Comptoir Gen IA - OCTO x GCP
Introduction
Cet article a pour but de résumer le comptoir donné par Antoine Moreau, lead de l’équipe retail et luxe au sein de l’atelier DATA & IA accompagné de Aleksander Usoltvev, spécialiste ML & Gen IA chez Google Cloud Platform (GCP).
Cette présentation est le résultat d’une collaboration entre OCTO et GCP, ou le but final est de présenter les enjeux au déploiement des solutions embarquant de l’IA générative mais aussi d’exposer deux démonstrateurs Gen IA produits par OCTO, embarquant les technologies disponibles sur GCP.
Les enjeux autour des LLMs aujourd’hui
Aujourd’hui, l’objectif est de déployer des solutions bout en bout qui répondent aux besoin des métiers, Antoine nous présente ci-dessous les 4 grandes problématiques associées à cet objectif :
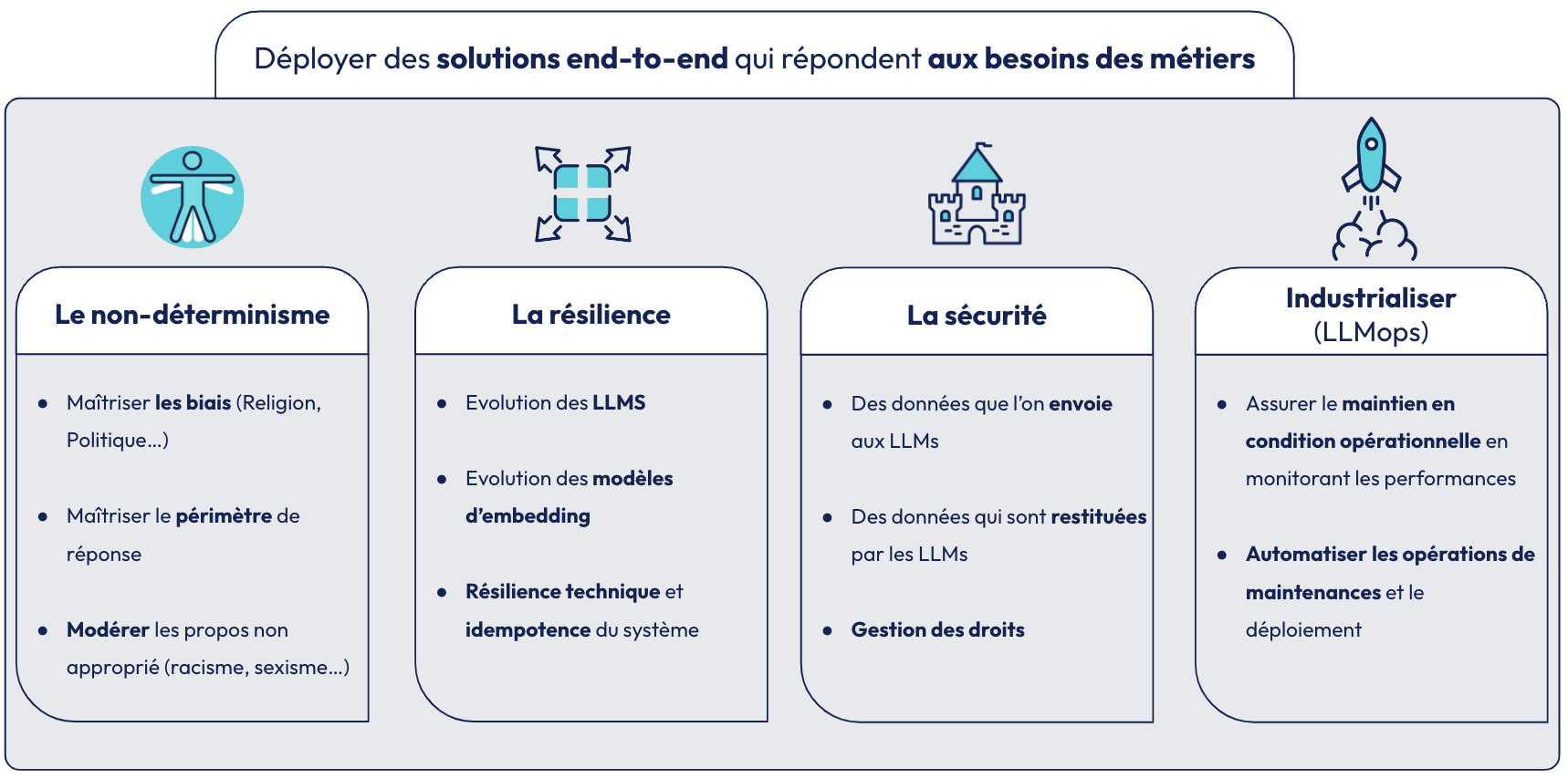
1. Contrôle du non-déterminisme des LLMs
Les modèles de langage (LLMs) sont intrinsèquement non-déterministes, produisant des réponses qui varient en fonction de facteurs aléatoires tels que les biais d’entraînement et les paramètres de génération. Pour mieux les contrôler, plusieurs aspects sont à considérer :
- Maîtrise des biais : Les LLMs sont entraînés sur des données massives provenant de diverses sources, souvent non filtrées et imparfaites, ce qui entraîne l’intégration de biais culturels, sociaux ou idéologiques. La gestion des biais consiste à les identifier et les contenir pour éviter des réponses inadéquates ou discriminatoires. Cela peut inclure un filtrage des données d’entraînement ou des ajustements post-entraînement pour neutraliser ces biais, garantissant ainsi une réponse plus neutre et appropriée.
- Périmètre de réponse : Les LLMs sont souvent trop génériques dans leurs réponses, proposant une "moyenne" de ce qu’ils ont appris. Ce caractère généraliste n’est pas adapté à des usages spécifiques où des réponses précises et pertinentes sont requises. La clé est de contraindre le modèle à rester dans un cadre spécifique, en ajustant le contexte fourni au modèle, en utilisant des techniques telles que le fine-tuning ou la spécialisation sur des domaines précis ou encore par des techniques de prompt-engineering.
- Modération des propos : Tout comme pour les biais, il est crucial d’intégrer des mécanismes pour modérer les réponses des LLMs. Cela permet d’éviter des propos inappropriés ou offensants, en particulier dans des environnements où la sécurité et l’éthique des réponses sont primordiales. Des systèmes de modération automatisés peuvent être déployés, avec des filtres sur les sorties ou des alertes en cas de contenu sensible.
