur le monitoring : facilite le suivies de valeurs, de traces,etc. Langfuse est l’outil OpenSource le plus connu pour cette tâche.
- Un deuxième axe (abscisse) orienté sur le calcul des évaluateurs (scorers): facilite la création d’évaluateurs, et l’utilisation de LLM en tant que juge. Ragas est un framework Open Source connu pour faciliter la création de certains évaluateurs RAG à base de LLM as a judge.
La plupart des outils se complexifient et permettent d’intervenir sur différents axes, C’est le cas de MLFlow, solution OpenSource connue pour la mise en place des pratiques MLops, qui ajoute des fonctionnalités d’évaluation spécifiques aux LLMs.
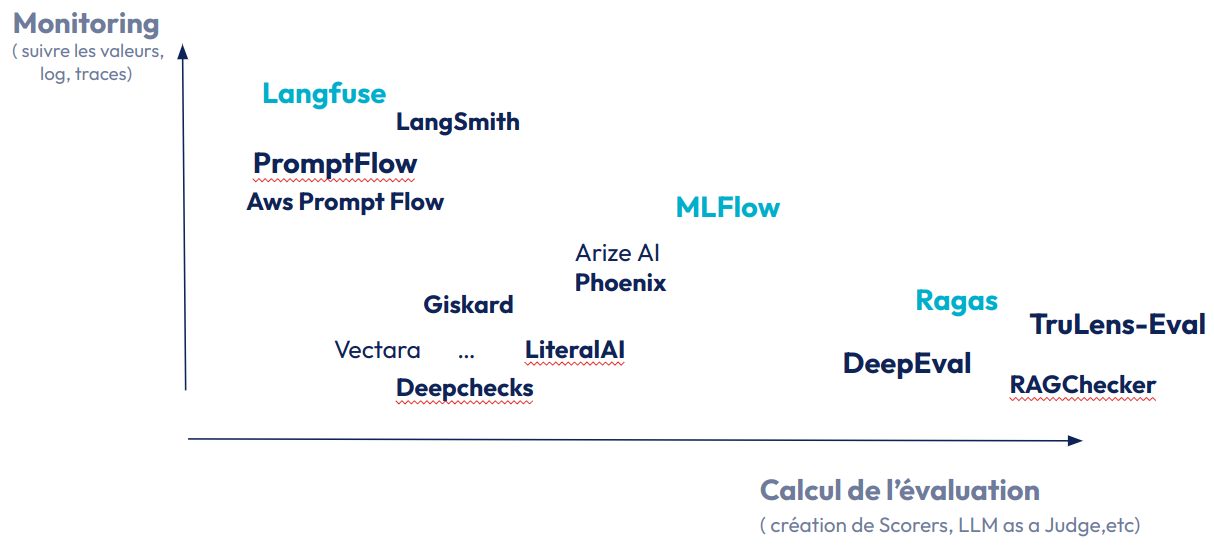
Fig 14 : Représentation de quelques frameworks/services managés spécifiques à l’évaluation RAG
En Pratique : Émergence du principe d’“Evaluation Driven Development”
Admettons que notre objectif est d’aller en production. Si on veut mettre et maintenir en production il faut notamment :
- Être confiant sur la qualité de mon produit.
- Être capable d’itérer et d’améliorer mon produit
Pour répondre à ces enjeux de production, des décennies de développement logiciel ont permis de faire émerger des méthodologies principalement basées sur des tests : Test-Driven-Development (TDD) ou Behavior Driven Development (BDD). Ces méthodologies ont cependant du mal à prendre en compte l’incertitude inhérente à l’utilisation d’IA ( LLMs notamment).
Evaluation Driven Development
L’Evaluation Driven Development (EDD) ou le développement axé sur l’évaluation est une méthodologie émergente pour les projets IA. Très inspirée de Test-Driven-Development (TDD) elle consiste à définir les critères d’évaluation avant de construire la solution.
