Kubernetes : arrêter ses environnements de développement pour réduire les coûts
Disclaimer
L’article qui suit fait appel à des concepts relativement avancés sur le fonctionnement de Kubernetes. Une connaissance raisonnable de l’outil est nécessaire afin de bien appréhender les concepts abordés.
Introduction
Dans un environnement cloud, la gestion efficace des ressources est essentielle pour réduire les coûts et optimiser l'utilisation des infrastructures. Une technique possible est de faire en sorte d’arrêter les environnements lorsqu’ils ne sont pas utiles.
Cet article présente une approche basée sur la segmentation des workloads dans Kubernetes afin d’éteindre les environnements de développement la nuit. Un second article sera consacré à la mise en place d’environnements éphémères et aux techniques à utiliser pour réduire au maximum les impacts associés.
Pour la suite, ces articles feront appel au fournisseur de cloud OVH ainsi qu’au mécanisme de gestion d’arrêt d’environnement Kube Green. Ces exemples sont bien sûr transposables à n’importe quel fournisseur cloud.
Pour les personnes qui ne connaîtraient pas Kube Green, sachez simplement qu’il s’agit d’un opérateur qui prend en charge l’arrêt automatique d’applications (en s’appuyant notamment sur les objets de type Deployment ou StatefulSet).
L’outil est encore relativement jeune (version 0.7.0 au moment de la rédaction de cet article) mais il est de mon point de vue tout à fait fonctionnel pour une utilisation simple. La gestion de l’heure des arrêts/relances se fait à l’aide d’objets SleepInfo. On y définit également les plages de jours de démarrage ainsi que les pods à arrêter.
Pour résumer, nous allons suivre les étapes suivantes :
- Préparer l’environnement de production
- Créer le groupe de nœud de dev
- Déployer l’environnement de développement
- Enfin, mettre en place le mécanisme d’arrêt automatique
Préparation du contexte de travail
Afin de valider le fonctionnement du mécanisme d’arrêt et de démarrage, une application de test va être déployée sous la forme d’un conteneur Nginx dans l’espace de nom prod.
Un autre conteneur identique sera lancé pour le dev un peu plus tard afin de déclencher le démarrage des machines spécifiques aux environnements de développement.
La séparation de ces environnements se fera à l’aide de deux espaces de nom prod et dev.
Ci-dessous les instructions kubectl permettant la création de ces deux éléments :
$ kubectl create namespace prod
$ kubectl create namespace dev
Ci-dessous le contenu de l’objet de déploiement utilisé pour nos tests :