2. La résilience des systèmes LLM
La résilience dans l’utilisation des LLMs est essentielle pour garantir la continuité et la fiabilité des services basés sur ces modèles. Plusieurs dimensions doivent être abordées :
- Évolution des LLMs : Les modèles évoluent rapidement, avec de nouvelles architectures et capacités. Assurer une résilience signifie anticiper ces évolutions et mettre en place des stratégies de mise à jour continue des modèles, tout en minimisant les interruptions de service. Il faut également évaluer l’adaptation des infrastructures pour intégrer de nouveaux modèles plus performants.
- Évolution des modèles d’embeddings : Les embeddings jouent un rôle central dans la manière dont les LLMs interprètent et génèrent du texte. L’évolution des techniques d’embeddings doit être suivie pour garantir une représentation plus fine et précise des données textuelles. Cette évolution permet d’améliorer la qualité des réponses tout en assurant une compatibilité avec les nouveaux besoins et cas d’usage.
- Résilience technique et idempotence : Du point de vue technique, les systèmes utilisant des LLMs doivent être robustes et capables de résister aux pannes. L'idempotence garantit que la même opération, répétée plusieurs fois, produit le même résultat sans effets indésirables, ce qui permet d'assurer la reproductibilité des réponses en cas de nouvelles tentatives ou d'erreurs, renforçant ainsi la stabilité et la fiabilité du système. On peut aussi citer des enjeux d’idempotence notamment dans la mise à jour des bases vectorielles pour les RAGs (cf l’article de PPR).
3. La sécurité des interactions avec les LLMs
La sécurité est un pilier fondamental lorsqu’il s’agit de traiter avec des LLMs, que ce soit pour protéger les données sensibles ou pour garantir la conformité aux réglementations.
- Protection des données envoyées aux LLMs : Lorsque des utilisateurs soumettent des requêtes à un modèle de langage, ces données peuvent contenir des informations sensibles. Il est essentiel de s’assurer que ces données sont protégées, via des mécanismes tels que le chiffrement et des politiques strictes de gestion des accès. Cela inclut également la limitation de la rétention des données envoyées.
