Moderniser un legacy conséquent sans y perdre ses plumes - Partie II
Moderniser un legacy conséquent sans y perdre ses plumes - Partie II
HELP! My system is a spaghetti code mess. - CodeOpinion
Si vous avez manqué la première partie : Moderniser un legacy conséquent sans y perdre ses plumes - Partie I - OCTO Talks !
Dans cette partie, nous aborderons les thématiques suivantes
- L’EventStorming Software Design permet d’exprimer le fonctionnement réel du système grâce à une sémantique métier riche, à condition de préparer les équipes à sa grammaire visuelle
- En rendant explicites règles, flux et responsabilités, ces ateliers réduisent l’ambiguïté fonctionnelle et sécurisent l’intervention sur le legacy
- Le Bounded Context Canvas formalise les frontières, le langage et les interactions du contexte
- Avant toute évolution, des harnais de tests sont indispensables ; les techniques de cassage de dépendances
- Le découpage du code et des données doit rester aligné avec les frontières métier pour préserver l’autonomie des équipes et limiter les couplages
- Le refactoring progressif, guidé par le vocabulaire métier, fait émerger une architecture plus lisible, souvent hexagonale
- Le langage ubiquitaire s’ancre dans le code, qui devient un support de dialogue métier
- L’IA générative peut accélérer la modernisation, mais reste un outil d’assistance
- Afin de cristalliser les éléments clés issus de ces échanges, nous avons introduit le Bounded Context Canvas
- La modernisation du code repose également sur des techniques permettant de casser les dépendances sans casser le code
- Toutefois, l’action à plus forte valeur ajoutée réside dans le remaniement du code lui-même. Il s’agit de « muscler le code » en y injectant le vocabulaire du métier
- Enfin, pour garantir une autonomie durable de l’architecture, l’adoption du pattern Ports and Adapters**, également connu sous le nom d’architecture hexagonale**
Un système ne devient pas legacy avec le temps, mais le jour où l’on cesse de le comprendre et de le faire évoluer*. La dette technique s’accumule, la connaissance se dilue, l’organisation se rigidifie — et l’architecture finit par se figer. Les réécritures « from scratch » promettent alors un nouveau départ, mais échouent le plus souvent en ne traitant que les symptômes, en oubliant les* causes humaines et organisationnelles mises en lumière par la loi de Conway.
Une modernisation durable ne commence donc pas par le code, mais par l’alignement entre organisation, compréhension du métier et architecture, porté par des pratiques collaboratives et des équipes autonomes orientées valeur. Une fois ce socle posé, reste l’étape décisive : faire entrer la modernisation dans le code lui-même*. C’est précisément l’objet de cette partie.*
Mettre en œuvre une modernisation du code portée par chaque équipe
La modernisation technique doit être menée de manière progressive et sécurisée, en restant alignée avec la capacité réelle des équipes. L’EventStorming Big Picture constitue un outil clé pour découper un domaine métier de façon collaborative et répartir les responsabilités entre les différentes équipes.
Une fois ce découpage établi, la compréhension précise du périmètre d’intervention d’une équipe reste toutefois souvent floue. L’enjeu consiste alors à clarifier ce que l’application, ou le service métier, est réellement censé faire. Cette étape peut sembler contre-intuitive face à un code legacy désorganisé, où la tentation d’agir immédiatement est forte.
Elle est pourtant essentielle. En définissant un cap clair et partagé, elle permet aux équipes qui interviendront sur le code pendant plusieurs semaines de réduire la charge cognitive liée à l’incertitude et à l’improvisation, et de travailler dans un cadre plus serein et maîtrisé.
Nous aborderons la problématique de la modernisation à l’échelle d’une équipe de développement. Nous considérerons le découpage par équipes comme acquis et nous concentrerons principalement sur les enjeux liés au code et aux pratiques techniques de modernisation mises en œuvre au sein d’une équipe.
Clarifier le problème métier de l’équipe
L’objectif est de contextualiser le problème métier de l’équipe afin d’exprimer, en termes fonctionnels, la manière dont le service ou l’application est censé se comporter. Dans ce cadre, l’atelier EventStorming Software Design est particulièrement adapté.
Contrairement à l’EventStorming Big Picture, cet atelier s’appuie sur une sémantique métier riche. Il permet de comprendre le fonctionnement réel du produit et d’en produire une description précise, partagée et directement exploitable par l’équipe de développement.
Avec l’atelier Event Storming Big Picture, les participants peuvent prendre part à l’atelier sans connaissance préalable du déroulé de l’Event Storming, il est recommandé, dans le cadre d’un EventStorming Software Design, d’acculturer les membres de l’équipe à la signification des couleurs et les comportement de chacun.
Cette préparation permet de tirer pleinement parti de la puissance et de la finesse de l’atelier. Il peut être pertinent d’organiser un premier atelier sur un sujet volontairement fictif, afin de permettre à chacun de se familiariser avec le fonctionnement des post-it et la grammaire visuelle.
Il est d’ailleurs devenu assez courant de s’appuyer sur une histoire largement partagée dans l’imaginaire collectif. Les univers narratifs bien connus, comme ceux de Disney, constituent à ce titre des supports particulièrement efficaces. On peut par exemple choisir un film emblématique tel que Cendrillon ou Le Roi Lion, dont les grandes lignes sont immédiatement reconnaissables par la majorité des participants.
Quel que soit le récit retenu, un point demeure essentiel : il doit être connu de l’ensemble du groupe. Cette connaissance commune permet à chacun de se projeter sans effort dans l’histoire et de se concentrer pleinement sur l’exercice proposé. Les participants peuvent alors travailler collectivement sur un fragment du récit, en partageant les mêmes références et en construisant une compréhension commune, condition indispensable à la qualité de l’apprentissage et de la collaboration.