Nous avons vu comment définir une stratégie d’évaluation (critères, méthodologie de calculs, etc). Dans un processus de développement classique basé sur des tests, nous prenons des décisions sur des critères qui sont binaires : réussite ou échec. On va donc définir des seuils pour ce dire si ce critère est satisfaisant ou pas ( fig 15 ). Ces seuils, associés à un niveau de qualité, dépendront des enjeux business et de la phase de notre projet. C’est pourquoi nous allons détailler la mise en place d’un workflow d’EDD au cours des trois phases structurante d’un projet de RAG :
- 1. EXPLO : L’exploration
- 2. BUILD : La mise en production
- 3. RUN : Le maintien en production
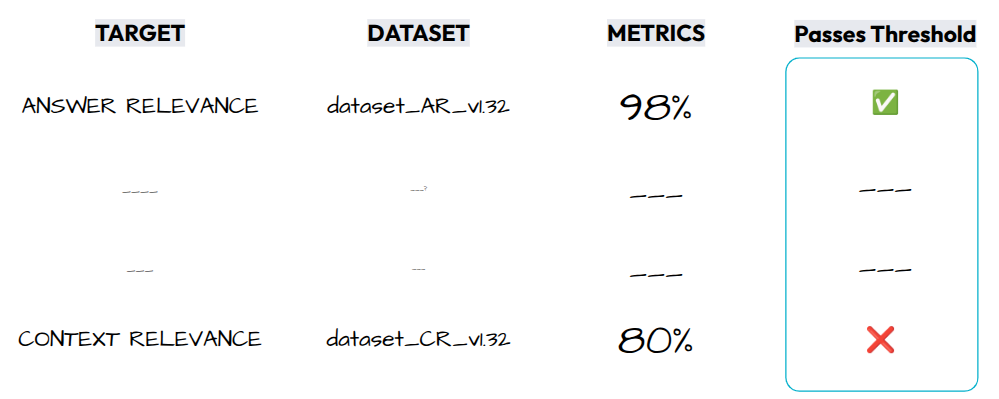
Fig 15 : Définir des seuils minimum pour les critères d’évaluation
Evaluation Driven Development Workflow : En phase d’exploration
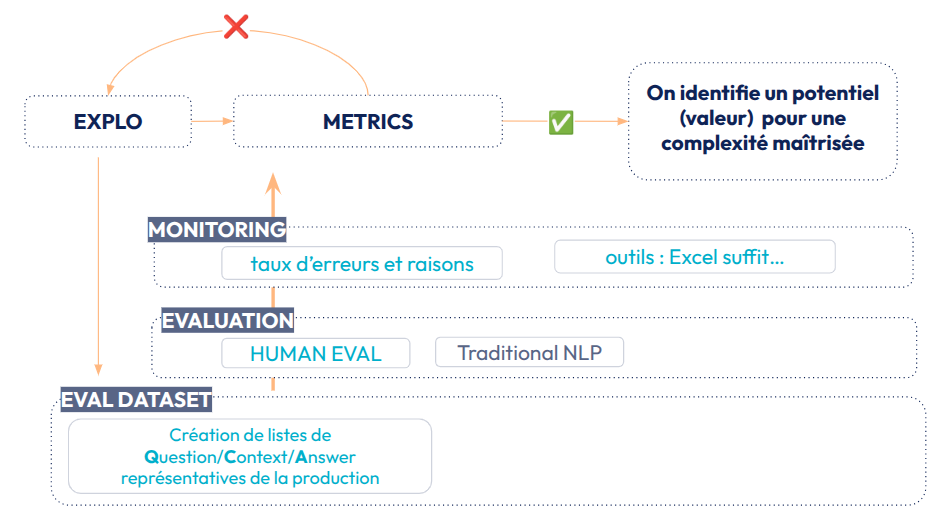
Fig 16 : Evaluation Driven Development Workflow - Phase d’exploration
En phase d’exploration l’objectif va être de valider la valeur tout en évaluant la complexité de passage à l’échelle. Un workflow d’Evaluation Driven Development nécessite de mettre en place un suivi des ensembles d’évaluation (EVAL DATASET). Le workflow d’Evaluation Driven Development, dans cette phase d’exploration, est assez simple. Premièrement, nous devons construire, un ensemble d’évaluation QCA (Question Context Answer) représentative de la production. Cette liste de QCA peut être limitée ( 10-100 cf chapitre sur la taille des ensembles d’évaluation), l’objectif étant d'estimer l'efficacité globale de notre solution. Cette taille restreinte permet de se concentrer principalement sur une évaluation humaine (EVALUATION). Quelques évaluateurs statistiques peuvent être mis en place, notamment sur la partie Retriever. L’objectif est d’obtenir en un temps restreint une idée de la pertinence des réponses atteignable en production. Si le niveau de qualité dépasse les seuils que nous nous sommes fixés, nous pouvons construire la solution.
Evaluation Driven Development Workflow : Déployer en production
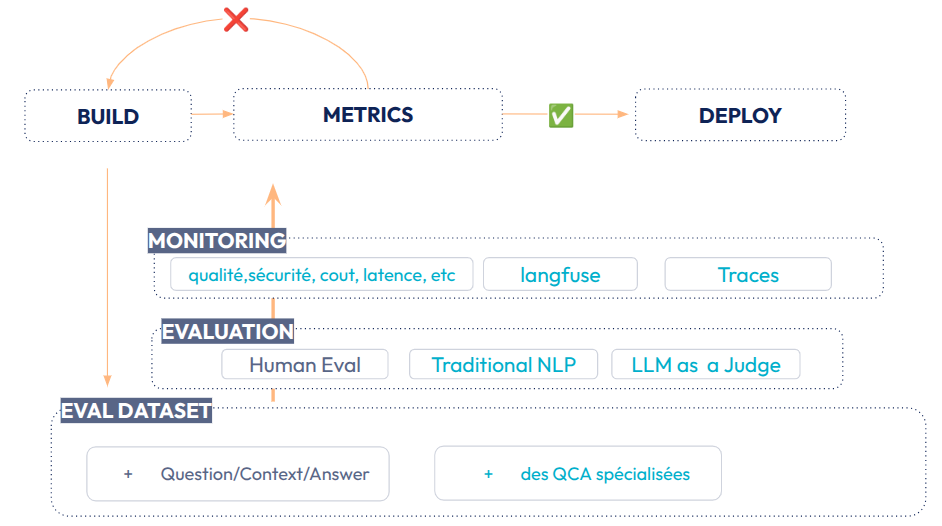
Fig 17: Evaluation Driven Development Workflow - Déployer en production
La qualité du RAG est suffisante pour justifier une mise en production. Notre objectif maintenant est donc d’être suffisamment confiant pour déployer en production.