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: appli
name: appli
spec:
replicas: 1
selector:
matchLabels:
app: appli
template:
metadata:
labels:
app: appli
spec:
containers:
- image: docker.io/library/nginx:1.27
name: nginx
Sauvegardez cette définition sous le nom de fichier deployment.yaml puis appliquez-le dans l’espace de nom prod :
$ kubectl -n prod apply -f deployment.yaml
Définition de groupes de machines
Une des premières étapes va être de définir les types d’environnement à démarrer dans le cluster. Pour l’essentiel, il s’agit de gérer les deux cas suivants :
- L’hébergement de l’environnement de production sur les nœuds du groupe de machines par défaut
- L’hébergement de l’environnement de développement sur un groupe de machine dédié au développement
Ci-dessous un petit schéma récapitulatif de la situation que l’on souhaiterait obtenir :
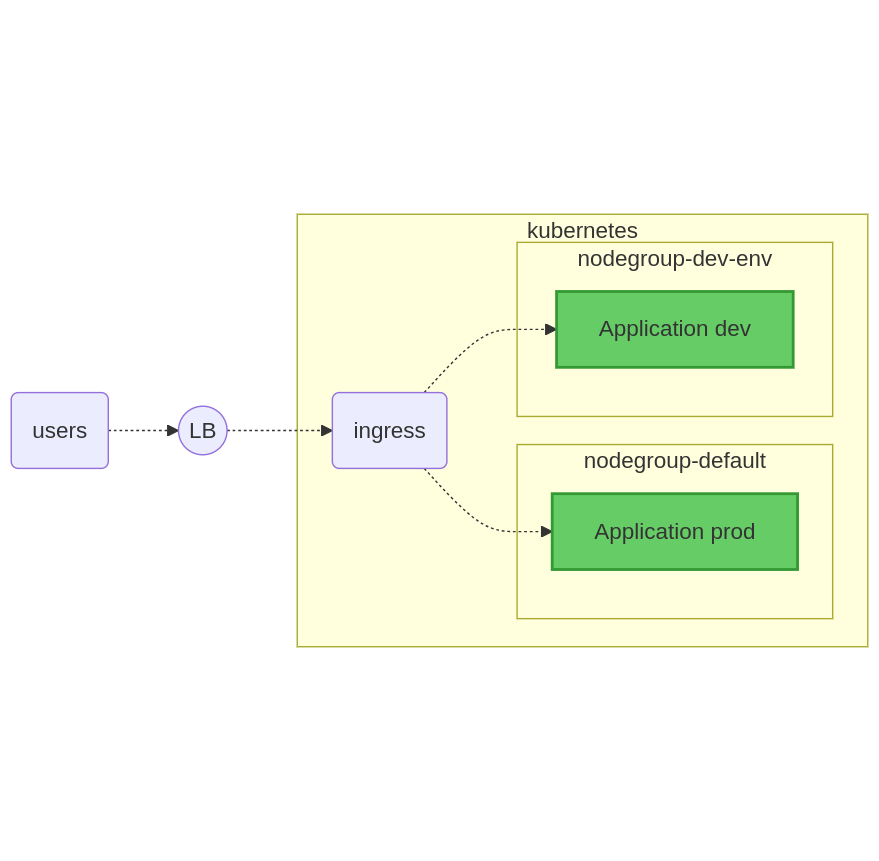
À noter que les nœuds par défaut hébergent des éléments communs aux différents environnements : contrôleur Ingress, pilotes réseaux, DNS, etc.
En plus de ces composants, ces machines par défaut accueillent également les pods de la production.
Kubernetes permet de forcer ou restreindre l’utilisation de nœuds dans un cluster à l’aide des concepts suivants :
- Des sélecteurs afin de spécifier un type de nœud
- Des teintures (taints) afin de marquer qu’un nœud ne peut pas être utilisé pour n’importe quel besoin
- Des tolérances de teintures (tolerations) afin d’indiquer à une application qu’elle peut tolérer d’être lancé sur certaines machines même lorsqu’il y a présence d’un marquage
Dans le cas d’OVH, la définition d’un groupe de machine se fait à l’aide d’un objet NodePool. Outre les valeurs classiques dans le champ metadata, cet objet a besoin des définitions suivantes :
- Le champ flavor suivi du type de machines à utiliser (ex : d2-8)
- Le champ minNodes, maxNodes et desiredNodes
- Le champ monthlyBilled à la valeur false (attention sinon ça compte sur un mois !)
- Le champ template avec les caractéristiques des machines à créer
Dans Kubernetes, lorsqu’on souhaite exclure le lancement d’applications sur un groupe de machines, il est nécessaire de faire appel à des “taints”. Elles peuvent prendre les valeurs suivantes : NoExecute, NoSchedule et PreferNoSchedule.
Ce mécanisme est utilisé notamment pour interdire le lancement d’applications standards sur les nœuds de la partie Control Plane. Ici, nous allons utiliser ce mécanisme afin d’exclure l’utilisation des machines de développement sauf pour les environnements de développement qui vont tolérer cette teinture.