© Source: Introducing Event Storming – Alberto Brandolini
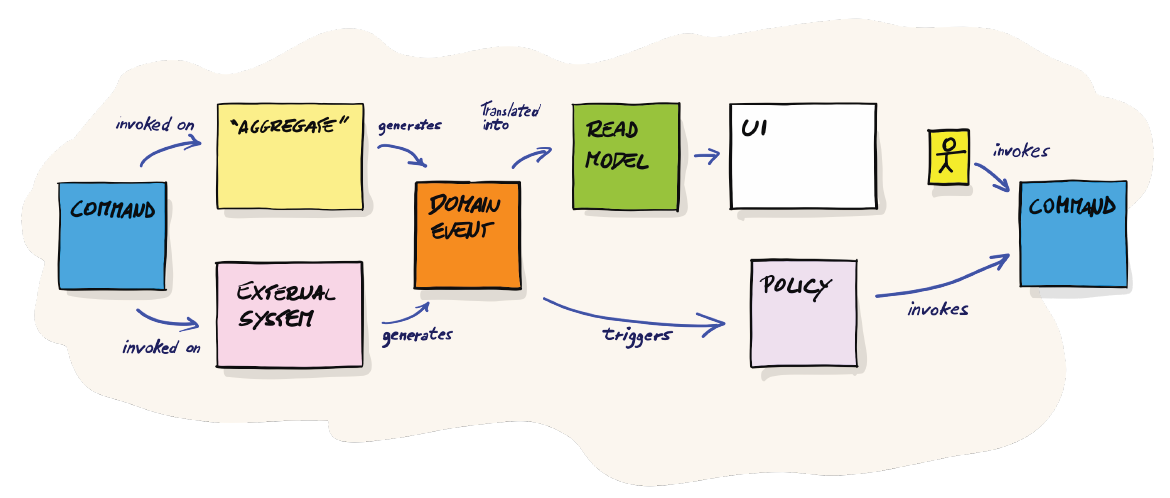
La richesse sémantique des post-its utilisés en EventStorming Software Design peut, à première vue, sembler déroutante. Pourtant, une fois les concepts expliqués, cette grammaire visuelle devient lisible et intuitive. Chaque couleur et chaque forme porte un sens précis, permettant de représenter clairement les interactions, les décisions et les responsabilités au sein du système.
La commande (post-it bleue) représente un ordre ou une action, généralement initiée par un utilisateur. Elle exprime une intention : demander au système d’effectuer quelque chose. Une commande ne peut s’adresser qu’à deux types de cibles : un agrégat (post-it jaune) ou un système externe (post-it rose pale). Bien que leur nature diffère, leur comportement est identique du point de vue du modèle : tous deux reçoivent des commandes et émettent des événements.
Un événement (post-it orange) est un fait avéré, exprimé au passé. Il décrit quelque chose qui s’est produit et qui ne peut plus être remis en cause. Le système externe, comme son nom l’indique, n’est pas sous la responsabilité directe de l’équipe, mais il participe néanmoins à la chorégraphie globale des services ou de l’application dont l’équipe a la charge. À l’inverse, l’agrégat représente le cœur du logiciel que l’équipe doit concevoir, développer et maintenir.
Un événement peut être consommé par deux types d’éléments. Le premier est la Policy (post-violet) qui représente une ou plusieurs règles métier. Une Policy peut être manuelle ou automatique et traduit une décision prise en réaction à un événement. Le second consommateur possible est le Read Model (post-it vert) souvent couplé à l’interface utilisateur (post-it blanc) qui correspond à la partie de lecture et de restitution de l’information. Cette interface peut à son tour permettre à l’utilisateur (petit post-jaune vertical) de déclencher une nouvelle commande.
Enfin, la Policy, en appliquant les règles métier, peut elle-même émettre une nouvelle commande, prolongeant ainsi la chaîne causale du système. Cette dynamique met en évidence la nature événementielle et réactive du modèle, ainsi que la chorégraphie explicite entre intentions, décisions et faits métiers.
Pour mener un atelier de découverte, il est essentiel de réunir les personnes qui composent le Bounded Context, c’est-à-dire l’équipe stream-aligned ainsi que les parties prenantes avec lesquelles elle interagit.
En rendant explicites les règles métier, les flux et les comportements clés, l’atelier permet de réduire l’ambiguïté fonctionnelle. Il allège ainsi la charge cognitive des équipes, condition indispensable pour intervenir de manière sereine et maîtrisée sur un legacy complexe.
