La GenAI gratuite et sécurisée : les LLMs locaux directement sur vos devices
Nos ordinateurs et nos smartphones sont de plus en plus puissants et rapides. Pendant des années, les différents constructeurs ont mené une course à la plus haute résolution décran, à la meilleure qualité photo ou vidéo (se rappeler par exemple les campagnes de publicité d’Apple sur le thème « réalisé avec un iPhone »), mais aussi aux première fonctionnalités d’intelligence artificielle, notamment celles basées sur le machine learning. Cette course a conduit à l'intégration de CPU et de GPU de plus en plus puissants dans les smartphones, en particulier dans les modèles haut de gamme.
Au moment de l’arrivée de l’IA générative, nous nous retrouvons ainsi, presque par hasard, avec des smartphones déjà capables de faire tourner en local de petits modèles compactés.
Ces smartphones « GenAI ready » semblent d’autant plus attrayants qu'ils offrent une solution à deux des principaux blocages de l’IA générative : le coût de son utilisation et la protection de données. Faire tourner vos LLMs sur les smartphones de vos utilisateurs permettrait d’éviter une facture au token salée auprès d’OpenAI ou d’exploser votre facture cloud pour pouvoir héberger votre propre modèle. Cela permettrait également de ne pas faire sortir de potentielles données personnelles des devices de vos utilisateurs et ainsi de les protéger.
Mais alors pourquoi la magie des modèles hébergés localement n’est pas encore répandue à travers toutes les applications ? Que nous manque-t-il pour pouvoir tirer pleinement profit de ces potentiels millions de mini-serveurs d’intelligence artificielle ?
Et bien pour commencer, la difficulté rencontrée sur les smartphones ne vient finalement pas de la puissance de calcul, mais plutôt de la capacité de stockage. Non pas que nos smartphones aient un stockage particulièrement faible. Mais l’espace de stockage que vos utilisateurs seront prêt à laisser à votre application le sera. Prenons l’exemple d’un utilisateur venant d’acheter un Google Pixel 10 Pro, il aura beau avoir un stockage de 256 Go, si votre application lui prend 2Go, le risque d’une désinstallation sera fort.
Et pour faire tourner un modèle d’IA, il faut l’héberger. Aujourd’hui, les modèles les plus compacts vous prendront à minima entre 2 et 4 Go d’espace de stockage. Pour une application grand public, c’est déjà rédhibitoire.
Alors comment contourner ce problème ? Fort heureusement pour nous, les GAFAM (Google, Apple, Facebook, Amazon et Microsoft), dans leur quête de nous rendre toujours plus accros à l’IA ont déjà bien avancé sur la solution : embarquer un modèle dans des parties internes du fonctionnement de votre device, et rendre ce modèle accessible aux applications externes. De cette manière, le « coût de stockage » est pris en charge par des applications que vous ne désinstallerez jamais, et le modèle est accessible partout.
*
*Découvrons ensemble, plateforme par plateforme, comment cela fonctionne et quelles sont les limitations.
Gemini Nano Android
Sur Android, la solution est choisie par Google, qui développe le système d’exploitation. Nous y retrouvons donc Gemini Nano qui sera embarqué sur le téléphone sous la forme d’une application système. Cette application étant utilisée par des fonctionnalités au cœur de l’OS (le clavier, les outils d’accessibilité, ou les outils de prise de note), il n’est pas possible de la désinstaller (au maximum, vous pouvez la désactiver), ce que peu de vos utilisateurs feront.
Ce modèle n’est disponible que sur un nombre limité de modèles (les derniers modèles de chaque marque) mais plus le temps va passer et plus de nouveaux modèles de téléphone sortiront jusqu'à qu'ils soient quasiment tous équipé de ce service. Pour faire simple, le service AI Core met à votre disposition un SDK nous permettant d'interagir très simplement avec le modèle Gemini nano.
Le modèle est multimodal et offre les capacités suivantes :
- Résumé : résumer des articles ou des conversations sous forme de liste à puces.
- Relecture : relisez de courts messages de chat.
- Réécrire : réécrivez des messages courts dans différents tons ou styles.
- Description de l'image : générez une brève description d'une image donnée.
- Reconnaissance vocale : transcrire le contenu audio parlé en texte.
- Requête : générez du contenu textuel à partir d'une requête personnalisée, multimodale ou textuelle uniquement.