Ci-dessous un exemple de définition pour un groupe de machine de dev portant le label env=dev ainsi que la teinte **env=dev:**NoSchedule :
apiVersion: kube.cloud.ovh.com/v1alpha1
kind: NodePool
metadata:
name: nodepool-env-dev
spec:
antiAffinity: false
autoscale: true
autoscaling:
scaleDownUnneededTimeSeconds: 600
scaleDownUnreadyTimeSeconds: 1200
scaleDownUtilizationThreshold: '0.5'
desiredNodes: 0
flavor: d2-8
maxNodes: 5
minNodes: 0
monthlyBilled: false
template:
metadata:
annotations: {}
finalizers: []
labels:
env: dev
spec:
taints:
- effect: NoSchedule
key: env
value: dev
unschedulable: false
Sauvegardez cette définition sous le nom de fichier nodepool-dev-env.yaml et appliquez-le auprès du cluster :
$ kubectl apply -f nodepool-dev-env.yaml
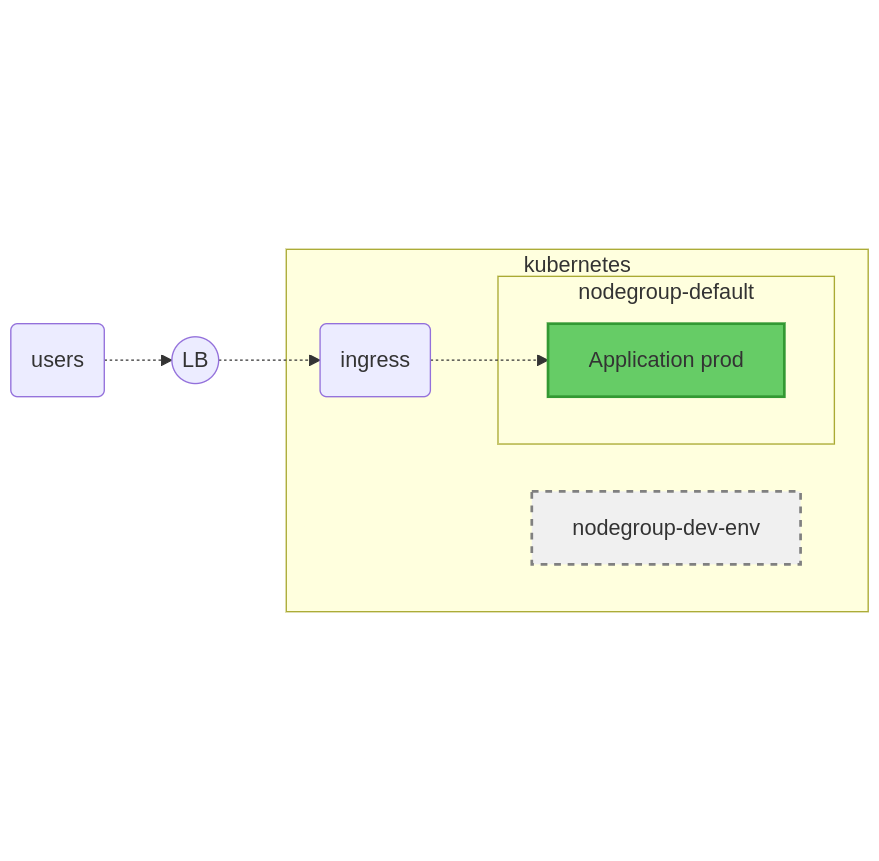
Le groupe de nœud de dev est défini. Toutefois, aucun nœud n’est créé pour les deux raisons suivantes :
- Aucun pod applicatif ne leur est associé
- Le nombre de nœuds désiré dans le groupe de nœud (champ desiredNodes) est à 0
In fine, le cluster ne procède donc à aucun changement.
Ci-dessous un schéma résumant la situation suite à l’ajout de ce groupe de machine :
Préparation de l’environnement de développement
Par défaut, un pod dans un cluster Kubernetes est démarré là où le système lui trouve de la place. Ainsi, si rien n’est fait, les pods de développement seront lancés sur les nœuds de prod existants.
Afin d’éviter cette situation, il est possible de spécifier au système où nous souhaitons démarrer une application. On peut avoir d’autres raisons de contrôler cet aspect comme par exemple utiliser une machine avec un GPU ou tout simplement pour éviter de mélanger le type de traitement sur une même machine. Il est en effet rarement souhaitable de faire cohabiter des traitements batchs (qui tolèrent très bien une augmentation de la CPU pendant plusieurs minutes) avec une application web pour laquelle le manque de réactivité se traduit par une dégradation de l’expérience utilisateur.
Comme vu précédemment, la configuration de ce comportement se fait à l’aide des sélecteurs de nœuds ainsi que les tolérances. Au niveau des pods, ces aspects se configurent à l’aide des deux champs suivants :
- Le champ pod → spec → nodeSelector : sélecteur de noeuds
- Le champ pod → spec → tolerations : définir les tolérances de teintures (taints)
Remarque : Il existe également la notion d’affinité et/ou anti-affinité (champ pod → spec → affinity) mais cet aspect ne sera abordé dans cet article.
Afin d’implémenter cette séparation des types d’environnements, nous allons utiliser les définitions suivantes :
- Dans un premier temps, définir une tolérance sur les teintes des noeuds qui nous intéressent
- Enfin, pour forcer la main au système, un sélecteur sur les nœuds qu’il faut absolument utiliser.
Ci-dessous les définitions permettant de déployer les pods sur ces nœuds de développement :
nodeSelector:
env: dev
tolerations:
- key: env
value: dev
effect: NoSchedule
Ainsi, si l'environnement de développement n'est pas activé, aucun nœud correspondant n'est provisionné.