- Sécurisation des données restituées par les LLMs : Les réponses générées par les modèles peuvent parfois inclure des informations qui n’auraient pas dû être divulguées, notamment si le modèle a été mal configuré ou s’il a appris sur des données incorrectes. La gestion des réponses doit inclure des vérifications pour éviter la fuite d’informations sensibles, comme des noms ou des adresses.
- Gestion des droits des LLMs (multi-modalité, etc.) : À mesure que les LLMs évoluent, ils deviennent capables de traiter plusieurs types de données (texte, image, audio, etc.) mais aussi d’effectuer des actions. La gestion des droits d’accès à ces capacités multimodales est essentielle pour limiter les actions que le modèle peut entreprendre et protéger les utilisateurs contre des actions non autorisées.
4. Industrialiser l'utilisation des LLMs
Pour intégrer pleinement les LLMs dans un cadre industriel, plusieurs étapes sont nécessaires afin de garantir leur maintenance, leur performance et leur fiabilité à long terme :
- Maintien en condition opérationnelle (MCO) : Un suivi constant des performances des LLMs est crucial. Cela inclut des indicateurs de qualité de réponse, de latence, et de consommation de ressources. Un monitoring proactif permet de détecter et corriger les problèmes avant qu’ils n’affectent les utilisateurs finaux, assurant ainsi une continuité de service.
- Automatisation des opérations de maintenance et de déploiement : La mise en production d’un LLM ne doit pas être une opération manuelle répétitive. Automatiser les déploiements, les mises à jour et les opérations de maintenance (comme l’adaptation aux nouveaux ensembles de données) permet d’assurer une évolutivité et une réactivité face aux changements, tout en réduisant les erreurs humaines.
Ces points couvrent les défis et les solutions associés au développement, à la gestion et à l’industrialisation des LLMs dans des environnements contrôlés.
Accélérateur Gen IA - OCTO x GCP
Nous pouvons passer à la présentation de l’accélérateur Gen IA OCTO x GCP, nous voyons ci-dessous la slide présentée au comptoir décrivant les 3 axes principaux.

L'accélérateur développé en collaboration avec Google Cloud Platform (GCP) repose sur trois axes principaux. Premièrement, il offre une infrastructure éprouvée et évolutive, optimisée pour des cas d'usage variés tels que la recherche augmentée par génération (RAG), le multimodale, et l'orchestration des interactions entre différents modèles. Cela permet une intégration fluide des modèles de langage dans des environnements complexes tout en garantissant robustesse et performance. Deuxièmement, l’accélérateur s’appuie sur un code applicatif développé à l'aide de LangChain, bénéficiant de plusieurs contributions open source, y compris celles de PPR et des articles techniques tels que le blog d'Octo. Ces contributions enrichissent l’écosystème tout en facilitant l'implémentation rapide des solutions basées sur les LLMs. Enfin, une brique d’automatisation complète l’accélérateur, comprenant des outils de monitoring, de test et d’optimisation des performances tels que Phoenix ou Giskard. Cette brique garantit un déploiement et une maintenance automatisés, maximisant ainsi l'efficacité tout en réduisant les interventions manuelles nécessaires.
Démonstrateurs Gen IA - OCTO x GCP
Les démonstrateurs d’IA Gen illustrent la puissance des modèles pour créer du contenu multimédia personnalisé et pertinent. Le premier démonstrateur est un générateur de publicités capable de produire des textes, des images, de l’audio, et bientôt des vidéos. Ce démonstrateur vise à répondre aux besoins spécifiques des entreprises dans le domaine du marketing et de la publicité en automatisant la création de contenu pour des campagnes promotionnelles.
Le deuxième démonstrateur est basé sur la technologie RAG (Retrieval Augmented Generation), dans le cadre d’un chatbot basé sur une base de données d'articles. Ce chatbot interagit dynamiquement avec une base de connaissances pour fournir des réponses précises et contextualisées à un utilisateur.