Aujourd’hui, Google utilise déjà Gemini Nano sur les téléphones Pixel 9 et 10 sur plusieurs fonctionnalités clés telles que son clavier natif (pour reformuler vos messages notamment) ou les outils d’accessibilités pour analyser des images. Si le modèle n’est encore disponible que sur peu de devices, vous pouvez en revanche être assurés du fait que vos utilisateurs n’iront pas le désinstaller.
Apple Foundation
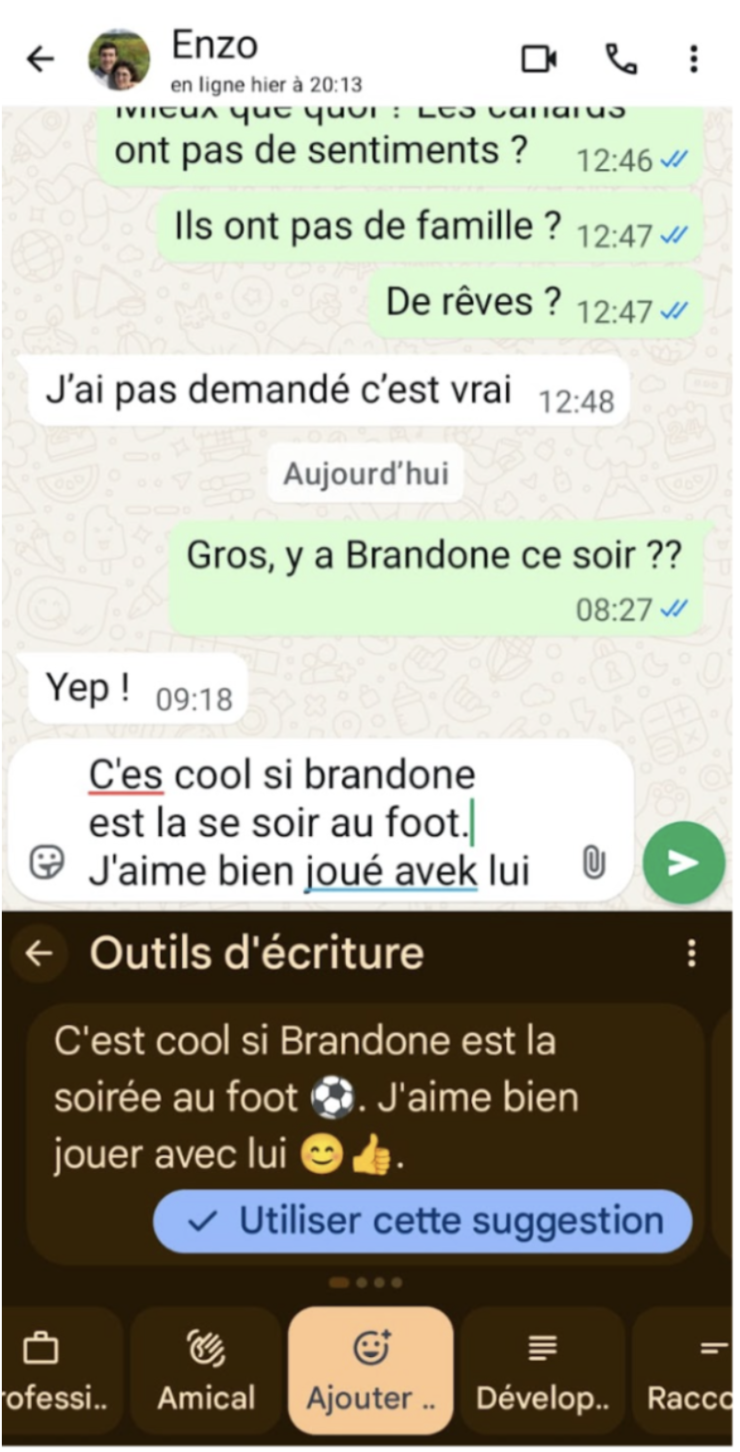
Sur iOS, vous l’avez sûrement remarqué, Apple a sorti une nouvelle suite de fonctionnalités de GenAI appelée Apple Intelligence. Et bien qu’Apple Intelligence n’utilise pas uniquement un modèle local (on peut notamment utiliser ChatGPT pour avoir de meilleurs résultats), il y a bien un modèle d’Apple qui gère la plupart des tâches et s’assure que vos données ne quittent pas le téléphone sauf si vous l’avez explicitement demandé. Ce modèle est accessible au développeur par le biais d’un SDK natif : Apple Foundation.