Flécher les éléments clefs au sein de son Bounded Context
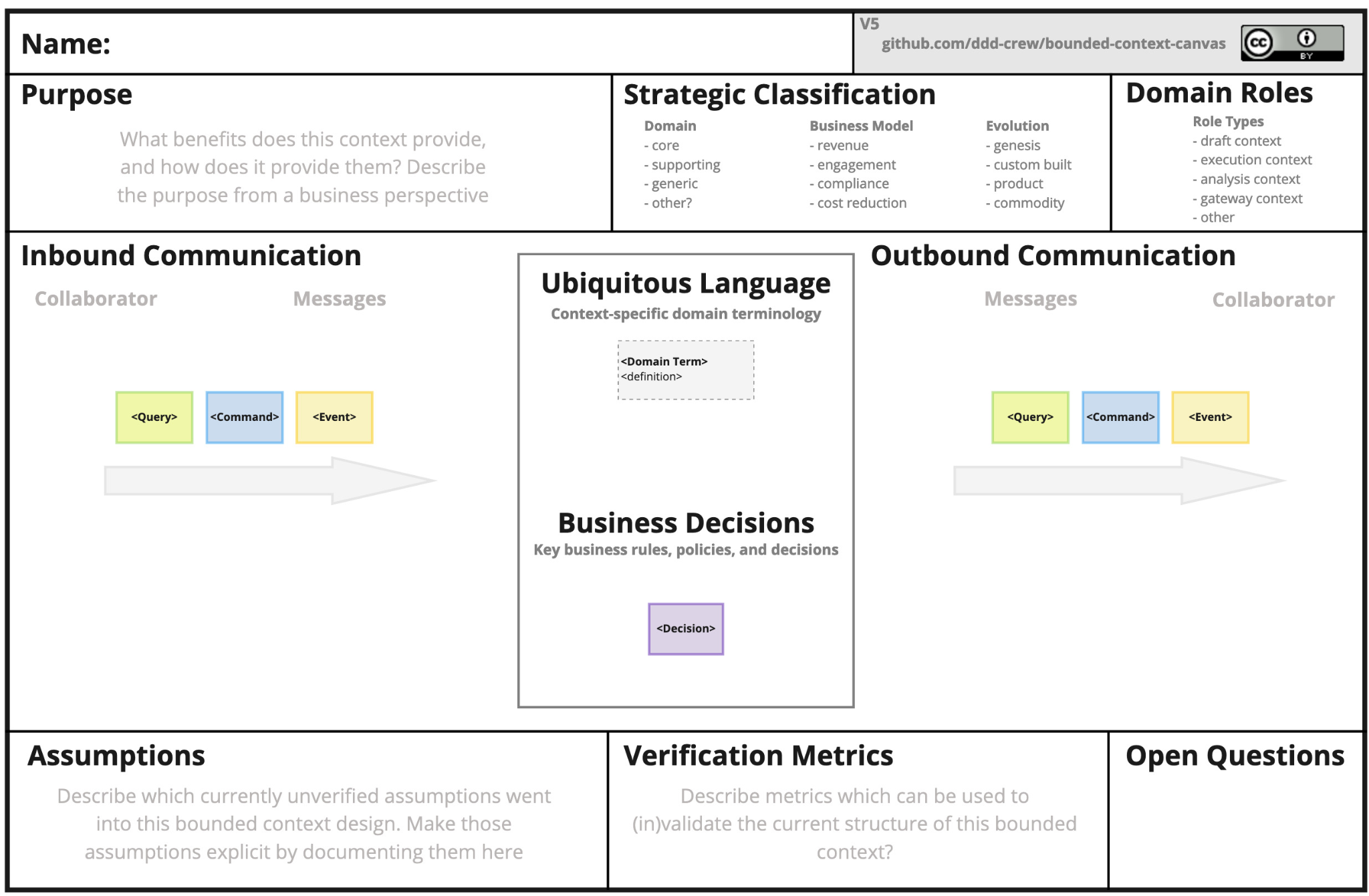
Pour cristalliser les éléments structurants d’un contexte — tels que les messages entrants et sortants, les règles métier ou les responsabilités — le Bounded Context Canvas constitue un outil central du Domain-Driven Design. Il permet de formaliser les frontières d’un Bounded Context, de clarifier son langage métier, d’expliciter sa valeur stratégique et de rendre visibles ses interactions avec les autres contextes. Utilisé dans le prolongement de l’Event Storming, le Canvas aide les équipes à se concentrer sur un périmètre maîtrisable, en cohérence avec les principes de Team Topologies, notamment la réduction de la charge cognitive par équipe.
La première étape consiste à définir le nom et la description du canvas afin de clarifier sa raison d’être et ses principales responsabilités en une ou deux phrases. Cette formulation initiale pose un cadre clair et partagé, servant de point de référence pour l’ensemble des discussions et décisions à venir.
Les différentes sections du canvas peuvent ensuite être complétées dans l’ordre le plus pertinent pour l’équipe. Il est possible d’adopter une approche outside-in, en partant des interactions entrantes et des messages reçus par le contexte, ou au contraire une approche inside-out, en débutant par les règles métier et le langage du domaine.
Il est fréquent que certaines informations nécessaires à la complétion du canvas ne soient pas immédiatement disponibles. Dans ce cas, il est recommandé de recourir à d’autres techniques de modélisation pour faire émerger les éléments manquants. Par exemple, l’atelier Example Mapping, évoqué dans la première partie, permet d’illustrer les règles métier à l’aide d’exemples concrets et de lever des ambiguïtés fonctionnelles.
Les informations capturées dans un Bounded Context Canvas ne doivent cependant pas être considérées comme définitives dès leur première formulation. Elles reposent souvent sur des hypothèses, des interprétations ou une compréhension encore partielle du domaine. Une phase de validation manuelle s’avère donc indispensable pour s’assurer que le modèle reflète fidèlement la réalité métier.
Cette validation est réalisée par des acteurs humains, en particulier les experts du domaine et les parties prenantes concernées. Elle consiste à confronter les concepts, les règles et le langage exprimés dans le canvas à la pratique réelle du métier, afin de révéler d’éventuelles ambiguïtés, incohérences ou simplifications excessives.
La validation manuelle joue ainsi un rôle clé dans l’alignement entre les équipes métiers et techniques. Elle favorise l’émergence d’un langage ubiquitaire partagé et renforce la confiance dans le Bounded Context Canvas en tant qu’outil de conception. Loin d’être une contrainte, cette étape constitue un levier essentiel pour construire des contextes cohérents, autonomes et durablement ancrés dans le domaine.
En mettant en lumière les dépendances et les relations entre contextes, le Bounded Context Canvas alimente le Context Mapping et rend visibles les modes d’interaction entre équipes. Cette visibilité permet d’identifier les couplages excessifs, les responsabilités floues ou les interactions non soutenables, et d’ajuster l’organisation ou les interfaces afin de préserver l’autonomie des équipes.
Avant d’attaquer une montagne de code legacy
Avant tout mouvement de code, la mise en place d’un harnais de tests est indispensable pour sécuriser les évolutions. Cette affirmation peut sembler évidente, mais elle se heurte à une réalité bien connue : un code legacy est, par nature, peu ou pas testable. Autrement dit, il n’a ni été conçu ni modélisé pour l’être.

Souvent ignoré, mais il est parfaitement possible de casser les dépendances sans casser le code
Dans ce contexte, l’écriture de tests sur une base de code legacy est souvent perçue comme impossible. C’est précisément cette croyance qui pousse de nombreuses équipes à envisager la réécriture totale, faute de connaître les techniques permettant d’ouvrir le code sans le casser.