Afin de spécifier où déployer les applications, l’objet de déploiement de tout à l’heure va être modifié afin d’y injecter le champ nodeSelector ainsi que le champ tolerations.
Ci-dessous cette déclaration suite à ce changement :
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: appli
name: appli
spec:
replicas: 1
selector:
matchLabels:
app: appli
template:
metadata:
labels:
app: appli
spec:
containers:
- image: docker.io/library/nginx:1.27
name: nginx
nodeSelector:
env: dev
tolerations:
- effect: NoSchedule
key: env
value: dev
Sauvegardez cette déclaration sous le nom de fichier dev-deployment.yaml puis appliquez-le auprès de l’API du cluster Kubernetes :
$ kubectl apply -n dev -f dev-deployment.yaml
Scrutez ensuite l’état des pods dans l’espace de nom dev :
$ kubectl -n dev get pods
Dans un premier temps, le système renvoie que le pod n’arrive pas à démarrer : il est à l’état Pending :
NAME READY STATUS RESTARTS AGE
appli-785bc5d554-5kzqh 0/1 Pending 0 7s
Au bout de quelques minutes, le système crée un nouveau nœud. Le pod est ensuite rattaché à cette nouvelle machine et peut ainsi démarrer le pod de l’environnement.
Ici, l’état du pod une fois que le nœud a démarré correctement :
NAME READY STATUS RESTARTS AGE
appli-785bc5d554-5kzqh 1/1 Running 0 5m
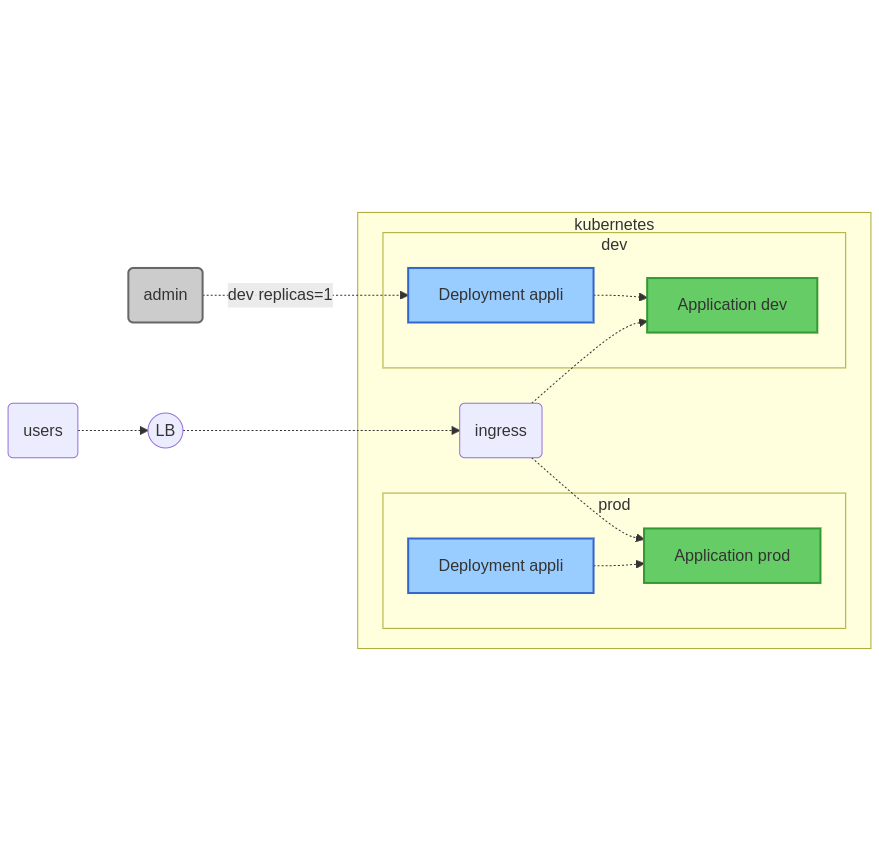