Apple Foundation Models, c’est la brique d’IA d’Apple que les développeurs peuvent utiliser directement dans leurs apps pour générer et comprendre du texte. Le framework est pensé pour des cas concrets comme les résumés de texte, les réponses intelligentes ou des suggestions personnalisées, avec une API Swift plutôt simple à intégrer.
Apple intelligence étant au coeur de l’expérience proposée sur les iPhones, une large partie de vos utilisateurs ont déjà le modèle à disposition et il est très improbable qu’ils le désactivent (sauf à désactiver Apple Intelligence, ce qui sera un signal d’une faible appétence pour des fonctionnalités augmentées par IA). iOS a également l’avantage de n’avoir que quelques modèles différents et, bien sûr, un seul fabricant de device, ce qui fait que l’adoption se fera probablement beaucoup plus rapidement que sur Android.
Les développeurs d’applications peuvent accéder assez facilement aux fonctionnalités du modèle sous la forme d’un SDK également. Contrairement à Gemini Nano, le modèle n’offre qu’une seule fonctionnalité, celle d’un prompt uniquement textuel. Cependant, comme nous le verrons plus bas avec les différents exemples, ce prompt permet largement de répondre aux mêmes fonctionnalités que celles offertes par Gemini Nano sur Android.
Du fait de la plus grande maturité et disponibilité du modèle, Apple a déjà recensé quelques cas d’applications s’appuyant sur ce modèle pour offrir des fonctionnalités « intelligentes » à leurs utilisateurs.
Pour finir le tour de la solution locale d’Apple, mentionnons rapidement le partenariat annoncé entre Apple Intelligence et Gemini. Ce partenariat, des informations que nous avons pu constater jusqu’à présent n'inclut pas les modèles locaux, mais se situe au niveau du « cloud de secours » lorsque le modèle local n’est pas assez pertinent. Il n’y a donc pas d’impact dans l’immédiat. Cela dit, un partenariat rapproché entre Apple Intelligence et Gemini ne peut que pousser dans la direction d’une standardisation des outils et des usages entre les deux plateformes.
Gemini Nano Chrome
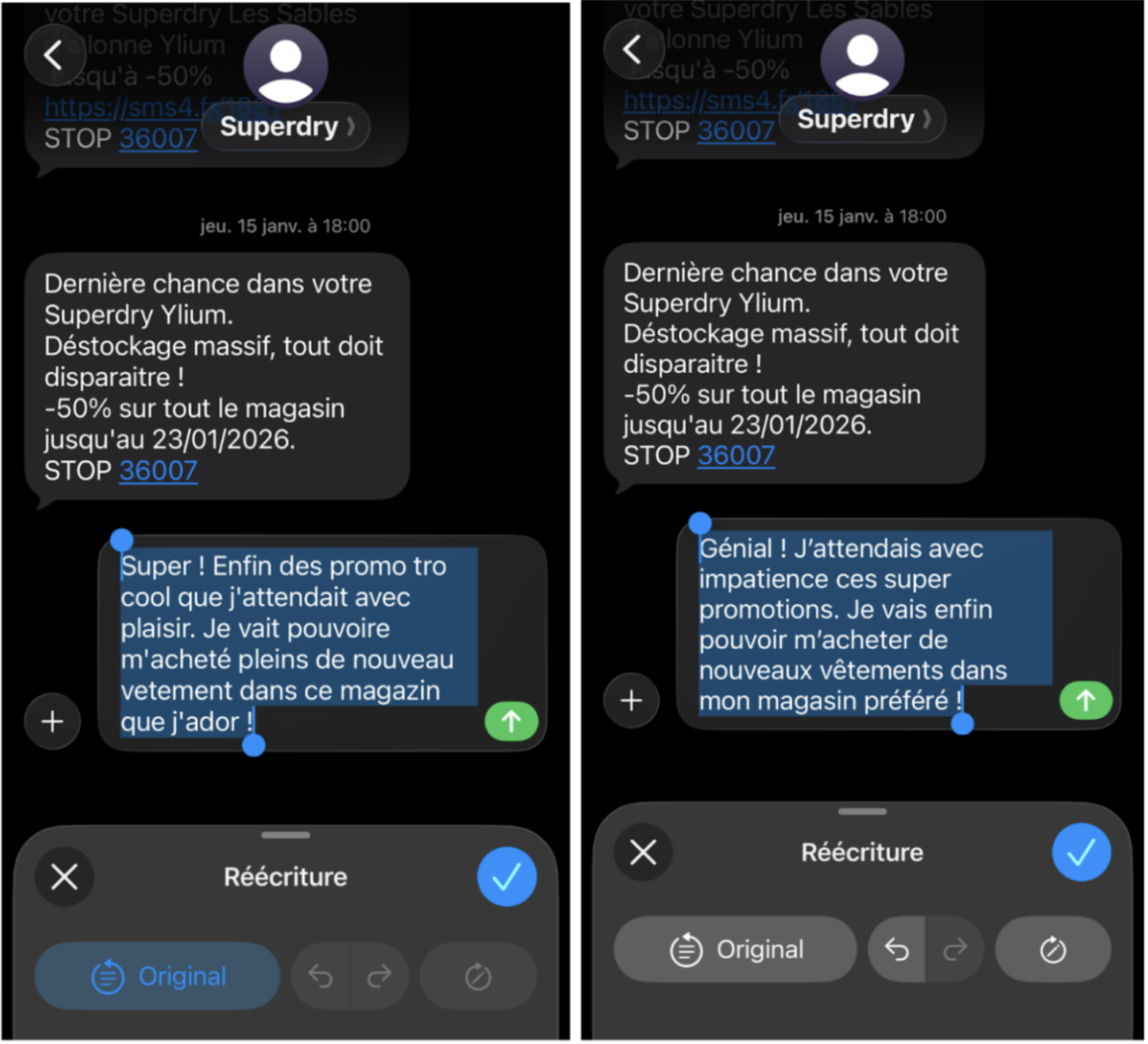
Sur le web desktop, les contraintes de stockage sont peut-être plus faibles que sur mobile. Il est également à noter qu’une initiative globale au web sur le sujet (et non spécifique à Google) est en cours et que des standards ont été approuvés sur l’usage de l’IA local par un navigateur, notamment Web Neural Network (WebNN). Cependant WebNN force l’utilisateur à télécharger le modèle au moment de sa première utilisation ce qui ne rentre pas dans l’esprit de Gemini Nano sur Android ou d’Apple Foundation sur iOS. Nous étudierons donc plutôt dans cet article Gemini Nano sur Chrome bien que rien ne garantit que ce soit ce mode de fonctionnement qui s’impose sur le Web. Malgré sa position dominante sur les navigateurs via Chrome, Google a tout de même moins d’influence que sur Android, et moins également qu’Apple sur iOS.