Pourtant, ces techniques existent. Elles ont été formalisées par Michael Feathers dans son ouvrage de référence Working Effectively with Legacy Code.
Ces approches permettent d’introduire des tests là où le code ne les autorise pas a priori, en isolant progressivement les dépendances et en créant des points d’entrée testables. Elles sont donc précieuses non seulement pour sécuriser les évolutions, mais aussi pour découper le code aux bonnes frontières, notamment afin de séparer des périmètres portés par des équipes distinctes.
Les techniques pour casser les dépendances sont la clef technique de la modernisation du code
| Technique pour casser des dépendances | Objectif / Intention |
|---|---|
| Extract Interface | Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d’abstractions (DIP). |
| Extract & Override Call | Supprimer la dépendance externe liée à une méthode statique. |
| Extract & Override Factory Method | Éliminer les initialisations codées en dur présentes dans les constructeurs. |
| Parameterized Constructor | Externaliser l’instanciation d’un champ en introduisant un double constructeur. |
| Break out Method Object | Simplifier les tests des méthodes longues. |
| Adapt Parameter | Utiliser Adapt Parameter lorsqu’il n’est pas possible d’appliquer Extract Interface sur la classe d’un paramètre ou lorsque ce paramètre est difficile à simuler. |
| Introduce Static Setter | Permet de gérer les singletons. |
| Introduce Instance Delegator | Éliminer la dépendance externe liée à une méthode statique. |
Découper le code legacy de son équipe à la frontière des autres équipes
Le véritable enjeu ne réside cependant pas dans l’application mécanique de ces techniques, mais dans la capacité à choisir les bons points de découpe. Ces décisions doivent rester alignées avec les enseignements issus des ateliers d’exploration précédents, EventStorming, Bounded Contexts, Context Mapping, afin d’éviter de recréer, sous une autre forme, les mêmes problèmes de couplage et de complexité.
Les dépendances sont ensuite cassées progressivement, en cohérence avec les frontières organisationnelles et les Team APIs définies entre équipes, ce qui correspond à l’ensemble des services, responsabilités, règles d’interaction et points de contact qu’une équipe expose pour collaborer avec les autres équipes sans dépendance implicite.

Des harnais de tests à différents niveaux, unitaires, d’intégration et d’acceptation, sont indispensables
Une fois des harnais de tests solidement mis en place à différents niveaux, il devient possible d’engager le remaniement du code en toute sécurité.
Il est important de rappeler que, pour écrire les premiers tests, les techniques de cassage de dépendances sont indispensables, car tout code legacy n’a pas été conçu pour être testable.
Cette première étape peut durer trois à quatre semaines sur les monolithes les plus complexes.
La première caractéristique d’un code legacy est souvent… l’absence de structure. À l’image d’une maison sans fenêtres ni pièces clairement définies, tout y est plat, impératif et difficile à appréhender. Les concepts métier s’y trouvent mêlés au code d’infrastructure, comme des requêtes SQL dynamiques, des accès réseau, de la logique technique, formant un ensemble confus où rien ne semble véritablement à sa place.
L’autonomie du Bounded Context passe aussi par le découplage des tables
La modernisation ne concerne pas uniquement le code applicatif : la base de données en est souvent l’un des principaux points de couplage. Lorsque plusieurs applications ou composants partagent les mêmes tables, toute évolution devient risquée : une modification locale peut avoir des effets de bord imprévisibles ailleurs dans le système.
Une analyse des tables et des procédures stockées existantes permet d’identifier ces dépendances implicites, souvent invisibles dans le code, et de comprendre comment elles entravent l’évolution du système. Le découplage progressif des structures de données vise alors à limiter ces impacts en cascade, à réduire la fragilité globale et à sécuriser les changements.
En redonnant à chaque partie du système la maîtrise de ses données, on diminue les risques, on clarifie les responsabilités et on crée les conditions nécessaires à une véritable autonomie des équipes.
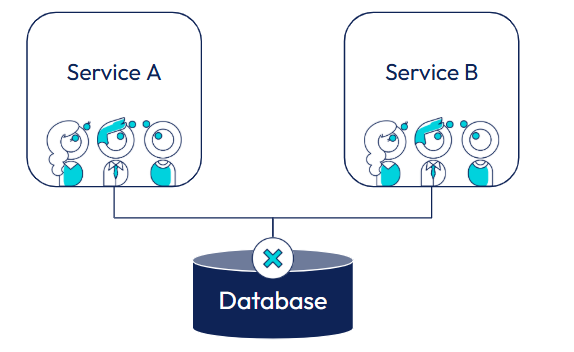
L’indépendance des données font partie de l’autonomie, ce cas précis à l’origine du concept Bounded Context
Pour illustrer le problème, imaginons deux équipes : la première est responsable du service A, la seconde du service B. Par manque de communication et de visibilité, les deux équipes utilisent, sans le savoir, des tables communes, chacune pour alimenter ses propres objets métier.
Dans ce contexte, lorsqu’un changement est introduit par l’équipe du service A, celui-ci peut indirectement modifier ces tables partagées et provoquer un dysfonctionnement, voire un crash, du service B. L’inverse est tout aussi vrai : selon le service qui initie la première mise à jour, c’est l’autre qui subit les effets de bord.
Ce type de couplage par la base de données crée une dépendance invisible entre équipes, rend les systèmes fragiles et transforme chaque déploiement en prise de risque, freinant ainsi l’autonomie et la capacité d’évolution de l’ensemble.
Pour la petite histoire, l’origine du concept de Bounded Context trouve sa source dans un problème très concret de partage de tables de base de données entre deux équipes. Cette situation, fréquente dans les organisations, a mis en évidence les limites d’un modèle partagé sans frontières claires.
Lors de la mise en production d’une application sur laquelle intervenait une équipe accompagnée par Eric Evans, créateur du Domain-Driven Design, des comportements inattendus sont apparus. Les valeurs affichées à l’écran étaient incohérentes, ne correspondaient pas aux attentes métier et révélaient des interprétations divergentes des mêmes données.