Le schéma de principe suivant permet d’illustrer l’état du cluster suite au démarrage de du pod associé à l’environnement :
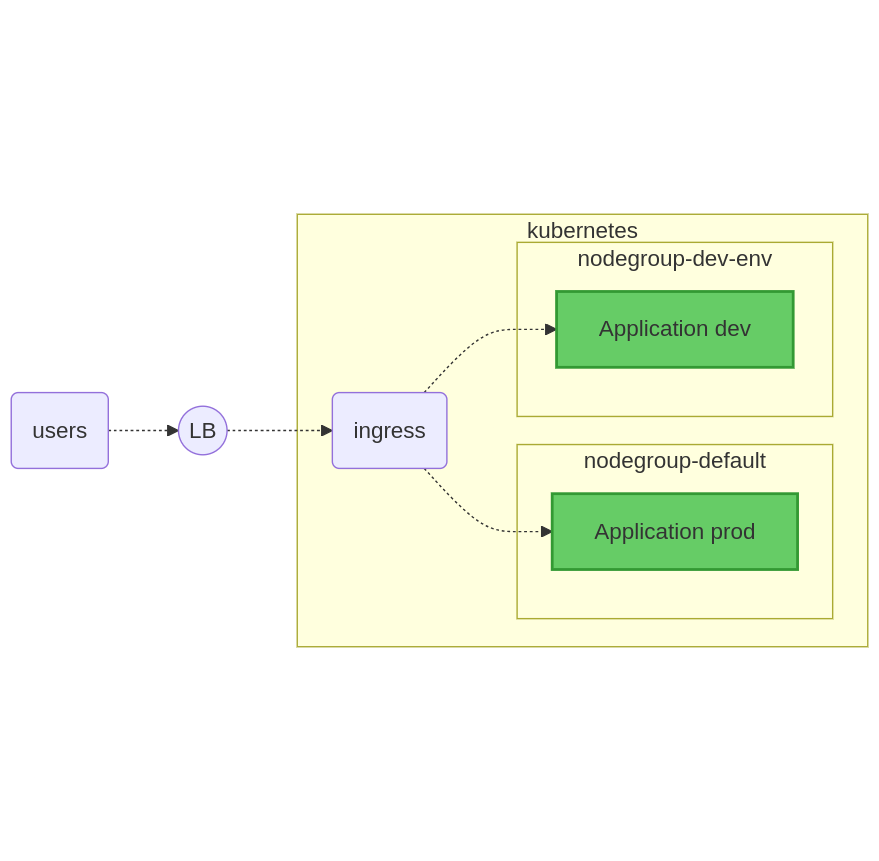
Note : Ici, la plateforme de développement utilise le contrôleur Ingress de la partie production. Il est bien sûr tout à fait possible d’en dédier un en fonction du type d’application. Pour la suite - et afin de simplifier les choses au maximum - cet élément sera mis en commun.
Arrêter les environnements de développement
Pourquoi vouloir arrêter un environnement ?
Le nœud associé au développement est démarré et si rien n’est fait, la machine reste démarrée tout le temps même quand personne n’utilise l’environnement associé.
Pour la suite, un mécanisme d’arrêt va être implémenté. Cette pratique a plusieurs avantages :
- Vérifier régulièrement les mécanismes d’arrêts et de démarrage
- Réduire les coûts d’hébergement
- Encourager une approche plus responsable des équipes de développement afin de favoriser une véritable coupure numérique
Comment arrêter une application dans Kubernetes
Dans Kubernetes, l’arrêt de ressources applicatives passe par un changement du nombre de réplicas sur les objets en charge des déploiements (objets Deployment et StatefulSet). Les objets CronJobs sont également susceptibles de lancer des pods de traitement. La désactivation d’un de ces éléments passe par la modification du champ spec → suspend de l’objet.