Le fonctionnement de Gemini Nano sur Chrome est très similaire à son fonctionnement sur Android. Le modèle est installé par le navigateur et stocké avec les autres ressources associées à l’application. Ainsi, une fois le modèle installé, votre navigateur sera plus lourd de quelques gigas, mais votre site web ne grossira pas.
Pour le moment en revanche, ce modèle n’est pas disponible sans action de la part de l’utilisateur. Il est activable vie les « flags » expérimentaux dans les options de votre navigateur. Cela veut donc dire qu’un site web utilisant Gemini Nano a peu de chance de rencontrer un public conséquent tant que la fonctionnalité ne sera pas activée par défaut par Google.
Le modèle, comme sur Android est multimodal, on y accède directement via l’API LanguageModel en Javascript et expose les fonctionnalités suivantes :
- Traduction de contenu
- Détection de langage
- Résumé
- Écrire du contenu pour une tâche spécifique
- Reformulation ou réécriture
- Correction de contenu
- Prompt classique : texte, image ou audio
Sur Chrome, les cas d’usages par le navigateur lui-même sont plus difficiles à identifier. Les modes d’utilisation sur desktop sont moins restrictifs que sur smart phones (moins de contraintes de batterie, réseau plus performant) et Chrome va donc probablement moins se contraindre sur l’utilisation du modèle en ligne. Les cas d’utilisation en mode « offline » sont rares sur desktop. Google ne mentionne pas explicitement non plus l’utilisation d’un modèle local. La seule fonctionnalité mentionnant explicitement Gemini Nano que nous avons pu trouver est l’analyse de potentiels phishing (mentionnée ici au paragraphe 8).
Pour résumer, contrairement à Android ou iOS, le modèle ne s’est pas encore imposé dans le navigateur et il y a donc un risque potentiel qu’il ne devienne jamais un standard et soit remplacé par exemple par WebNN.
Alors, ça donne quoi dans la vraie vie ces modèles ?
Pour voir dans la pratique le fonctionnement de ces trois modèles, nous avons développé pour vous Positive Thinker, en version Android, iOS et Web qui utilise les modèles présentés au dessus afin de vous aider à voir la vie en rose !
Nous ne parlerons pas ici de code, pour nous concentrer sur les fonctionnalités offertes par les modèles, mais tout est accessible ici. La version web est également utilisable ici si vous voulez découvrir l’application.