Finalement, ces incohérences ont conduit à un crash de l’application en production. Cet incident a servi de déclencheur à une réflexion plus profonde sur la nécessité de définir des frontières explicites entre les modèles, les langages et les responsabilités des équipes. C’est dans ce contexte qu’a émergé le concept de Bounded Context, comme réponse structurante aux problèmes de couplage excessif et de confusion sémantique.
Urbaniser le code afin retourner de la clarté
À mesure que le système évolue, le code s’enrichit progressivement du vocabulaire métier. Les responsabilités sont déplacées au bon endroit, les bases de données sont découplées et une architecture plus souple émerge presque naturellement. Cette approche permet aux équipes de livrer en continu sans dépasser leur capacité cognitive, condition indispensable à une modernisation durable du legacy.
L’objectif du remaniement est alors de réorganiser ces éléments afin de leur redonner du sens. J’utilise souvent la métaphore des cartons de déménagement pour illustrer cette étape : les déménageurs ont déposé tous les cartons dans l’entrée, et il reste désormais à les placer dans les bonnes pièces. Déplacer un carton — une fonction ou une responsabilité — dans la bonne pièce — une classe ou un composant — résume assez bien l’activité quotidienne du refactoring.

Métaphore du déménagement - réorganisation du code legacy
Cependant, dans le cadre d’un remaniement de grande ampleur, les pièces n’existent pas encore. Il est nécessaire de les créer progressivement, au fil de l’eau, afin de retrouver une cohérence et une consistance fonctionnelle. C’est précisément dans cette phase que l’EventStorming Software Design devient une source d’information précieuse : il fournit les repères métier indispensables pour structurer le code autour des bons concepts, plutôt que selon des considérations purement techniques.
Dans cette phase particulièrement intense sur le plan du design, la présence d’un ou de plusieurs experts métier est essentielle. Il est également important de disposer d’un tableau blanc à proximité de l’équipe — ou d’un tableau numérique — afin de travailler à partir d’exemples concrets et de partager collectivement les décisions. Ce support visuel permet au Bounded Context de mieux comprendre comment, sur le plan technique, l’équipe de développement va pouvoir implémenter ou restructurer le code de manière cohérente et alignée avec les besoins métier.
Naissance du vocable commun entre les experts métier et l’équipe de développement
L'ensemble de ces échanges avec le métier contribue progressivement à l’appropriation d’un vocabulaire commun, profondément ancré dans les modèles mentaux de l’équipe. Au fil des discussions, les termes métier ne sont plus seulement compris, mais intégrés et utilisés naturellement dans les échanges quotidiens et dans le code.
Après quelques semaines, le vocabulaire de l’équipe s’enrichit de manière visible, au point que les experts métier eux-mêmes peuvent en constater l’évolution. Les incompréhensions diminuent, les discussions gagnent en précision, et le langage devient un véritable outil de collaboration plutôt qu’un obstacle.
Après quelques mois de travail conjoint, une nouvelle étape est franchie : ce sont désormais les membres de l’équipe qui proposent au métier de nouvelles métaphores et de nouvelles formulations. Le langage ubiquitaire n’est plus seulement adopté, il devient vivant, co-construit, et participe activement à l’affinement de la compréhension du domaine.
Retour sur la notion de Bounded Context
Dans la première partie, nous avons présenté le concept de Bounded Context sans mentionner l’axe code, qui fait partie intégrante du concept. Le code et le livrable font partie intégrante du Bounded Context.
Dans un contexte où la complexité métier est forte, les compétences des développeurs dépassent la simple pratique du Test-Driven Development. Elles s’inscrivent dans une démarche plus exigeante de refactoring orienté métier, visant à renforcer l’expressivité du code afin qu’il incarne avec justesse la logique du domaine.
L’objectif est de rendre lisible et compréhensible, y compris par des acteurs non informaticiens. Le code devient alors un véritable support d’expression du métier, dans lequel les concepts, les règles et les intentions sont explicites et porteurs de sens.
Les narratives issues des conversations avec le métier doivent ainsi se refléter directement dans le code. Les échanges, les questionnements et les clarifications alimentent la modélisation et se traduisent en structures, en noms et en comportements cohérents.
Cette approche, souvent désignée sous le nom de Deep Modeling en Domain-Driven Design, favorise une collaboration continue entre le métier et l’équipe de développement, y compris pendant la phase de développement. Le code devient alors un lieu de dialogue, d’apprentissage partagé et de clarification progressive du domaine.
Par nature, le Bounded Context offre précisément cet espace de modélisation approfondie. Il permet de se concentrer sur un périmètre métier cohérent, à l’abri de la « pollution sonore » générée par d’autres problématiques ou par les préoccupations d’autres équipes.
Le Bounded Context privilégie ainsi la compréhension du métier à travers des conversations structurées et un code incarnant le domaine. Ce code est directement inspiré par le langage ubiquitaire propre au périmètre concerné, renforçant l’alignement entre le modèle, les échanges métier et l’implémentation logicielle.
Muscler le code avec le vocabulaire métier

Muscler le code en incarnant le métier et pratiquer le Supple Design
Vous pourriez être surpris par l’idée de « muscler » le code. Cette métaphore prend tout son sens lorsqu’on l’oppose à celle d’un code anémique, pauvre en intentions et difficile à comprendre. L’objectif est de produire un code qui révèle clairement la nature fonctionnelle qu’il représente. Autrement dit, un code suffisamment expressif pour être compris par un expert métier, même s’il ne sait pas programmer.
Pour qu’un code puisse être lu comme une histoire métier, il doit d’abord s’ancrer dans un langage partagé au sein de l’équipe. Ce langage ne naît pas spontanément dans les classes et les méthodes : il se construit collectivement, en rendant visibles les mots du métier sur un tableau, un mur ou tout autre support accessible à tous. Dans le Domain-Driven Design, ce vocabulaire commun est appelé le langage ubiquitaire.