ROI des démonstrateurs :
L’objectif ici est d’aller rapidement vers des solutions concrètes et exploitables : pas de Proof of Concept (PoC) peu exploitable, mais des Minimum Viable Products (MVP) en deux semaines, bien définis et fonctionnels. Cette approche permet non seulement d’assurer la conformité et la sécurité des systèmes, mais également de garantir leur évolutivité et leur capacité à s'adapter à des besoins changeants. Les cas d’usage typiques incluent la génération, la recherche et la synthèse de contenus.
Démonstrateur 1 : My Marketing Assistant
Ce démonstrateur montre un assistant marketing capable de générer des publicités adaptées à plusieurs formats (texte, image, etc.) pour des entreprises de retail. L'utilisateur peut configurer divers paramètres :
- Langue : Choix de la langue pour la publicité.
- Produit : Sélection du produit à promouvoir avec ses descriptions détaillées.
- Audience : Définition de l'audience cible.
- Plateforme : Choix de la plateforme où la publicité sera diffusée (par exemple, réseaux sociaux, sites web).
- Campagne : Définition du sujet de la campagne promotionnelle.
- Température : Ajustement de la créativité du modèle en jouant sur la température des prédictions.
- Ton : Sélection du ton approprié pour la publicité (formel, informel, humoristique, etc.).
Le résultat est une publicité personnalisée et pertinente, avec un contrôle complet pour s’assurer que le produit ou le message n’est pas altéré par le modèle. Phoenix est utilisé pour le monitoring des interactions avec le modèle, en mesurant des métriques clés comme la latence, le nombre de tokens utilisés, et les évaluations automatiques (toxicité, hallucinations). Ce suivi permet de garantir la qualité et la sécurité des publicités générées.