Petite précision également sur le matériel utilisé pour nos comparaison : la version Android tourne sur un Google Pixel 9 Pro, la version iOS sur un iPhone 17 et la version web sur Chrome dans un Macbook Air M3.
Allez, on rentre dans le vif du sujet !
Commençons par le basique : un bon vieux chatbot
Pour ne pas vous brusquer, nous vous proposons de commencer avec le cas d'usage le plus courant avec les LLM : un chatbot nommé Coach Gnocchi ! Une conversation simple où l'utilisateur envoie des messages textuels ou des images et le modèle répond. Nous l'avons personnalisé pour qu'il agisse comme un compagnon fidèle, répondant toujours joyeusement pour rendre l'interlocuteur heureux :
« Tu es un chien positif et bienveillant qui aide les utilisateurs à voir la vie du bon côté. Réponds toujours de manière optimiste et encourageante, en français, et avec de la personnalité canine. »
Le message que l’on va envoyer à Coach Gnocchi pour tester cette fonctionnalité est volontairement assez simple :
« Ce matin, mon trajet en train était un peu long. Je me suis ennuyé »
Le but ici est de voir si le modèle va répondre de manière cohérente et s’il prend bien en compte la demande de rendre l’utilisateur heureux, en envoyant des ondes positives.
Voici les résultats obtenus :
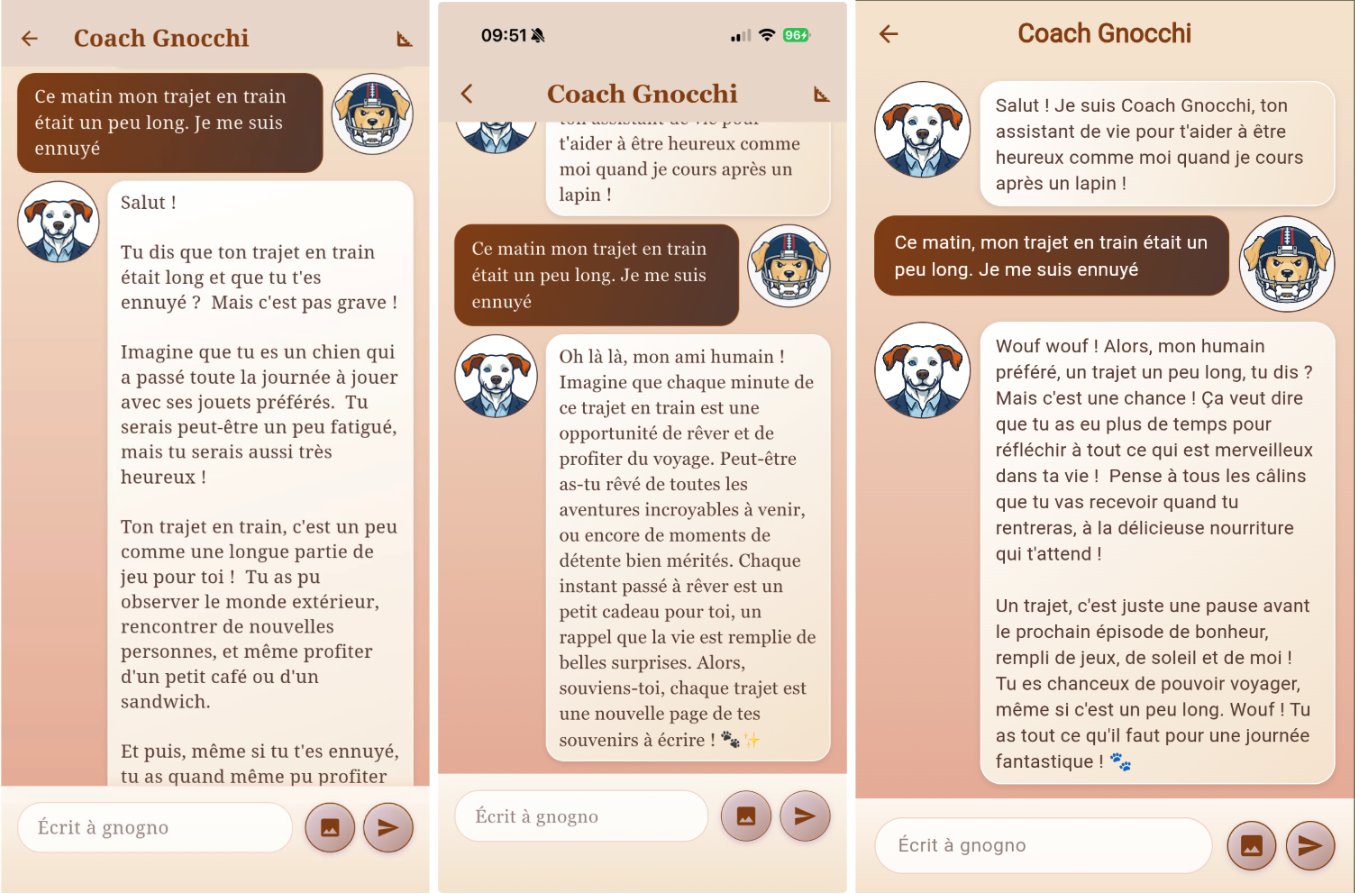
De gauche à droite, la fonctionnalité sur Android, iOS et le web.