Ci-dessous un exemple d’arrêt manuel sur un objet Deployment nommé appli dans l’espace de nom dev :
$ kubectl -n dev scale deployment appli --replicas=0
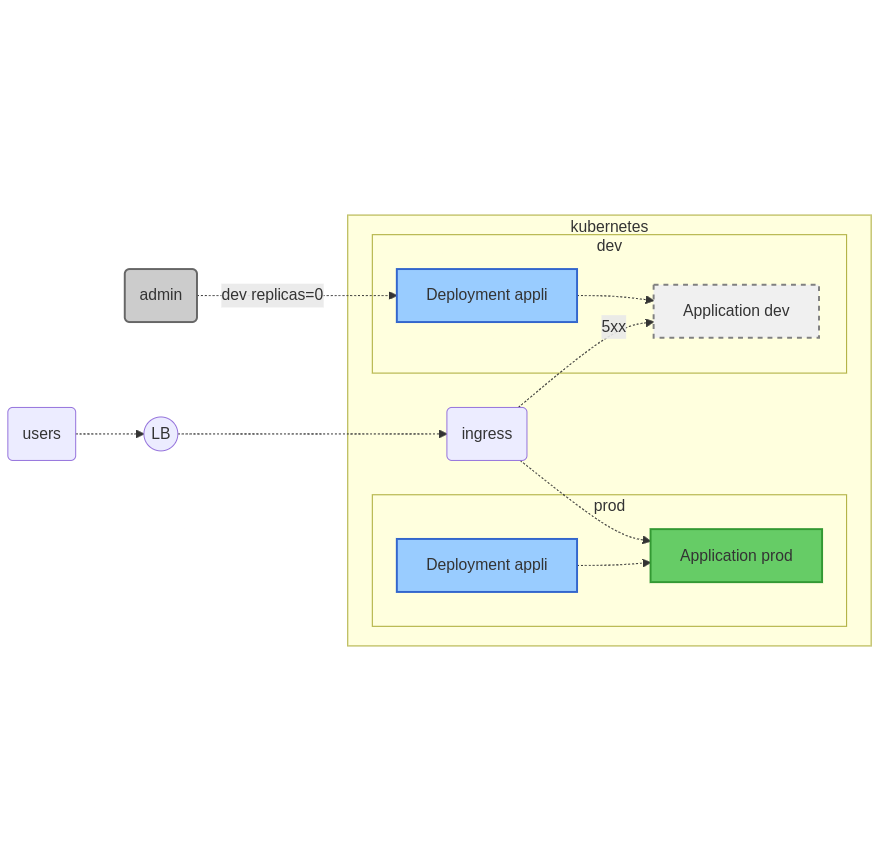
Note : lorsque l’utilisateur se connecte sur l’environnement arrêté, le contrôleur Ingress renvoie une erreur 500.
Une fois l’instruction lancée, le système se charge ensuite de supprimer le pod associé à l’application. Lorsqu’il n’y a plus de pods applicatifs sur un nœud, le scheduler Kubernetes se charge de supprimer les machines devenues inutiles.
Dernière étape, le démarrage de l’application. Cette fois-ci, il s’agit de la même commande lancée mais avec un nombre de réplicas supérieur à 0.
Ci-dessous une instruction permettant de démarrer à nouveau l’application :
$ kubectl -n dev scale deployment appli --replicas=1
On a donc une solution permettant d’implémenter l’arrêt de ces machines. Dans Kubernetes, il serait possible d’injecter ces opérations dans un objet CronJobs.
Il s’agit toutefois d’une solution relativement complexe à mettre en place qui réclame la définition de nombreux éléments :
- Un compte de service (ServiceAccount)
- Un rôle (Role) ainsi qu’un rattachement (RoleBinding) afin d’affecter ce rôle au compte de service
- Un script contenant les instructions d’arrêt/relance : kubectl scale deployment …
- Les CronJobs en chargent de ces opérations d’arrêt et de démarrage
Comme on peut le voir, ce mécanisme n’est pas forcément simple à mettre en place. C’est là où entre en scène Kube Green qui va se charger pour nous d’implémenter ces différents aspects à l’aide d’une simple déclaration dans l’espace de nom à piloter.
Mise en place de Cert Manager (prérequis de Kube Green)
Kube Green est disponible sous forme de chart Helm. Toutefois, son fonctionnement réclame le gestionnaire de certificats Cert Manager. Ce dernier s’installe également avec un chart Helm.
Ci-dessous l’instruction permettant d’installer le gestionnaire de certificats :
$ helm upgrade --install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.17.0 \
--set crds.enabled=true
Suite à ce déploiement, le cluster Kubernetes peut gérer de nouveaux types d’objets : les certificats (avec le type Certificate) ainsi que les gestionnaires de certificats (Issuer et ClusterIssuer).
N’hésitez pas à vérifier le contenu de l’espace de nom associé ad-hoc afin de vérifier l’état de l’opérateur :
$ kubectl -n cert-manager get pods
Ci-dessous le résultat attendu lorsque le gestionnaire de certificats est démarré :
NAME READY STATUS RESTARTS AGE
cert-manager-665948465f-rvmb9 1/1 Running 0 17m
cert-manager-cainjector-7c8f7984fb-cbmkz 1/1 Running 0 17m
cert-manager-webhook-7594bcdb99-txn4n 1/1 Running 0 17m
Mise en place de Kube Green
Le gestionnaire de certificat est en place. Il va permettre la génération des certificats nécessaires au fonctionnement de Kube Green.