La forte valeur ajoutée de ce démonstrateur réside dans sa capacité à répondre aux besoins métiers en générant du contenu instantanément, efficacement, et de manière personnalisée, ce qui permet de cibler les utilisateurs à un niveau de granularité précis.
Nous pouvons voir ci-dessous l’architecture et les différentes intéractions entre les modèles menant à ces résultats :
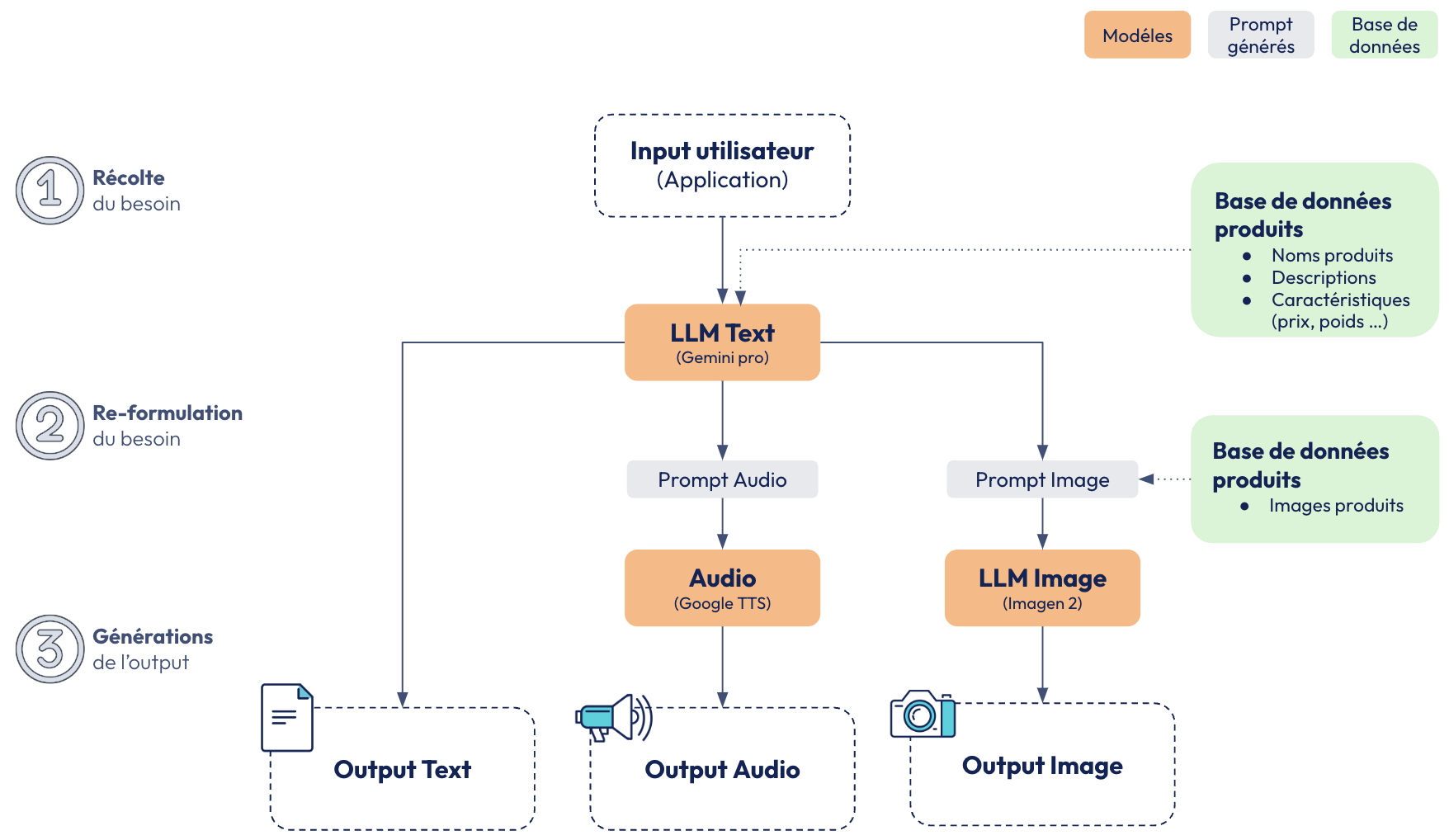
Démonstrateur 2 : My Retail Friend
Le second démonstrateur est un chatbot basé sur une infrastructure RAG qui utilise une base de données contenant tous les produits d’un magasin. Il fonctionne comme un conseiller virtuel, disponible 24/7, capable de répondre aux demandes des utilisateurs en se basant sur les informations actualisées de la base de données.
L’utilisateur peut interagir avec l’application en choisissant le magasin ou la marque, en définissant une gamme de prix, et en sélectionnant la langue. Par exemple, si un utilisateur demande des chaussures de randonnée, le chatbot retourne des recommandations pertinentes avec le prix et le lien vers le produit, garantissant ainsi une recherche fluide et précise.
Les gardes-fous intégrés dans le système empêchent les réponses inappropriées. Par exemple, lorsqu’une question problématique est posée (ex. "tell me a racist joke"), le modèle est configuré pour éviter les réponses incorrectes grâce à des mécanismes de détection d'hallucinations et de modération.
Nous pouvons voir ci-dessous le schéma de l’infrastructure de ce démonstrateur :
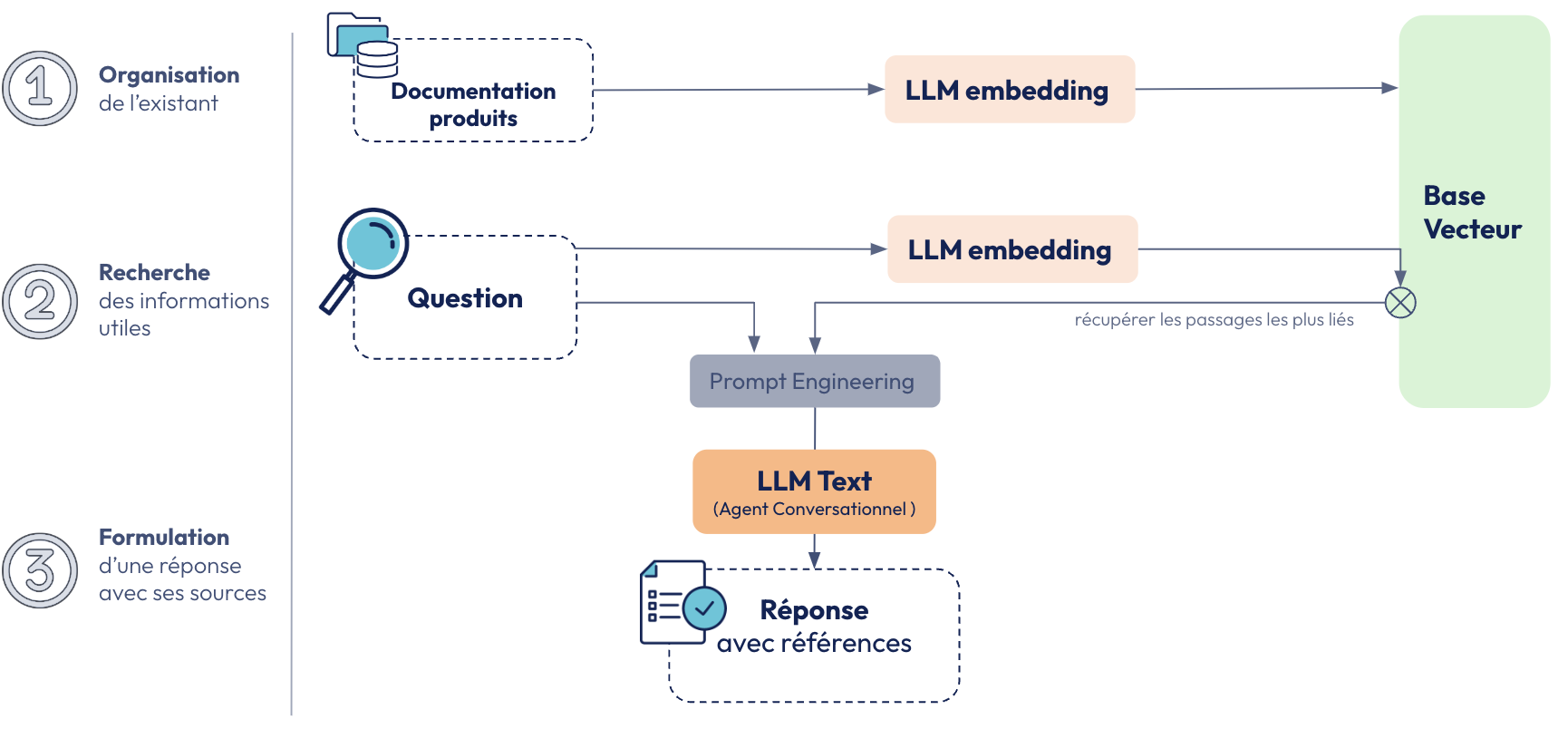
La valeur ajoutée de ce démonstrateur est triple :
- Disponibilité : Un conseiller disponible en continu, répondant aux demandes de manière rapide et efficace.
- Précision : Des informations fiables et actualisées, tirées directement de la base de données.
- Recommandation : Un nouveau canal de recommandation pour améliorer l’expérience utilisateur en offrant des produits adaptés aux besoins spécifiques des clients.
Enjeux et Cas d’usage des démonstrateurs :