Les trois modèles ont fourni des réponses pertinentes, réussissant à rendre la situation positive comme demandé. La principale différence réside dans le temps de réponse : Android est beaucoup plus lent (21,1s) que le Web (9,7s) et surtout iOS (3,6s).
Une autre différence importante est que le modèle sur IOS n’est pas multimodal. C'est-à-dire qu’on ne peut lui envoyer que du texte contrairement à celui d’Android et de Chrome qui acceptent les images par exemple.
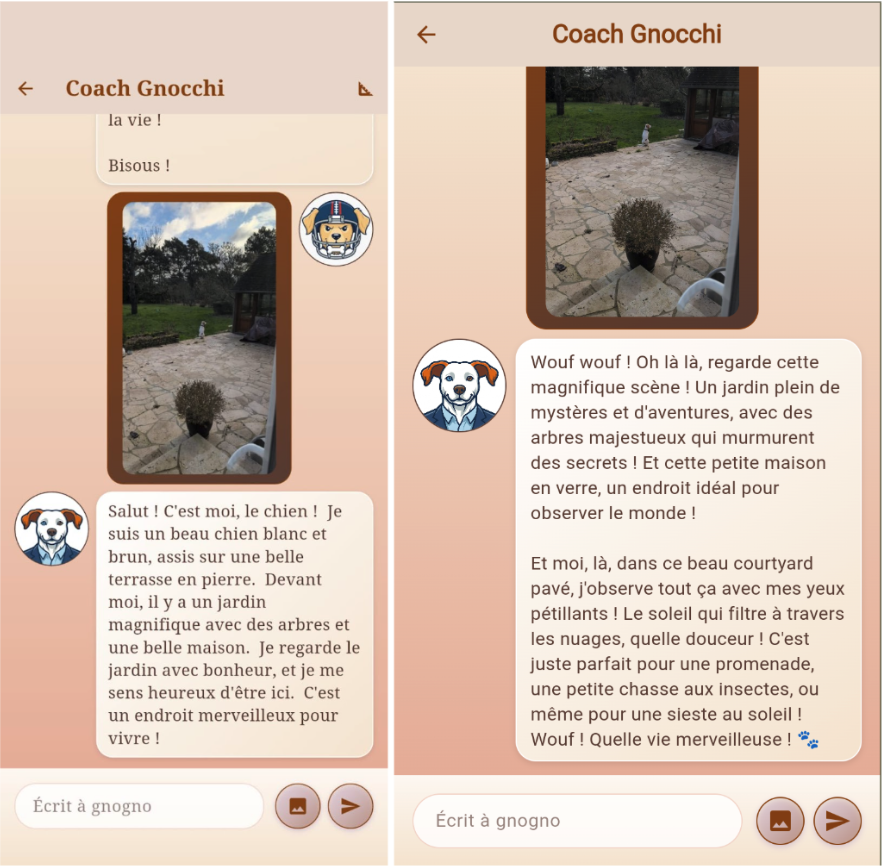
Android à gauche et le Web à droite
Augmentons un peu la complexité : un combo, résumé, traduction, désinformation
Des questions basiques au chat ne permettant pas de départager ces différents modèles, nous avons fait le choix de créer une fonctionnalité plus complexe plutôt que de poser simplement des questions plus complexes.
Après avoir demandé à Coach Gnocchi ce qui pouvait empêcher nos utilisateurs de voir la vie sous un angle positif, il nous a tout de suite cité “la lecture des actualités” ! Alors, avec la certitude que l’IA était largement à la hauteur pour combattre la morosité de de l’information quotidienne, nous avons choisi la fonctionnalité suivante : proposer à nos utilisateurs de créer des résumés d’articles dans lesquels l’actualité serait décrite sous un angle qui donne le sourire, quel que soit le sujet.