La première étape consistera à faire grandir l’ensemble d’évaluation Question/Context/answer (QCA), avec notamment la création de sous-ensembles de QCA spécialisées sur des thématiques spécifiques. Tout en maintenant un peu d’évaluation humaine, nous allons cette fois mettre en place des évaluateurs plus automatisables, notamment à base de “LLM as a Judge”. La partie MONITORING devient maintenant essentielle. Nous devons donc nous outiller avec des outils, tels que Langfuse. Les critères d’évaluations seront plus variés, en plus de la qualité, nous suivrons des indicateurs opérationnels (coût, latence,etc). Afin de déboguer (et d’évaluer le coût), nous mettrons en place un suivi des différents appels et utilisations des LLMs ( “traces”).
✅ Si les valeurs de nos évaluateurs dépassent les seuils que nous avons fixés, nous sommes confiant pour déployer en production.
Evaluation Driven Development Workflow : Maintenir en production
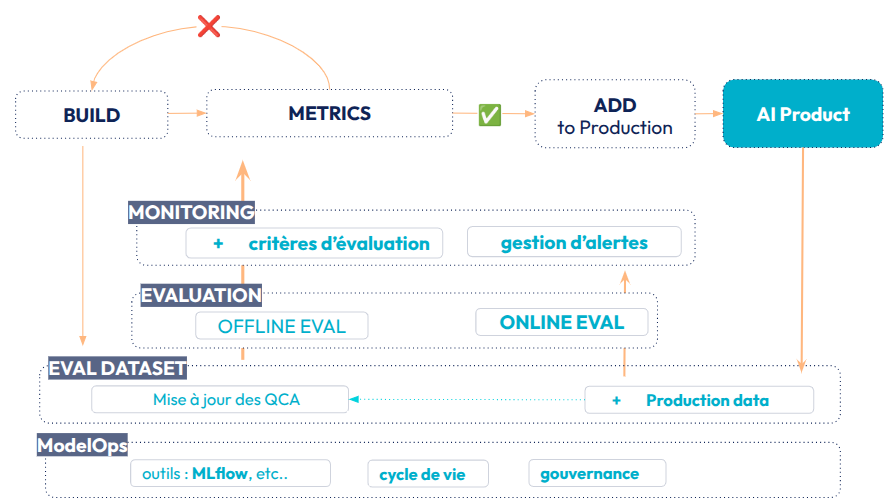
Fig 18: Evaluation Driven Development Workflow - Maintenir en production
Une fois notre projet RAG en production, l’objectif est de le maintenir tout en continuant à ajouter des améliorations. Étant déjà en production, nous avons des utilisateurs qui interagissent avec notre produit IA. Nous devons prendre en compte ces données de production (production data), d’un côté cela va nous permettre de créer des critères d’évaluation spécifique à ces interactions ( utilisation, taux de clics sur des sources, etc..). De l’autre, ces données de production servent à alimenter des ensembles d’évaluation QCA.
La mise en place d’une démarche ModelOps devient obligatoire ( bien que déjà très importante lors de la phase précédente). Celle-ci va consister à mettre en place un outil (comme MLflow) pour assurer la gouvernance et gérer le cycle de vie de nos différents artefacts, les ensembles d’évaluation notamment.
Conclusion
L’évaluation est au cœur de la réussite d’un projet RAG. Définir des critères, construire des ensembles d’évaluation pertinents et choisir les bons évaluateurs permet de s’assurer que notre système est fiable et efficace.
L’Evaluation Driven Development (EDD) apporte une approche structurée, en intégrant l’évaluation dès le début du développement et en l’adaptant à chaque phase du projet. Ce nouveau paradigme de tests pourrait devenir la méthodologie de développement logiciel dominante pour assurer la qualité et la fiabilité d’un produit intégrant des briques d’IA.
Bibliographie :
Yu, H., Gan, A., Zhang, K., Tong, S., Liu, Q., & Liu, Z. (2025). Evaluation of Retrieval-Augmented Generation : A Survey. https://arxiv.org/abs/2405.07437v2
Huyen, C. (s. d.). AI engineering. O’Reilly Online Learning. https://www.oreilly.com/library/view/ai-engineering/9781098166298/
Iusztin, P., & Labonne, M. (s. d.). LLM Engineer’s Handbook. O’Reilly Online Learning. https://www.oreilly.com/library/view/llm-engineers-handbook/9781836200079/
Articles sur l’évaluation : https://eugeneyan.com/writing/abstractive/ https://eugeneyan.com/writing/llm-patterns/#evals-to-measure-performance
Article Maitriser le RAG : https://blog.octo.com/maitriser-le-rag-retrieval-augmented-generation