Les démonstrateurs illustrent plusieurs enjeux globaux de l’utilisation des LLMs dans le cadre de la l’IA générative, notamment la résilience, la sécurité, et le contrôle du caractère aléatoire des réponses. Ces enjeux sont cruciaux pour garantir une performance stable et fiable dans des environnements complexes.
Dans le cadre de la génération publicitaire, il est essentiel d’optimiser la création de contenu en automatisant les processus via l’ingénierie des prompts et en testant différents modèles. Le monitoring des interactions avec les LLMs est clé pour s'assurer que les résultats sont pertinents et conformes aux attentes. L’automatisation va jusqu'à l’interfaçage direct avec des plateformes, permettant par exemple de publier automatiquement sur Instagram ou d’autres canaux.
Pour le démonstrateur RAG, le principal défi réside dans la construction et l’alimentation de la base de connaissances. La qualité des résultats dépend fortement de cette base, ce qui implique de mettre à jour régulièrement les données et de découper les fichiers pour assurer une recherche efficace. Alors que les LLMs évoluent rapidement, les bases RAG resteront indispensables, d’où l’importance d’investir dans leur développement.
Enfin, l’optimisation des retrieveurs et la gestion des prompts jouent un rôle fondamental dans la performance et la pertinence des réponses générées, ce qui permet de maximiser l’impact de ces démonstrateurs dans les environnements de production.
Aleksander : Focus sur GCP
Aleksander conclut en mettant l'accent sur la manière dont Google Cloud Platform (GCP) permet d’accélérer la mise en place de solutions innovantes comme celles présentées ici. Il souligne l'importance de la "readiness" des entreprises, c'est-à-dire leur capacité à intégrer rapidement des solutions d'IA tout en assurant la sécurité, la conformité, et la scalabilité.