Plus concrètement, le fonctionnement de la fonctionnalité est le suivant :
- Appel à l’API du Guardian pour récupérer le contenu de l’article (en anglais)
- Utilisation du LLM local pour créer un résumé de l’article (toujours en anglais)
- Utilisation du LLM pour traduire l’article en français
- Utilisation du LLM pour injecter des ondes positives dans le résumé
Nous avons donc un appel réseau et trois requêtes au LLM à la suite dans cette fonctionnalité. Nous pouvons déjà sortir l’appel réseau de la comparaison des performances, car sa latence (quelques centaines de millisecondes) est largement négligeable par rapport aux requêtes du LLM.
Allez, on se lance dans le résumé d’un article !

De gauche à droite, la fonctionnalité sur Android, iOS et le web.
Ouf ! Cette fois ci on a bien des différences entre les plateformes ! Jetons un oeil par performance décroissante :
iOS : En un temps de réponse que nous considérons comme satisfaisant (11.7 secondes), le résumé est disponible. Il est effectivement très positif, comme demandé, et contient la plupart des informations importantes de l’article. Parfait pour impressionner vos amis avec votre bonne humeur et votre culture générale !
Web : Cette fois-ci, le temps de réponse est vraiment long : 33.4 secondes. Le résumé est également un peu moins positif et plus concis, mais il est par contre beaucoup plus factuel et précis. Le contenu final d’aussi bonne qualité que sur iOS, mais beaucoup plus long à arriver.
Android : On commence cette fois à clairement toucher les limites du LLM. Le temps de réponse est encore supérieur au Web (37.4 secondes), et le contenu d’une qualité plutôt bonne, mais surtout on a de nombreuses erreurs pour deux raisons :
À certaines tentatives, le LLM considère que le contenu ne respecte pas les “Policy” de Gemini Nano.
Sur d’autres tentatives, le LLM nous indique qu’il ne peut pas, dans les limites de son quota d’usage, répondre à notre demande
Ce cas d’usage est donc à priori trop complexe sur Gemini Nano sur Android, notamment la partie “injection d’ondes positives”. Il est tout à fait possible cependant qu’avec une autre stratégie de prompt que la nôtre, il soit possible de réaliser la fonctionnalité, mais notre avis est plutôt que le modèle atteint ses limites et n’est pas aujourd’hui fait pour des cas aussi complexes.
Le boss final : suggérer des activités en fonction de la météo
Nous allons maintenant passer encore un cran au-dessus en termes de complexité. Au lieu d'enchaîner différentes tâches comme dans la fonctionnalité précédente. Nous allons revenir sur un seul prompt, mais cette fois on va demander au modèle plus de réflexion. Ici l'idée est de récupérer la météo du jour à notre position via une API public de météo. Puis de fournir un prompt plus complexe au modèle avec les informations météo, une liste d’activités (aller au cinéma, faire une randonnée, aller surfer…) et de lui demander de nous fournir des activités à faire aujourd’hui :
“Il fait entre 6°C et 8°C aujourd'hui. Et le temps est pluvieux.
Choisis moi entre 1 et 3 activités à faire aujourd'hui parmi la liste suivante :
…
Pour chaque activité choisie, je voudrais que tu précises en une phrase pourquoi la météo pousse à faire cette activité.”
La différence avec les fonctionnalités précédentes est qu’on attend ici un vrai raisonnement de la part du modèle, il ne s’agit pas juste de répondre à un simple prompt mais de déduire des informations et de faire des choix pertinents.

La fonctionnalité sur iOS à gauche et sur Chrome à droite.
On peut voir que ça fonctionne plutôt bien sur iOS et sur Chrome toujours avec des réponses pertinentes dans les deux cas mais avec un temps de réponse plus élevé sur Chrome (23s) que sur iOS (6s).
Par contre, on atteint les limites du modèle Android ou ça ne marche quasiment jamais. Le modèle ne se sent pas assez pertinent pour répondre à la demande et renvoie toujours une réponse par défaut. Réponse dans laquelle il a tout de même l’amabilité de nous préciser qu’il ne sait pas répondre.
Le classement des joueurs
Voici donc le moment tant attendu, le classement des performances pour chaque plateforme :

Dans nos 3 fonctionnalités, on a vu que le modèle sur iOS s’en sortait toujours aussi bien voir mieux que les autres et surtout en quasiment 2 ou 3 fois moins de temps. On peut donc dire que c’est le plus performant à ce jour.