À mesure que les membres de l’équipe s’approprient ce langage, une transformation progressive s’opère. Le code cesse peu à peu de s’exprimer uniquement à travers des primitives techniques, string, int, float, list, et commence à parler le langage du domaine. De petits objets apparaissent, chacun incarnant une notion métier précise et portant une intention claire.
cet apprentissage continu, le modèle se densifie. Le code gagne en force et en précision, non par une complexité accrue, mais par une meilleure expressivité. Il devient alors possible de parcourir le code comme on lirait un récit fonctionnel : sans effort de traduction, sans ambiguïté et, idéalement, sans qu’il soit nécessaire d’être informaticien pour en saisir le sens. Dans le Domain-Driven Design, cette activité est particulièrement importante, elle porte le nom de Supple Design.
Supple Design Quesaco ?
Le Supple Design repose sur une collaboration étroite entre les experts du domaine et l’équipe de développement. Cette collaboration vise à nommer avec précision et à définir le contour des classes métier afin de représenter fidèlement les concepts du domaine. Pour y parvenir, le langage ubiquitaire devient la langue première de communication, aussi bien dans les échanges que dans le code.
Rendre le code souple et expressif nécessite un espace de travail qui favorise l’exploration du métier. Chaque détail est analysé, questionné et affiné avec rigueur, sans rien tenir pour acquis, dans un cadre respectueux et sain. Cette exigence propre au Supple Design permet d’approfondir la compréhension du domaine et d’éviter les simplifications trompeuses.
Cette démarche éclaire également la notion de Bounded Context. Celui-ci ne se réduit pas à un découpage technique, mais constitue un choix stratégique fondé sur le sens et la cohérence du métier. La modélisation devient alors un outil de clarification des frontières conceptuelles du domaine.
Il ne s’agit donc pas simplement d’une équipe de développement, mais d’un véritable espace de co-construction avec les experts métier. Le langage ubiquitaire, construit pas à pas, devient le socle d’un modèle conceptuel capable d’embrasser la complexité du domaine tout en maintenant un alignement durable entre tous les acteurs.
Enfin, une modélisation pérenne suppose un environnement bienveillant et un code de grande qualité. Un nommage précis, un design cohérent et des structures claires transforment le code en un miroir du domaine, renforçant et éclairant les choix de modélisation.
Ces patterns privilégient une définition précise des responsabilités, encouragent l’indépendance des classes et favorisent leur immuabilité. L’objectif est de construire une structure de code souple mais solide, capable de s’adapter sans fragiliser l’ensemble du système.
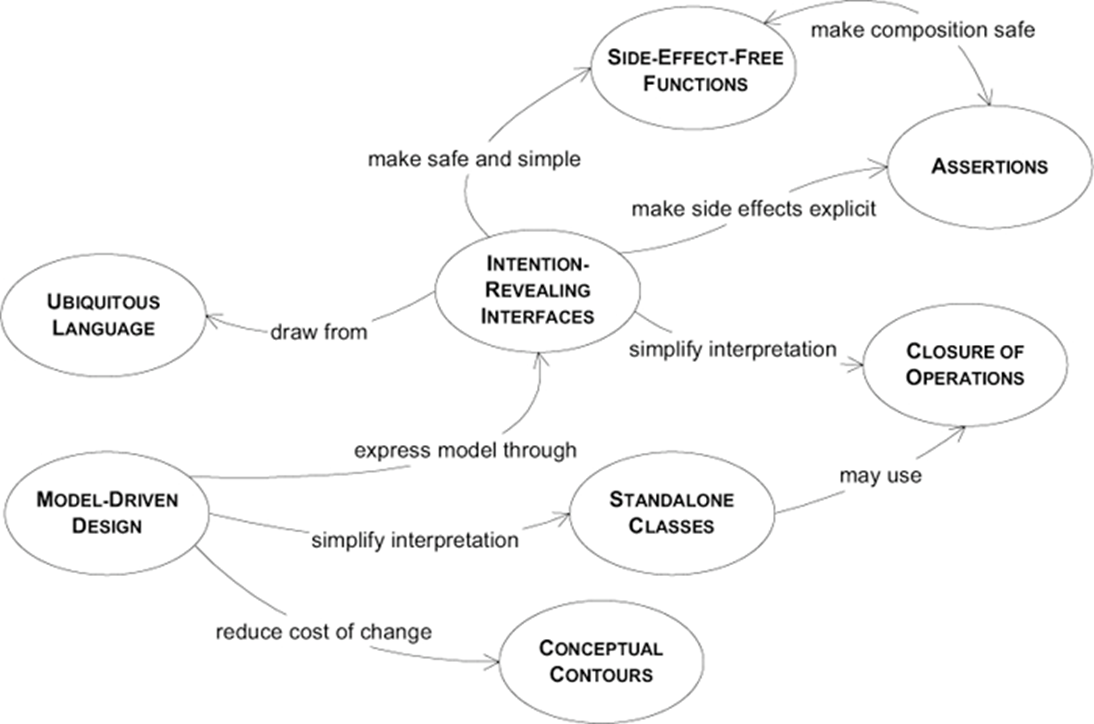
La cartographie des patterns du supple design - Eric Evans
Les interfaces à intention explicite (Intention-Revealing Interfaces) rendent le code compréhensible sans exposer l’implémentation. En s’appuyant sur le langage ubiquitaire et en concevant les API du point de vue de leurs utilisateurs, elles renforcent la lisibilité, la cohérence et l’alignement avec le métier.
Les fonctions sans effets de bord (Side-Effect-Free Functions) permettent de construire un code prédictible et testable en séparant clairement calcul et modification d’état. L’usage d’objets-valeurs immuables concentre la logique métier et limite les effets inattendus.
Les contours conceptuels (Conceptual Contours) structurent le design autour des concepts stables du domaine. Un découpage aligné sur le métier évite à la fois la fragmentation excessive et les abstractions confuses, réduisant ainsi la complexité accidentelle.