Procédez maintenant à l’installation de l’opérateur :
Helm upgrade --install kube-green kube-green/kube-green \
--namespace kube-green \
--create-namespace \
--version v0.7.0
N’hésitez pas à vérifier également le contenu de l’espace de nom kube-green avec l’instruction suivante :
$ kubectl -n kube-green get pods
Ci-dessous le résultat attendu si tout est correctement démarré :
NAME READY STATUS RESTARTS AGE
kube-green-controller-manager-5f8894c864-p77kq 1/1 Running 0 6m30s
Tout est en place. Reste à définir les règles d’arrêt et démarrage.
Planifier l’arrêt des applications
Kube Green est en place. Il est maintenant temps de mettre en place l’arrêt automatique à l’aide de la déclaration d’un objet SleepInfo.
Au niveau de la structure de cet élément, l’essentiel se passe dans le champ spec et des valeurs suivantes :
- Champ weekdays afin de définir les jours de la semaine pour lesquels on souhaite démarrer l’application
- Champ sleepAt pour indiquer l’heure d’arrêt du système (ex : 19:30)
- Champ wakeUpAt pour indiquer l’heure de démarrage (ex : 8:00)
- Enfin le champ timeZone pour indiquer le fuseau horaire (ex : Europe/Paris)
Ci-dessous la déclaration correspondant à un arrêt des applications en dehors des heures de travail (working-hours) :
apiVersion: kube-green.com/v1alpha1
kind: SleepInfo
metadata:
name: working-hours
spec:
weekdays: "1-5"
sleepAt: "19:30"
wakeUpAt: "08:00"
timeZone: "Europe/Paris"
Sauvegardez la définition sous le nom sleepinfo.yaml puis appliquez le fichier dans l’espace de nom dev :
$ kubectl -n dev apply -f sleepinfo.yaml
Dorénavant, tous les jours du lundi au vendredi à 19h30, le système se charge automatiquement d’arrêter les déploiements de l’espace de nom de dev.
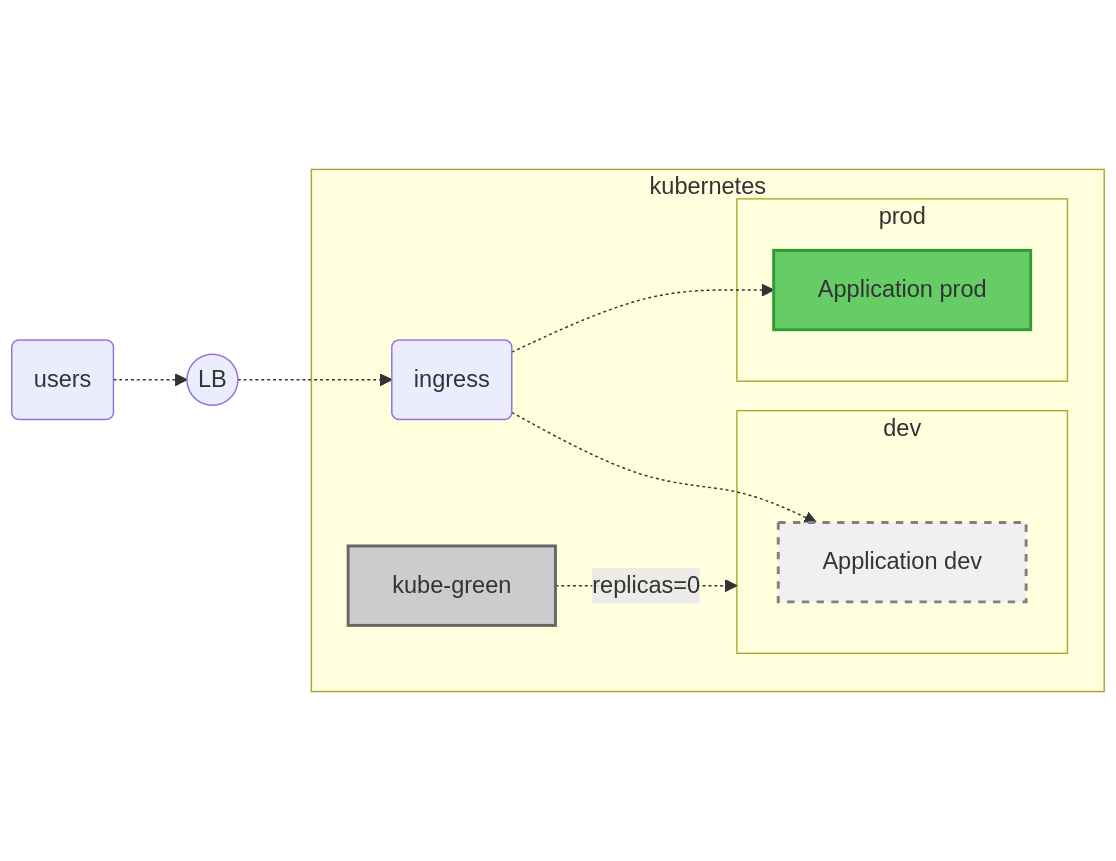
N’hésitez pas à consulter le journal d’activité du pod de l’opérateur Kube Green.