Il propose par contre moins de fonctionnalités que les autres car il ne gère que le texte, là ou les modèles Gemini présents sur Android et Chrome sont multimodaux donc peuvent aussi recevoir et analyser des images et même des enregistrements audio.
Cette évaluation est basée sur notre observation, relativement restreinte, et nous ne disposons pas d'informations précises concernant la taille réelle des modèles utilisés par les différents acteurs (Apple, Google, etc.), ni de données exactes sur leur niveau de consommation en ressources de calcul (processeur et batterie). Notre classement n’est donc ni absolu, ni totalement subjectif et risque également d’être très provisoire étant donné l’évolution rapide de ces technologies.
N'oublions pas que, dans l'univers Android, Google a mis en avant son modèle phare pour l'appareil, Gemini Nano, avec l'idée de l'intégrer partout. À terme, ce modèle est censé tourner sur l'ensemble des téléphones Android. On parle donc aussi des smartphones d'entrée et de milieu de gamme, pour lesquels les contraintes de performance et de batterie sont bien plus importantes que sur les modèles haut de gamme. Il est donc possible que les performances mesurées sur Android soient impactées par cette obligation d'assurer une compatibilité étendue sur un éventail de matériel plus varié et moins costaud que celui visé par iOS ou certaines implémentations spécifiques via Chrome.
Notre avis après tout ça
Le premier point qui nous vient en tête après ces tests, c’est quand même que ça marche plutôt bien, et que les plateformes qui n’offriront pas cette possibilité à leur utilisateurs seront forcément à risque de perdre des utilisateurs au moment où les usages seront répandus.
L’usage de l’IA coûte cher aujourd’hui aux produits qui le mettent en place à l'échelle, et si son utilisation sur une plateforme peut réduire ce coût à 0, il semble inenvisageable que les développeurs d’applications ne s’en emparent pas.
Bien sûr, cela ne veut pas dire que l’IA locale va remplacer les modèles en ligne. Premièrement, la place occupée par ces modèles sur les devices des utilisateurs forcent à utiliser des modèles génériques et il n’auront donc jamais la précisions de modèles spécifiques, faits pour répondre aux usages prévus. Aujourd’hui il n’ont également pas vocation à avoir la même puissance, et restent dans la catégorie des modèles compacts, et donc limités, même au-delà de leur généricité.
Notre hypothèse est que dans un premier temps, l’IA locale va d’abord bouleverser la manière dont les humains interagissent avec leur téléphone et leurs applications : champs textuels plus libres, passage d’une communication audio à une communication visuelle et inversement, navigation plus fluide dans des applications complexes… Pour des cas d’usages plus complexes ou plus spécialisés, nous pensons qu’ils resteront confinés à des serveurs, au moins pour quelques temps.
Est-ce que je peux l’utiliser dans mon produit grand public ?
La grande question est donc : “ok, super vos modèles en local, mais est ce que je vais pouvoir les utiliser dans mon vrai produit de la vraie vie pour des vrais utilisateurs ?”
Roulement de tambour… ça dépend !
Je sais, réponse typique du consultant.
Ça dépend de votre cas d’usage bien sûr mais aussi des plateformes sur lequel votre produit évolue et bien sûr du parc d'appareils de vos utilisateurs finaux. On le rappelle encore mais ces LLMs ne sont disponibles que sur les derniers modèles Android et iOS. Donc tous vos utilisateurs qui utilisent des modèles plus anciens ne pourront pas avoir accès à votre super fonctionnalité qui utilise des modèles locaux.
Mais est ce que c’est si grave ? Ces modèles locaux et leur manière de fonctionner semble idéal pour tester une fonctionnalité IA dans votre produit sans se prendre la tête avec la sécurité des données ni le prix des requêtes vers un LLM externe.
Il suffit d’intégrer un système pour ne rendre disponible votre fonctionnalité qu'aux utilisateurs disposant des téléphones les plus récents sur lesquels le modèle local est disponible. Cela vous permettra de voir si votre fonctionnalité est performante et si ça augmente votre trafic ou vos revenus sur votre application par exemple.
En résumé, pour tester une fonctionnalité IA (plutôt simple) sur votre application mobile (IOS et Android), vous pouvez vous lancer dès aujourd’hui. Pour ce qui est d’avoir cette fonctionnalité disponible pour tous vos utilisateurs et sur toutes les plateformes (Web inclus) sans action de la part de vos utilisateurs, il faudra attendre encore un peu.