Les assertions rendent explicites les contrats et invariants métiers qui gouvernent le comportement du système. En formulant clairement ce qui doit toujours être vrai, elles matérialisent les règles essentielles du domaine directement dans le code. Combinées aux tests automatisés, les assertions contribuent à clarifier les responsabilités, à sécuriser les comportements attendus et à prévenir l’apparition d’effets de bord implicites, renforçant ainsi la fiabilité et la compréhension du modèle métier.
Les classes autonomes (Standalone Classes) cherchent à minimiser les dépendances afin de réduire la charge cognitive. En limitant leurs interactions avec le reste du système, elles concentrent la complexité là où elle a du sens : dans le métier qu’elles expriment. Faiblement couplées, ces classes sont plus faciles à comprendre, à tester et à faire évoluer. Elles favorisent un design plus modulaire, renforcent l’isolation des responsabilités et contribuent à la stabilité globale du modèle dans le temps.
La fermeture des opérations (Closure of Operations), en particulier appliquée aux objets-valeurs, introduit une forme d’immutabilité selon laquelle toute demande de modification ne transforme pas l’instance existante. Elle conduit plutôt à la création d’une nouvelle instance intégrant le changement requis, préservant ainsi l’intégrité et la cohérence du modèle.
Le design déclaratif traite le code comme une spécification explicite du comportement métier, en combinant interfaces claires, fonctions pures, assertions et modularité, afin de produire des modèles lisibles, robustes et durables. Inscrit dans une sphère métier précise, le design déclaratif vise à rendre les opérations d’usage fluides et hautement expressives. Les interactions avec le modèle traduisent directement les intentions métier, en minimisant le bruit technique et en renforçant la clarté du langage du domaine.
Séparer le code infrastructure du code métier
Une fois une cohérence fonctionnelle retrouvée, il devient essentiel de séparer clairement le code métier du code d’infrastructure. Cette distinction ne relève pas uniquement d’un choix architectural, mais constitue un levier fondamental pour améliorer la lisibilité du système, renforcer sa testabilité et faciliter son évolution dans le temps. En isolant les règles métier, on préserve leur stabilité face aux changements technologiques et organisationnels.
L’expérience montre cependant que l’architecture en couches traditionnelle ne garantit pas, à elle seule, une véritable étanchéité entre les couches. Si cette approche propose une séparation conceptuelle claire, elle ne fournit pas de mécanisme fort pour empêcher les dépendances indésirables. Les règles d’usage sont souvent implicites et reposent sur la discipline des équipes plutôt que sur la structure du code.
Après quelques mois, et à la suite d’interventions malheureuses ou de contraintes projet mal maîtrisées, la couche métier finit fréquemment par être polluée par la couche graphique. Des préoccupations liées à l’affichage, à la navigation ou aux formats d’échange se retrouvent alors mêlées aux règles métier, affaiblissant leur lisibilité et leur réutilisabilité.
De la même manière, la couche de persistance tend elle aussi à transpirer dans le métier. Des concepts techniques liés aux bases de données, aux frameworks ORM ou aux modèles de stockage influencent progressivement la modélisation métier, jusqu’à en altérer le sens. Le modèle devient alors dépendant de choix techniques, perdant sa capacité à exprimer clairement le domaine et à évoluer indépendamment de l’infrastructure.
L’arrivée du pattern Ports & Adapters, également connu sous le nom d’architecture hexagonale, a profondément bouleversé la manière d’organiser les logiciels. Proposé en 2005 par Alistair Cockburn, co-signataire du Manifeste Agile, ce modèle architectural répond précisément à la nécessité de mieux protéger le cœur métier des influences techniques et des choix d’infrastructure.
Le principe fondamental de cette architecture consiste à découpler explicitement le cœur métier des détails techniques. Pour cela, les comportements du domaine sont exposés au travers de ports, définis par l’application elle-même. Ces ports décrivent ce que le système sait faire ou ce dont il a besoin, en utilisant le vocabulaire du métier, et sont exprimés sous forme d’interfaces. Ils constituent ainsi des frontières claires et stables autour de la logique métier.
Les adapters viennent ensuite implémenter ces ports afin de connecter l’application au monde extérieur. Ils encapsulent l’ensemble des préoccupations d’infrastructure comme les bases de données, les systèmes externes, les interfaces utilisateur ou les frameworks techniques — sans jamais les faire transparaître dans le cœur du domaine. Cette organisation garantit que la logique métier reste indépendante, testable et évolutive, tout en permettant de faire évoluer ou remplacer les technologies périphériques sans remettre en cause le modèle métier.
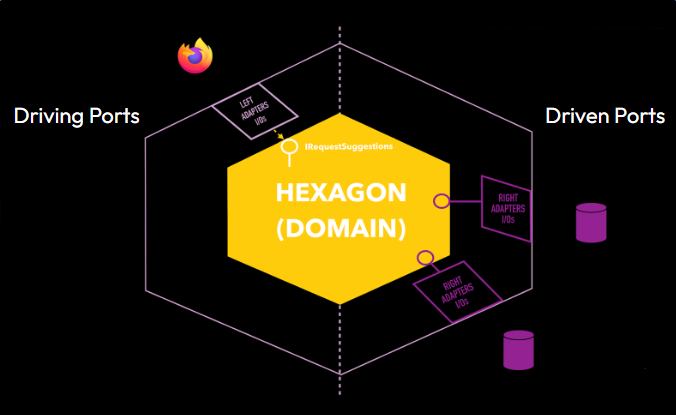
L’architecture Hexagonale ou Pattern Ports & Adapters
Pourquoi les ports sont-ils orientés en Driving Ports et Driven Ports ?
En architecture hexagonale, l’orientation des ports n’est pas un détail de vocabulaire, mais une manière explicite de rendre visible le sens des dépendances. Cette distinction permet d’indiquer clairement qui initie une interaction et qui la subit, tout en garantissant que le cœur applicatif reste maître de ses frontières. Les ports sont toujours définis par l’application, mais leur orientation précise le rôle qu’ils jouent dans les échanges avec l’extérieur.