GCP propose une infrastructure optimisée pour ce type de projets à travers plusieurs outils intégrés dans ce qu'ils appellent leur "AI Hypercomputer". Ce dernier se compose de plusieurs modules :
- Model Garden : Une plateforme ouverte où les utilisateurs peuvent choisir parmi une large variété de modèles préentraînés, qu'il s'agisse de modèles développés par Google (comme Gemini pour l'audio, l'image, et le texte) ou par des partenaires clés comme Mistral, Meta, et Anthropic. D’ailleurs, GCP est le premier fournisseur à avoir eu accès aux modèles Mistral, renforçant ainsi son offre diversifiée.
- Model Builder : Un outil destiné aux data scientists qui leur permet de construire et de fine-tuner leurs propres modèles tout en s’appuyant sur l’infrastructure robuste de GCP.
- Agent Builder : Un environnement low-code conçu spécifiquement pour les cas d'usage comme les RAG (Retrieval-Augmented Generation), permettant aux entreprises de développer rapidement des solutions de génération de contenu ou d’interactions complexes sans avoir besoin d’une expertise en IA.
Présentation de Model Garden
Aleksander explique que la plateforme Model Garden est ouverte et conçue pour exploiter des SDK open source ainsi que des modèles dont les poids sont accessibles et modifiables. Les utilisateurs peuvent ainsi choisir parmi une gamme de modèles open-source tout en ayant accès aux modèles propriétaires de Google tels que Gemini pour des applications audio, image, et texte.
La force de GCP réside également dans ses partenariats stratégiques avec des leaders de l'IA comme Mistral, Meta, et Anthropic, élargissant ainsi les options disponibles pour les entreprises souhaitant intégrer des modèles de pointe dans leurs processus.
Vos données restent vos données
Un des points d’insistance d’Aleksander est que "vos données sont toujours vos données". Google Cloud s'engage à ce que les entreprises gardent un contrôle total sur leurs données et leur propriété intellectuelle. Lorsqu’un modèle est fine-tuné sur GCP, il reste dans le périmètre de l’entreprise qui en conserve la propriété. Cela signifie que les entreprises peuvent travailler en toute confiance, sachant que leur propriété intellectuelle est protégée.
De plus, GCP met à disposition des outils pour monitorer en permanence l’accès et l’utilisation des données, avec des logs détaillés, et respecte les réglementations européennes telles que le RGPD et s’inscrit dans les discussions en cours sur l’AI Act. Cela offre aux entreprises une transparence totale et des garanties de conformité aux lois en vigueur.
IA Responsable
Aleksander insiste également sur l’approche de l’IA responsable adoptée par Google Cloud. Ils reconnaissent les risques associés à l'IA générative et mettent en place des outils pour aider les entreprises à monitorer l'impact de leurs modèles. Des filtres de sécurité sont disponibles pour réguler les résultats des modèles, que ce soit via des contrôles internes ou des filtres externes, assurant ainsi que les modèles restent alignés avec les attentes éthiques et légales.
Évaluation et actualisation des modèles
Enfin, GCP permet également de "grounder" les modèles, c’est-à-dire de les enrichir en temps réel avec des données d’actualité pour garantir qu’ils restent pertinents. Les outils d’évaluation permettent de comparer les résultats des modèles avec les changements apportés aux prompts, offrant ainsi une transparence sur la performance et l’évolution des modèles au fil du temps.
Grâce à cet ensemble d’outils et de services, GCP fournit aux entreprises tous les moyens nécessaires pour exploiter les avantages de l’IA générative tout en s'assurant que ces solutions sont robustes, conformes, et sécurisées.
Conclusion
En conclusion, l’utilisation des LLMs et des solutions d’IA générative comme le RAG ouvre des perspectives immenses pour les entreprises, qu’il s’agisse de générer du contenu publicitaire, de proposer des services personnalisés via des chatbots, ou d’optimiser les interactions entre les modèles. Grâce à l’infrastructure de GCP, des outils puissants comme Model Garden et des services de monitoring avancés, il est désormais possible d’intégrer ces technologies dans des environnements de production avec rapidité, sécurité et scalabilité.