Quelques chiffres
La mise en place de ce mécanisme d’arrêt est un moyen très simple pour réduire votre facture cloud du fait de l’arrêt des machines virtuelles du cluster Kube.
Pour se faire une idée, sur une semaine (soit 7 x 24h = 168h), cet impact est le suivant :
- Arrêt de 48h durant le week-end
- Arrêt de 12h30 (entre 19h30 et 8h) chaque jour
Au total, le temps d’arrêt est donc de 110h et 30 minutes à comparer au 168h que constitue une semaine entière. Il s’agit d’une réduction de l’ordre de ⅔ du temps.
Concernant l’impact énergétique, la question peut se poser sur l’intérêt réel d’arrêter ses machines. En effet, à partir de combien de temps la consommation cumulée de l’arrêt et du démarrage d’une machine est compensée par son arrêt ?
La littérature sur le sujet n’est pas pléthorique. Cet article de eco-info essaye d’y répondre en étudiant la consommation de serveurs physiques lors des cycles d’arrêts et démarrages. Même si le mode de calcul n’est pas entièrement transposable ici, l’article indique qu’il faut environ 6 minutes d’arrêt pour compenser la consommation liée au démarrage et arrêt de la machine.
Le temps d’arrêt présenté ici est largement au-dessus de cette valeur (on parle de 12h d’arrêt). Il est donc imaginable qu’il y ait un impact environnemental.
Sur l’aspect financier, l’impact sur la facture dépend des conditions de souscription au cloud provider. Si les machines ne sont associées à aucune négociation contractuelle avec des machines pré-payées au mois, l’impact est évident. Dans le cas contraire, tentez malgré tout de faire ce travail d’arrêt/relance : la consommation d’énergie sera réduite, le démarrage de l’application sera testé régulièrement et la consommation de ressources pourra être affectée à d’autres priorités durant la nuit (traitement de batchs, sauvegardes, etc.).
Attention également au fait que toutes les machines ne sont pas concernées par cet arrêt. Ainsi les machines de production ne seront pas arrêtées. Dans le cas de l’utilisation de deux machines de production et deux machines pour la partie de développement, l’impact restera tout de même d’environ ⅓, ce qui reste toujours appréciable. Il est également possible d’imaginer prendre des machines avec un niveau de service moins exigeant toujours en vue d’optimiser la facture.
Conclusion
L'optimisation des ressources cloud est un enjeu majeur pour réduire les coûts et améliorer l'empreinte carbone des applications. Grâce à la segmentation des workloads et à l'utilisation de Kube Green, il devient possible d'automatiser l'arrêt des environnements de développement en dehors des heures de travail sans complexifier la gestion des clusters Kubernetes.
Cette approche apporte plusieurs bénéfices : elle garantit un usage plus efficient des ressources, réduit les dépenses liées à l'hébergement et favorise une culture de responsabilité numérique au sein des équipes de développement.
Autre gain au passage : cet arrêt/relance quotidien aura pour conséquence de vérifier régulièrement le comportement des applications en cas de démarrage (ce qui est d’habitude un événement rare).
Tout manquement ou bug possible lors de la phase de lancement se verra forcément à un moment ou à un autre et forcera les gens à prendre en compte ces aspects afin de s’assurer que l’application est correctement démarré le matin :
- Ordonnancement des démarrages
- Gestion des dépendances entre modules (le cas échéant)
- Monitoring des applications
Dans un prochain article, nous explorerons la mise en place d'environnements éphémères pour aller encore plus loin dans cette démarche d'optimisation et de rationalisation des infrastructures cloud.
Références :
- Kube Green : https://kube-green.dev/
- Kube Taints and Tolerations : https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/
- Kubernetes OVH : https://www.ovhcloud.com/fr/public-cloud/kubernetes/
- Étude de cas "Serveurs de calcul et consommation d’énergie" : https://www.eco-info.org/spip_article132.html