Les données entrantes arrivent par le côté gauche du schéma via les ports entrants (Driving Ports), tandis que les données sortantes apparaissent sur le côté droit via les ports sortants (Driven Ports).
Les Driving Ports, ou ports entrants, représentent ce que l’application sait faire. Ils décrivent les capacités offertes par le système sous la forme de cas d’usage ou de services applicatifs. Ces ports constituent les points d’entrée vers la logique métier et sont exprimés dans le langage du domaine. Les adaptateurs entrants (contrôleurs HTTP, consommateurs de messages, interfaces utilisateur, tests) utilisent ces ports pour piloter l’application, sans jamais accéder directement au cœur métier. Ainsi, l’application contrôle son API fonctionnelle et empêche les choix techniques de façonner le modèle métier.
Les Driven Ports, ou ports sortants, représentent ce dont l’application a besoin pour fonctionner. Ils expriment les dépendances nécessaires à l’exécution des cas d’usage, comme la persistance des données, l’envoi de messages ou l’appel à des services externes. Ces ports sont également définis par l’application, mais ils sont implémentés par des adaptateurs sortants relevant de l’infrastructure. Grâce à cette orientation, le cœur métier dépend uniquement d’abstractions et reste indépendant des technologies concrètes utilisées pour satisfaire ces besoins.
En distinguant clairement ports entrants et ports sortants, l’architecture hexagonale garantit que toutes les dépendances pointent vers l’intérieur. Le cœur applicatif expose ce qu’il fait et déclare ce dont il a besoin, sans jamais dépendre directement du monde extérieur. Cette orientation renforce la testabilité, la maintenabilité et l’évolutivité du système, tout en préservant l’intégrité du modèle métier.
Ce découplage protège le modèle métier des choix technologiques et rend le code plus facile à tester, à faire évoluer et à maintenir dans le temps. Le pattern Ports & Adapters est aujourd’hui plus largement connu sous le nom d’Architecture Hexagonale, une approche qui s’inscrit naturellement dans une démarche de Domain-Driven Design et de modernisation durable des systèmes legacy.
Préparer les équipes de développement à modernisation du code
Même si l’IA générative apporte une valeur indéniable, il est essentiel de rappeler que les décisions finales relèvent toujours de la responsabilité des développeurs. L’IA peut assister, accélérer et proposer des solutions, mais elle ne doit en aucun cas se substituer au jugement humain, en particulier sur des sujets structurants comme l’architecture ou la modélisation du domaine.
Il est donc indispensable de renforcer et d’entretenir la maîtrise des fondamentaux du développement afin de produire un code propre, lisible et maintenable. Plusieurs travaux montrent d’ailleurs qu’une délégation excessive à l’IA peut avoir des effets négatifs sur les capacités cognitives, en affaiblissant la compréhension et la capacité d’analyse des développeurs: (PDF) Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task
L’enjeu consiste à trouver un juste équilibre entre assistance et contrôle. Les pratiques essentielles telles que le Test-Driven Development, le refactoring continu ou le cassage de dépendances doivent rester pleinement maîtrisées par les équipes. Elles constituent le socle technique qui permet de reprendre, corriger et faire évoluer sans difficulté du code généré ou partiellement produit par l’IA.
Cette exigence de discipline s’apparente à celle d’un sportif qui entretient ses gestes fondamentaux par un entraînement régulier. De la même manière, les développeurs peuvent s’entraîner plusieurs fois par semaine, sans recourir à des agents d’IA, en pratiquant des code katas sur des thématiques variées afin de renforcer leurs réflexes techniques et leur capacité de raisonnement.
Cette démarche constitue également une réponse pertinente pour les jeunes développeurs qui doivent entrer sur un marché profondément bouleversé par l’IA générative. En consolidant leurs fondamentaux, ils développent une autonomie et une compréhension du code qui restent indispensables, indépendamment des outils disponibles.
En conservant cette maîtrise, les développeurs demeurent aux commandes de l’évolution du système et évitent de se laisser porter par une IA qui, malgré ses performances, reste faillible.
Synthèse de la seconde partie
Un système devient legacy lorsqu’il n’est plus compris, structuré ni évolutif. La dette technique, la perte de connaissance et des organisations inadaptées figent l’architecture, tandis que les réécritures complètes échouent souvent en ignorant les causes humaines et organisationnelles (loi de Conway). Une modernisation durable repose donc sur l’alignement entre organisation, compréhension métier et architecture, et s’engage concrètement au cœur du code.
Cette modernisation doit être progressive, sécurisée et portée par les équipes. L’EventStorming (Big Picture puis Software Design) permet de découper le domaine, clarifier le périmètre et rendre explicites intentions, règles et flux métier, réduisant la charge cognitive. Le Bounded Context Canvas formalise ensuite frontières, langage, responsabilités et interactions, à valider avec les experts métier, et alimente le Context Mapping pour préserver l’autonomie des équipes.
Sur le plan technique, la mise en place de harnais de tests est indispensable. Les techniques de cassage de dépendances (Feathers) rendent le legacy testable, sécurisent les changements et permettent un découpage aux bonnes frontières (Team APIs). L’autonomie passe aussi par la maîtrise des données : le découplage des tables élimine des dépendances invisibles et réduit les risques.
Le refactoring vise à urbaniser le code : réorganiser progressivement responsabilités et concepts autour du vocabulaire métier, avec l’appui des experts. Un langage ubiquitaire émerge et s’enrichit, faisant du code un support d’expression du métier. Cette démarche de Deep Modeling et de Supple Design produit un code expressif, lisible et durable, fondé sur des patterns clés (interfaces à intention explicite, fonctions sans effets de bord, assertions, classes autonomes, immutabilité).
Enfin, la séparation stricte du métier et de l’infrastructure est assurée par l’architecture hexagonale (Ports & Adapters), qui protège le cœur métier des choix techniques et facilite tests et évolutions. Malgré l’apport de l’IA, la maîtrise des fondamentaux (TDD, refactoring, découplage) reste essentielle pour garantir la qualité et la pérennité du système.